Google’s Gemini Omni Flash Reshapes AI Video Creation

Google has introduced Gemini Omni Flash, a generative platform that streamlines video production through conversational editing. The system merges reasoning capabilities with media tools to maintain continuity and physical accuracy. Alongside expanded input formats, Google implements SynthID watermarking to address synthetic media verification concerns.
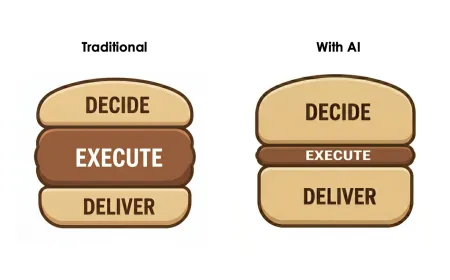
The landscape of digital content creation is undergoing a fundamental structural shift. Traditional software interfaces, once considered indispensable for professional video production, are gradually giving way to conversational interfaces that prioritize natural language over complex toolbars. This transition represents more than a simple user experience update. It signals a broader realignment in how technology companies approach media synthesis, moving away from rigid parameter controls toward dynamic, context-aware systems.
What is Gemini Omni Flash and how does it function?
The initial release of this platform, designated as Gemini Omni Flash, establishes a clear operational framework for cross-format media synthesis. Google positioned the announcement during its annual developer conference in 2026, framing the tool as a direct evolution of earlier image generation capabilities. The system operates by merging advanced reasoning architectures with dedicated media generation pipelines. This architectural choice allows the platform to process diverse input types, including raw text prompts, static photographs, audio recordings, and pre-existing video footage. The output consistently targets video generation, though the underlying architecture is designed to handle bidirectional data flow between different media formats. Distribution occurs through established consumer applications, including the Gemini mobile application, Google Flow, YouTube Shorts, and YouTube Create. Google has indicated that subsequent updates will expand access to external developers and enterprise environments. The platform does not function as an isolated generator. It operates as a continuous refinement engine, where each user interaction adjusts the underlying parameters of the generated output. This design philosophy deliberately distances the tool from conventional nonlinear editing suites. Creators no longer navigate timeline tracks or adjust keyframes manually. Instead, they issue descriptive commands that the system interprets and applies across the entire project file. The result is a workflow that prioritizes iterative dialogue over technical precision. This approach lowers the barrier to entry for casual creators while simultaneously offering professional editors a rapid prototyping environment.
How does conversational editing change the creative workflow?
The introduction of conversational editing represents a deliberate departure from decades of established video production methodology. Historically, video editing has required mastery of complex software ecosystems, extensive keyboard shortcuts, and precise timeline manipulation. These technical requirements create a steep learning curve that excludes many potential creators. The new conversational model replaces this friction with natural language processing. Users describe desired outcomes, and the system translates those descriptions into structural adjustments within the media file. This shift fundamentally alters the relationship between creator and tool. Instead of acting as a manual operator, the creator becomes a director providing continuous feedback. The editing process transforms into a collaborative dialogue where the system anticipates contextual needs and applies corrections automatically. This methodology requires the underlying model to understand spatial relationships, temporal progression, and narrative intent. When a user requests a scene change, the system does not simply swap visual assets. It recalibrates lighting, adjusts camera angles, and modifies background elements to ensure seamless integration. The preservation of consistency remains the primary technical challenge. Generative models frequently struggle with maintaining object permanence and character appearance across extended sequences. Gemini Omni Flash addresses this by implementing persistent state tracking across the entire project duration. Each modification builds upon the previous iteration rather than starting from a blank canvas. This approach mirrors traditional professional workflows while eliminating the manual tracking and masking steps that usually accompany them. The system also interprets abstract creative directions with surprising accuracy. Requests to adjust pacing, alter mood, or refine color grading translate into specific algorithmic adjustments. The platform understands how objects behave in simulated environments, incorporating improved handling of motion, gravity, and movement dynamics. This physical awareness allows creators to specify realistic interactions without manually animating each frame. The conversational interface also supports rapid experimentation. Creators can test multiple visual directions within minutes, evaluating different compositions and lighting setups before committing to a final cut. This iterative speed accelerates the pre-production phase and reduces the financial overhead associated with traditional reshoots. The tool effectively democratizes high-quality visual production by removing technical bottlenecks. However, this convenience introduces new considerations regarding creative control. When the system interprets natural language commands, it inevitably applies its own contextual assumptions. Creators must learn to phrase requests with precision to avoid unintended stylistic drift. The balance between automated assistance and manual oversight defines the new editing paradigm. Professionals will likely adopt this technology as a supplementary layer, using it for rapid drafting and asset generation while retaining final authority over compositional decisions. Casual users will experience a dramatic reduction in production friction, enabling them to realize complex visual concepts that previously required specialized training. The conversational model does not replace technical expertise. It recontextualizes it, shifting the focus from software navigation to creative direction.
Why does physical world modeling matter for synthetic media?
