Arm Unveils Compute Subsystems and New Core Architecture for AI Workloads
Arm has introduced updated compute subsystems, new processor cores, and specialized software libraries designed to accelerate artificial intelligence and graphics processing. These hardware and software advancements aim to deliver substantial performance gains while reducing power consumption across next-generation client devices.
The semiconductor industry has long watched Arm Holdings evolve from a niche embedded processor designer into a foundational pillar of modern computing. By expanding its licensing model beyond mobile devices, the company has steadily encroached upon markets traditionally dominated by x86 architecture. Recent announcements regarding next-generation hardware and compute frameworks signal a deliberate push to redefine how artificial intelligence workloads are processed across client devices. This strategic expansion reflects broader shifts in how silicon is engineered for efficiency and scalability.
What is the Significance of Arm’s New Compute Subsystems?
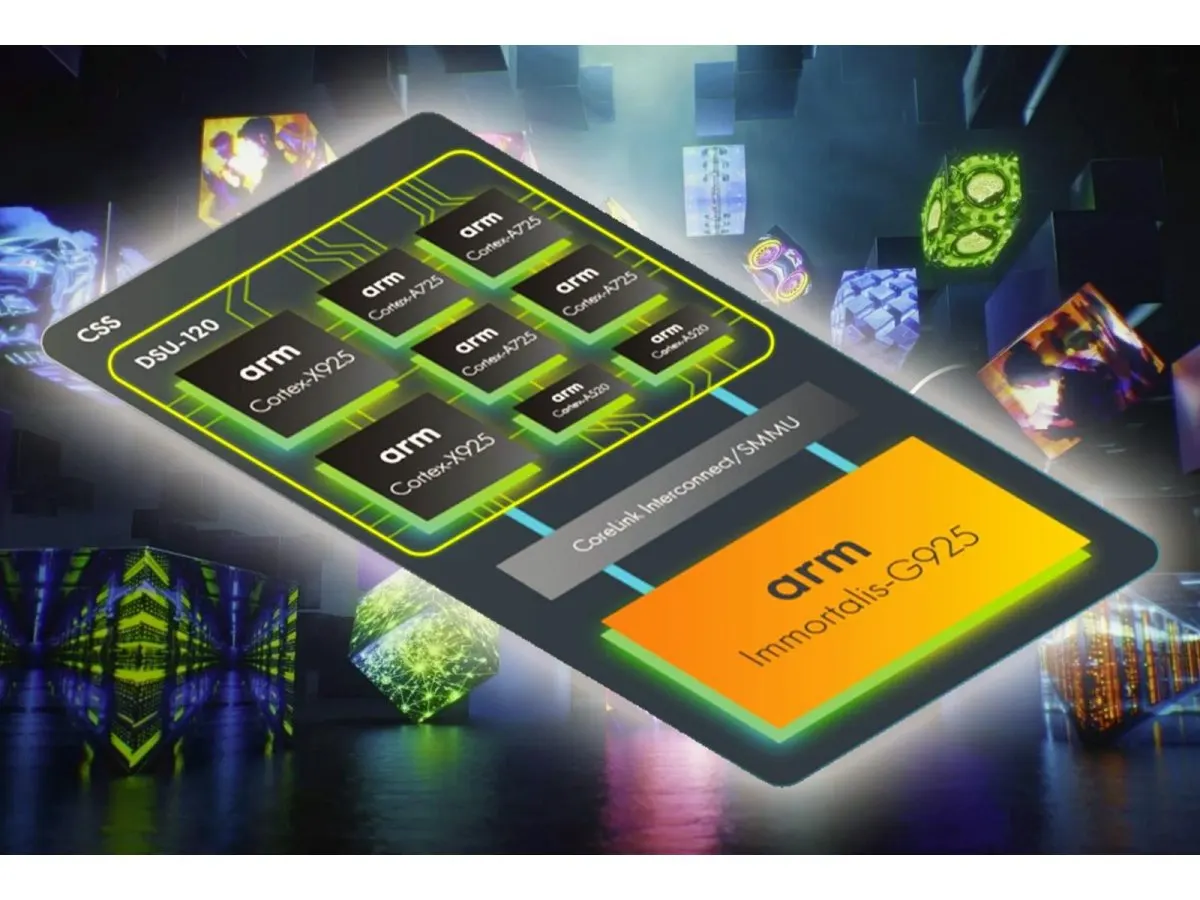
The company has officially extended its Compute Subsystems architecture to client devices, a strategic shift originally developed for server environments. This framework operates similarly to modular building blocks, allowing third-party manufacturers to assemble custom system-on-chip designs. By licensing these integrated components, hardware makers can bypass the immense complexity of designing individual silicon blocks from scratch. The approach mirrors established foundry services, emphasizing modularity and rapid development cycles.
