Google Expands Conversational AI Across Gmail, Docs, and Keep
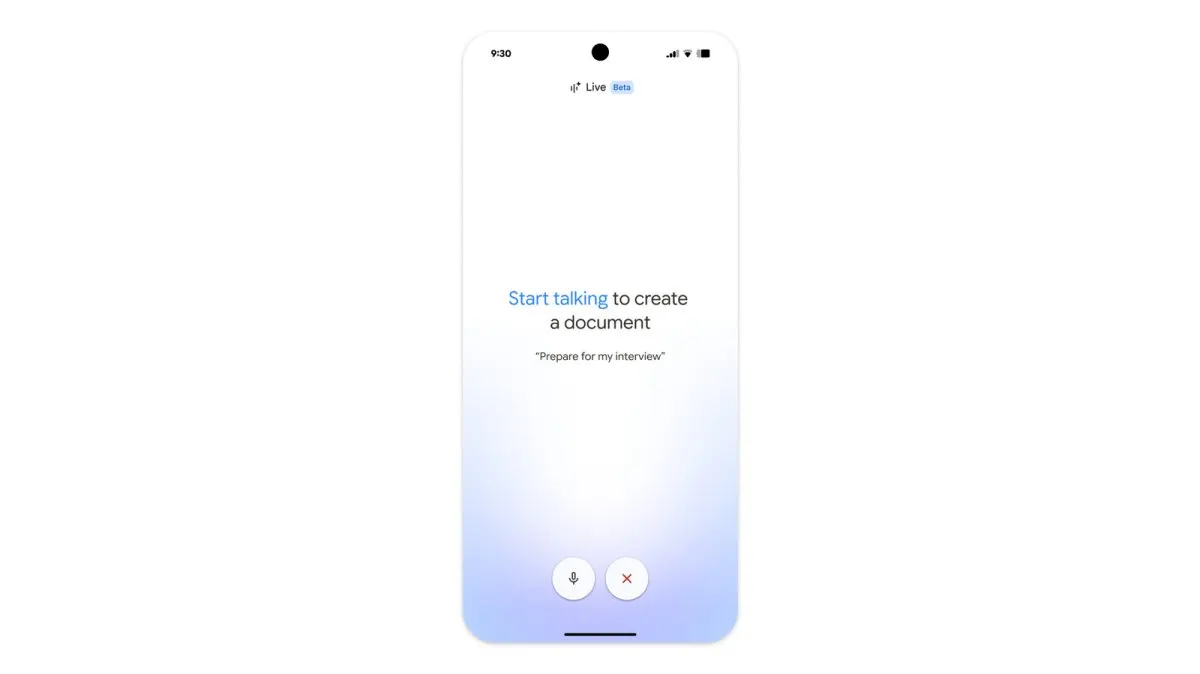
Google is expanding its conversational AI capabilities across Gmail, Docs, and Keep through a new feature set called Live. The update allows users to query inbox data, structure documents via voice, and organize reminders automatically. These tools will initially launch for premium subscribers this summer, with business previews following shortly after. The rollout reflects a broader industry shift toward integrated, voice-first productivity interfaces.
The integration of artificial intelligence into daily productivity tools has shifted from experimental add-ons to foundational infrastructure. Google has announced a significant expansion of conversational capabilities across its core application suite, introducing a unified framework designed to streamline user interactions. This development marks a deliberate move toward voice-driven and natural language workflows within established digital environments. The update aims to reduce manual navigation and accelerate information retrieval across multiple platforms simultaneously.
What is the Live conversational framework?
The Live framework represents a coordinated effort to embed natural language processing directly into everyday applications. Rather than relying on separate assistant interfaces, the system operates natively within the host environment. Users can interact through voice commands or typed queries without switching contexts. This approach minimizes friction and keeps workflows continuous. The underlying architecture leverages large language models to interpret intent and execute tasks across connected services. By unifying these capabilities, Google aims to create a cohesive experience that adapts to individual communication patterns. The framework prioritizes contextual awareness, ensuring that responses remain relevant to the specific application in use.