The integration of physical simulation into generative video represents a critical milestone in artificial intelligence development. Early synthetic media tools operated primarily as visual pattern matchers, stitching together recognizable textures and shapes without regard for underlying mechanics. This approach produced visually striking but physically implausible results. Objects would slide across surfaces without friction, shadows would detach from their sources, and gravity would operate inconsistently within a single scene. These anomalies quickly break viewer immersion and limit the practical applications of the technology. The new generation of platforms addresses these limitations by embedding physics engines directly into the generation pipeline. This architectural decision requires the model to understand mass, velocity, collision detection, and environmental interaction before rendering a single frame. The system is also designed to better understand how objects behave in the physical world, incorporating improved handling of motion, gravity, and movement dynamics. This capability transforms synthetic media from a novelty into a functional production tool. Filmmakers and commercial producers require visual consistency that aligns with real-world expectations. Audiences subconsciously reject imagery that violates basic physical laws, regardless of how aesthetically pleasing the composition may be. By grounding generation in observable reality, platforms can produce footage suitable for high-stakes applications, including architectural visualization, scientific simulation, and commercial advertising. The technical implementation involves training models on vast datasets of real-world motion capture and environmental physics. The system learns how light interacts with different materials, how fabrics drape under tension, and how fluids displace when disturbed. This knowledge base allows the model to predict plausible outcomes when users request specific interactions. The mirror above ripples like liquid when someone touches it, or a sculpture can be made of bubbles. These examples demonstrate the platform's ability to simulate complex material properties within a unified generative framework. The implications extend beyond entertainment and marketing. Educational institutions and research organizations can generate accurate visualizations of scientific phenomena without requiring expensive physical setups. Medical professionals can create anatomical simulations that respect biological constraints. Urban planners can model traffic flow and structural stress with realistic parameters. The integration of physics also addresses a growing ethical concern regarding synthetic media manipulation. When AI-generated content consistently violates physical laws, it becomes easier to identify and dismiss as artificial. Conversely, when synthetic media adheres to realistic physical constraints, it becomes indistinguishable from reality without proper verification. This paradox highlights the necessity of transparency measures alongside technological advancement. The pursuit of physical accuracy must be paired with robust authentication systems to maintain public trust. Developers face the challenge of balancing computational efficiency with simulation fidelity. Real-time physics calculations demand significant processing power, which currently limits the resolution and duration of generated content. Future hardware improvements and algorithmic optimizations will likely resolve these bottlenecks, enabling longer, higher-fidelity productions. The industry must also establish standardized benchmarks for physical accuracy in synthetic media. Without clear metrics, developers may prioritize visual polish over mechanical realism, undermining the long-term utility of the technology. The focus on physics modeling reflects a broader industry maturation. Generative AI is transitioning from experimental novelty to foundational infrastructure. The platforms that successfully integrate realistic simulation with intuitive interfaces will define the next era of digital content creation.
How are major technology firms addressing trust and verification?
The rapid proliferation of synthetic media has triggered an urgent industry-wide response regarding authenticity and digital verification. As generative tools produce increasingly convincing imagery and audio, the distinction between recorded reality and artificial construction grows increasingly difficult to discern. This ambiguity creates significant risks for journalism, legal proceedings, and public discourse. Technology companies have recognized that building more capable systems does not mean trust in them will be built in tandem. The solution requires a multi-layered approach combining technical watermarking, cross-platform verification, and regulatory compliance. Google has implemented SynthID watermarking technology to identify AI-generated media directly within the output files. This invisible signature persists through compression, resizing, and format conversion, ensuring that the provenance of the content remains traceable regardless of distribution channels. The verification tools will work across Gemini, Chrome, and Search as part of broader transparency efforts. This ecosystem integration allows users to inspect the origin of media they encounter daily, reinforcing accountability across the digital infrastructure. The implementation of watermarking reflects a proactive stance on digital ethics. Rather than waiting for legislative mandates, the company is establishing industry standards through voluntary adoption. This approach encourages other platform developers to follow suit, creating a unified verification framework that benefits all stakeholders. The technology also supports forensic analysis, enabling researchers and journalists to trace the origin of suspicious content and verify its authenticity before publication. Beyond watermarking, the platform incorporates strict access controls for sensitive generative capabilities. Users will initially be able to create video avatars based on themselves, including their own voice. But more advanced capabilities involving speech modification remain under evaluation while Google works on safety considerations. This cautious rollout prevents the misuse of synthetic voice cloning and deepfake generation, which have historically caused significant reputational and financial harm. The evaluation process involves rigorous testing for potential exploitation vectors, including political manipulation, financial fraud, and identity theft. The company is actively collaborating with external researchers and regulatory bodies to develop comprehensive safety guidelines. This collaborative model ensures that safety protocols evolve alongside technological capabilities, rather than lagging behind. The industry must also address the technical limitations of current verification systems. Sophisticated attackers may attempt to strip or alter embedded watermarks, requiring continuous updates to authentication protocols. Cross-platform compatibility remains a challenge, as different operating systems and applications handle metadata differently. Standardization efforts led by industry consortia will be essential to ensure that verification tools function reliably across diverse digital environments. The balance between transparency and creative freedom requires careful calibration. Overly aggressive watermarking could degrade content quality or trigger false positives in automated detection systems. Underpowered verification could leave synthetic media vulnerable to malicious manipulation. The optimal approach involves layered authentication that adapts to the sensitivity of the content and the context of its distribution. As generative AI becomes embedded in everyday communication, verification will transition from a niche technical feature to a fundamental requirement for digital literacy. Users will need intuitive tools to assess media authenticity without requiring specialized expertise. The integration of verification into mainstream applications, such as web browsers and search engines, represents a critical step toward this goal. The technology must remain accessible, accurate, and unobtrusive to maintain public adoption. The ongoing development of synthetic media verification reflects a broader commitment to responsible innovation. By prioritizing transparency alongside capability, the industry can mitigate the risks of misinformation while preserving the creative potential of generative tools. The path forward requires continuous collaboration between developers, researchers, policymakers, and the public to establish sustainable standards for digital authenticity.