This structural evolution addresses the growing demand for specialized processing capabilities in consumer electronics. Mobile chipmakers and laptop manufacturers require adaptable architectures that can scale across different performance tiers. The subsystem model provides standardized interfaces for memory controllers, interconnects, and power management units. Such standardization reduces development costs and accelerates time-to-market for new generations of smartphones, tablets, and ultrabooks.
The broader industry context reveals a clear transition toward hardware specialization. As applications grow more complex, generic processor designs struggle to maintain optimal performance per watt. Modular subsystems allow engineers to mix and match proven components tailored to specific workloads. This strategy also strengthens the company position in an increasingly competitive licensing landscape where intellectual property flexibility drives innovation.
The licensing model fundamentally separates intellectual property creation from physical manufacturing. This division of labor allows Arm to focus exclusively on architectural innovation while partner foundries manage fabrication complexities. Such a structure encourages rapid iteration and reduces the financial risk associated with developing entirely new processor microarchitectures from the ground up.
Industry observers note that this modular approach aligns with broader trends in semiconductor design automation. As transistors shrink and design rules become more restrictive, standardized interfaces become increasingly valuable. Hardware vendors can combine proven subsystem components to create differentiated products without reinventing fundamental architectural patterns.
How Does the Updated Instruction Set Architecture Improve AI Performance?
The latest instruction set architecture update introduces targeted extensions designed to accelerate machine learning tasks. These architectural modifications expand vector processing capabilities and increase instruction decode width, enabling processors to handle complex mathematical operations more efficiently. Developers can now compile code that directly leverages these hardware features for faster neural network inference. The changes align closely with the growing reliance on on-device artificial intelligence.
Software optimization plays an equally critical role in realizing these hardware benefits. The newly introduced compute library provides highly optimized routines specifically engineered for Arm processors across multiple architectural generations. This framework offers developers a unified interface for accelerating mathematical computations without rewriting core algorithms. It functions as a foundational layer that bridges raw silicon capabilities with application-level demands.
Specialized branches of this library further enhance domain-specific performance. One variant focuses exclusively on generative artificial intelligence, delivering optimized low-level intrinsics for modern inference frameworks. Another branch targets computer vision tasks, claiming substantial speed improvements over standard OpenCV implementations. These dedicated toolkits ensure that developers can extract maximum throughput from the underlying silicon without sacrificing compatibility.
Security enhancements embedded within the instruction set also warrant attention. The updated architecture introduces hardware-enforced isolation mechanisms that protect sensitive data during machine learning operations. These features prevent unauthorized memory access and mitigate potential vulnerabilities in third-party inference engines. Strengthening the security foundation ensures that confidential processing remains viable on consumer hardware. Recent policy developments highlight the growing importance of safeguarding AI workloads as device manufacturers adopt these processing capabilities.
What Hardware Changes Define the Latest Processor Generations?
The performance trajectory of the upcoming processor cores reflects significant architectural refinements. The new high-performance core family claims a substantial single-threaded performance uplift compared to previous premium mobile devices. This improvement stems from expanded execution pipelines, enhanced branch prediction, and more aggressive scheduling mechanisms. The company notes that this represents the largest incremental gain in the history of its premium core lineage.