Historically, productivity suites have evolved through distinct interface paradigms, moving from command lines to graphical menus, and finally to contextual toolbars. The current generation of software demands a more intuitive layer that understands user goals rather than merely executing commands. Google's approach attempts to bridge the gap between passive data storage and active information synthesis. By training models on aggregated usage patterns, the system learns to anticipate common queries and streamline repetitive tasks. This evolution reflects a broader industry recognition that manual data retrieval is increasingly inefficient. The framework also establishes a standardized protocol for cross-application communication, allowing different tools to share contextual data without compromising security boundaries.
How does Gmail Live change inbox management?
Email management has traditionally required manual filtering and keyword searching to locate specific information. Gmail Live introduces a direct query mechanism that scans message history and metadata to retrieve precise answers. Users can ask questions about flight details, meeting times, or attachment locations without navigating through folders. The system processes the request in real time and extracts the relevant data points. This functionality reduces the cognitive load associated with information retrieval. It also changes how professionals approach email as a database rather than a communication stream. The feature operates with strict permission boundaries to ensure user data remains secure during processing.
The shift from keyword-based search to semantic understanding addresses a persistent challenge in digital communication. Traditional search algorithms struggle with natural phrasing and contextual ambiguity, often returning irrelevant results. Conversational interfaces bypass this limitation by parsing the underlying meaning of a query rather than matching exact strings. This capability is particularly valuable for professionals managing high-volume inboxes where critical information is scattered across threads. The system must also distinguish between urgent requests and archival data, prioritizing actionable items appropriately. As email continues to serve as a primary repository for business records, automating retrieval becomes a critical operational necessity.
Why does Docs Live matter for document creation?
Document drafting often begins with fragmented thoughts that require organization before writing can commence. Docs Live addresses this initial phase by converting spoken ideas into structured outlines. The system listens to user input and automatically categorizes concepts into logical sections. With explicit user consent, the application can cross-reference existing files in Drive and Gmail to populate the draft with relevant context. This capability transforms the writing process from a blank page exercise into a guided research session. It also allows users to incorporate external information by querying the internet directly. The feature maintains editorial control by requiring approval before any external data is integrated into the document.
The introduction of voice-structured drafting aligns with cognitive research on idea generation and memory retention. Many professionals find that verbalizing thoughts accelerates the brainstorming phase, yet traditional transcription tools lack the ability to organize output meaningfully. By combining speech recognition with hierarchical structuring algorithms, the application bridges the gap between raw input and polished output. This functionality also reduces the friction associated with research compilation, as users no longer need to manually copy and paste references. The permission-based data pulling ensures that sensitive corporate information remains isolated from public web queries. Ultimately, the tool repositions the document editor from a static canvas into an active research assistant.
How does Keep Live restructure personal notes?
Digital note-taking frequently suffers from unstructured accumulation, where reminders and observations blend into a single chaotic list. Keep Live introduces an automated curation layer that interprets dictated content and assigns appropriate categories. Users can speak freely while the system identifies actionable items, deadlines, and reference material. The application then generates structured reminders and prompts based on the recognized patterns. This process eliminates the need for manual tagging and sorting. It also improves the reliability of task management by converting vague verbal cues into concrete assignments. The feature operates continuously in the background to capture information as it emerges during daily routines.
The psychological burden of digital hoarding has grown alongside the proliferation of note-taking applications. Users often record information with the intention of reviewing it later, yet the lack of organization renders the archive useless. Automated categorization addresses this problem by applying consistent taxonomies to unstructured input. The system utilizes pattern recognition to identify dates, locations, and action verbs, then maps them to predefined templates. This approach mirrors how human memory organizes experiences through association and context. By automating the sorting process, the application ensures that critical information remains accessible when needed. The continuous background operation also captures fleeting insights that might otherwise be lost during manual entry.
What are the rollout timelines and access tiers?
The deployment of these conversational features follows a phased release strategy designed to manage server load and gather user feedback. Premium subscribers will receive early access through the AI Pro and Ultra subscription tiers during the upcoming summer season. This initial phase allows Google to refine the underlying models based on real-world usage patterns. Business customers will gain access to a preview version of the tools around the same timeframe. The enterprise rollout will include additional administrative controls to manage data privacy and compliance requirements. The staggered deployment ensures that stability and performance remain consistent as the feature set scales across millions of accounts.