What is the broader trajectory for generative media platforms?
The current generation of AI media tools represents only the initial phase of a much larger technological transformation. Google has indicated that Gemini Omni will eventually expand beyond video generation to support comprehensive multi-format project integration. Future versions are expected to support combinations of photos, prompts, music, and reference footage into a single project. This expansion signals a shift toward unified creative ecosystems where different media types interact seamlessly within a single workspace. The convergence of text, image, audio, and video generation under a single architectural umbrella will fundamentally alter content production pipelines. Creators will no longer need to switch between specialized applications or manually synchronize assets across different platforms. The unified approach reduces workflow fragmentation and accelerates the iteration cycle. This consolidation also enables more sophisticated cross-modal interactions. Audio can directly influence visual pacing, while text prompts can dynamically adjust lighting and composition in real time. The platform will likely incorporate advanced project management features, allowing users to organize assets, track version history, and collaborate with distributed teams within a single interface. The enterprise expansion plans suggest that these tools will soon integrate with existing business software ecosystems. Marketing departments, educational institutions, and media production studios will adopt these platforms as core operational infrastructure. The shift from experimental tools to production-critical systems will drive demand for enhanced reliability, scalability, and technical support. Companies will require robust data governance policies to manage the storage and usage of generated assets. Intellectual property frameworks will need adaptation to address the ownership of AI-assisted creations. The legal landscape surrounding synthetic media remains unsettled, with ongoing debates regarding copyright, attribution, and commercial licensing. Industry stakeholders must develop clear guidelines that protect original creators while enabling the commercial viability of AI-generated content. The economic implications of unified generative platforms will be substantial. Traditional software licensing models may give way to subscription-based access tiers that scale with computational usage. Cloud infrastructure providers will face increased demand for high-performance rendering clusters to support real-time generation workloads. The competitive landscape will intensify as technology firms race to establish dominant ecosystems. Platforms that successfully integrate intuitive interfaces, robust verification, and comprehensive media support will capture significant market share. Smaller developers may focus on niche applications, offering specialized tools that complement rather than compete with major platforms. The industry will likely see increased consolidation, with larger companies acquiring promising startups to expand their generative capabilities. The long-term trajectory points toward increasingly autonomous creative assistants. Current conversational interfaces will evolve into predictive systems that anticipate user needs and suggest compositional adjustments before explicit requests are made. The boundary between human direction and machine execution will continue to blur, requiring creators to develop new skill sets focused on curation, oversight, and strategic vision. Educational institutions will adapt curricula to emphasize critical thinking, ethical evaluation, and cross-disciplinary collaboration over technical software proficiency. The generative media landscape will ultimately prioritize accessibility, transparency, and creative empowerment. Platforms that successfully balance technological ambition with responsible deployment will define the future of digital expression. The industry must remain vigilant against monopolistic practices and ensure that creative tools remain available to independent developers and small studios. The democratization of high-quality media production depends on open standards, competitive markets, and sustained investment in public digital infrastructure. The next decade of generative AI will be measured not by processing speed alone, but by its ability to enhance human creativity while preserving digital authenticity and cultural diversity.
Conclusion
The evolution of AI-driven media creation continues to reshape how digital content is conceived, produced, and distributed. The transition from manual editing interfaces to conversational synthesis marks a significant inflection point in creative technology. Platforms that prioritize physical accuracy, seamless multi-format integration, and robust verification will establish the foundation for the next generation of digital expression. Creators and consumers alike will navigate a landscape where the distinction between artificial and authentic media requires careful evaluation. The ongoing development of transparency measures and ethical guidelines will determine whether these tools enhance public discourse or undermine it. The industry stands at a critical juncture where technical capability must align with responsible deployment. Success depends on sustained collaboration across technology, policy, and creative communities to ensure that generative media serves as a constructive force in digital culture.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)