Cache architecture has also been substantially reimagined to support modern computational demands. Each high-performance core can now accommodate up to three megabytes of level two cache, a notable expansion in a domain where silicon real estate is heavily contested. Larger caches reduce memory latency and allow the processor to keep frequently accessed data closer to the execution units. This design choice prioritizes sustained throughput over raw clock speed.
Graphics processing capabilities have received parallel attention through a new dedicated graphics core family. The updated silicon builds upon previous generations by increasing core counts and refining the rendering pipeline. Performance benchmarks indicate substantial improvements in gaming workloads, artificial intelligence rendering, and ray tracing calculations. These gains result from a combination of architectural tweaks and advanced manufacturing processes that improve transistor density.
The graphics architecture introduces refined scheduling algorithms that prioritize latency-sensitive rendering tasks. By dynamically allocating compute resources to active draw calls, the silicon minimizes frame delivery delays. This approach improves responsiveness in complex gaming environments where visual fidelity and performance must coexist.
Manufacturing advancements play a crucial role in achieving these graphics improvements. Advanced lithography techniques enable tighter transistor packing and reduced switching capacitance. These physical changes allow the graphics core to maintain higher clock speeds while operating within strict thermal boundaries typical of mobile platforms.
Why Do the Performance and Efficiency Gains Matter for Device Manufacturers?
Power management remains a critical constraint for mobile and portable computing platforms. The latest platform updates deliver measurable reductions in graphics processing power consumption while improving overall system efficiency. Lower energy requirements directly translate to longer battery life and reduced thermal output within compact chassis designs. These efficiency improvements allow manufacturers to maintain thin form factors without compromising sustained performance.
The transition to advanced fabrication processes underpins many of these hardware advancements. Production-ready implementations are slated for next-generation nodes that offer superior transistor switching characteristics. Smaller geometries reduce leakage current and allow higher switching frequencies within the same power envelope. This manufacturing shift amplifies the benefits of architectural improvements, creating a compounding effect on overall system performance.
Real-world application performance benefits directly from these underlying silicon changes. Browsing workloads and gaming experiences are expected to see noticeable responsiveness improvements. Media playback tasks also demonstrate efficiency gains, with specific streaming applications requiring less energy to maintain playback quality. These incremental optimizations accumulate to create a more responsive and reliable user experience across diverse daily tasks.
Thermal management strategies directly influence sustained performance in compact devices. Lower power consumption reduces the burden on cooling solutions, allowing manufacturers to prioritize internal volume for batteries or additional components. Efficient silicon design ultimately dictates how much computational workload a device can sustain before reaching thermal throttling thresholds.
The commercial implications extend beyond individual device specifications. Chipmakers leveraging these subsystems can differentiate their product portfolios through specialized performance characteristics rather than competing solely on raw clock speeds. This shift encourages innovation in system-level optimization and encourages healthier long-term competition within the mobile processor market.
Industry Outlook and Hardware Adoption
The semiconductor landscape continues to shift toward specialized architectures that prioritize efficiency alongside raw computational power. By expanding its modular subsystem approach and refining core designs, the company positions its licensing ecosystem to meet escalating demands from mobile and client device manufacturers. The integration of updated instruction sets and specialized software libraries further bridges the gap between hardware capabilities and application requirements. As third-party chipmakers adopt these new frameworks, the industry will likely see accelerated innovation in artificial intelligence processing and graphics rendering.
The success of these initiatives will ultimately depend on how seamlessly licensees integrate the technology into their next-generation product lines. Manufacturers must carefully balance performance targets with thermal constraints to deliver viable consumer products. The broader implications extend beyond mobile computing, as efficient processor designs increasingly influence server infrastructure and embedded systems worldwide. Industry stakeholders will continue monitoring adoption rates to gauge long-term market direction.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)