Phased rollouts are standard practice for complex software updates, particularly those involving artificial intelligence and cross-application data sharing. Early access tiers provide developers with a controlled environment to monitor error rates and optimize response accuracy. Subscription models also align with the computational costs associated with running large language models at scale. Enterprise preview programs allow IT departments to evaluate security implications and integrate the tools into existing workflow protocols. This structured approach minimizes disruption while gathering the necessary telemetry to improve system reliability. The timeline also reflects a broader industry pattern of prioritizing paying customers before expanding to free tiers.
How do these updates fit into the broader productivity landscape?
The integration of conversational interfaces into core applications reflects a wider industry trend toward ambient computing. Traditional menu-driven software is gradually giving way to context-aware systems that anticipate user needs. This shift requires careful balancing between automation and user control to prevent unintended data exposure. Organizations must evaluate how voice-driven queries interact with existing security protocols and data retention policies. The move also highlights the increasing expectation for software to function as an active collaborator rather than a passive tool. Developers are now prioritizing seamless cross-application communication to reduce workflow fragmentation. The success of this approach will depend on maintaining accuracy while minimizing computational overhead.
The competitive landscape of productivity software is rapidly evolving as multiple technology firms pursue similar conversational architectures. Differentiation now depends on the quality of contextual understanding, the breadth of integrated services, and the reliability of automated curation. Users expect their digital environments to adapt to their working styles rather than forcing them to adapt to rigid software constraints. This expectation drives continuous improvements in natural language processing and machine learning optimization. The long-term viability of these tools will rely on their ability to handle complex, multi-step workflows without introducing errors. As the technology matures, it will likely establish new standards for how information is organized, retrieved, and utilized across professional environments.
What are the practical implications for daily workflows?
Adopting conversational productivity tools requires users to adjust their interaction habits and data management practices. Professionals must learn to formulate precise queries that yield accurate results without ambiguity. This shift encourages more intentional communication patterns, as vague requests often produce irrelevant or incomplete responses. Users should also remain vigilant about the information they share with connected applications, as contextual queries may access sensitive files. Training on effective prompt engineering will become a valuable skill in both personal and corporate settings. The transition also demands a willingness to trust automated curation while maintaining oversight of the final output.
Organizations implementing these features will need to establish clear guidelines for data sharing and query permissions. IT departments must configure access controls to prevent unauthorized cross-application data extraction. Employee training programs should emphasize best practices for voice input and natural language querying. The tools will likely reduce time spent on administrative tasks, allowing staff to focus on higher-value work. However, the initial learning curve may temporarily slow productivity as users adapt to the new interface paradigms. Long-term efficiency gains will depend on consistent usage and proper configuration of privacy settings.
How will the technology evolve in the coming years?
The current iteration of conversational productivity tools represents only the beginning of a broader technological transformation. Future updates will likely introduce deeper integration with calendar systems, project management platforms, and communication networks. Advanced models may anticipate user needs by analyzing historical behavior and suggesting proactive actions. Voice recognition accuracy will continue to improve, enabling more natural and nuanced interactions across diverse linguistic contexts. The architecture may also expand to support real-time collaborative editing, where multiple users converse with the system simultaneously. These advancements will require ongoing investment in computational infrastructure and data privacy safeguards.
As artificial intelligence becomes more embedded in everyday software, the distinction between human and machine decision-making will blur. Users will need to develop stronger critical thinking skills to verify automated outputs and maintain editorial control. The industry will also face increased scrutiny regarding data ownership, algorithmic transparency, and ethical AI deployment. Regulatory frameworks may emerge to govern how conversational tools handle personal and corporate information. Despite these challenges, the trajectory points toward increasingly intuitive and responsive digital environments. The ultimate goal remains creating software that enhances human capability rather than replacing it.
Conclusion
The expansion of conversational capabilities across Gmail, Docs, and Keep signals a fundamental reorientation of digital productivity. Users will increasingly interact with their software through natural language rather than manual navigation. This transition demands new habits regarding data sharing and query formulation. The phased rollout provides a structured pathway for adoption while allowing technical teams to monitor performance metrics. As these tools mature, they will likely establish new standards for how information is organized and retrieved. The long-term impact will depend on how effectively the system balances convenience with privacy safeguards.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.







Comments (0)