Hermes Agents and Local AI Hardware: A Technical Overview
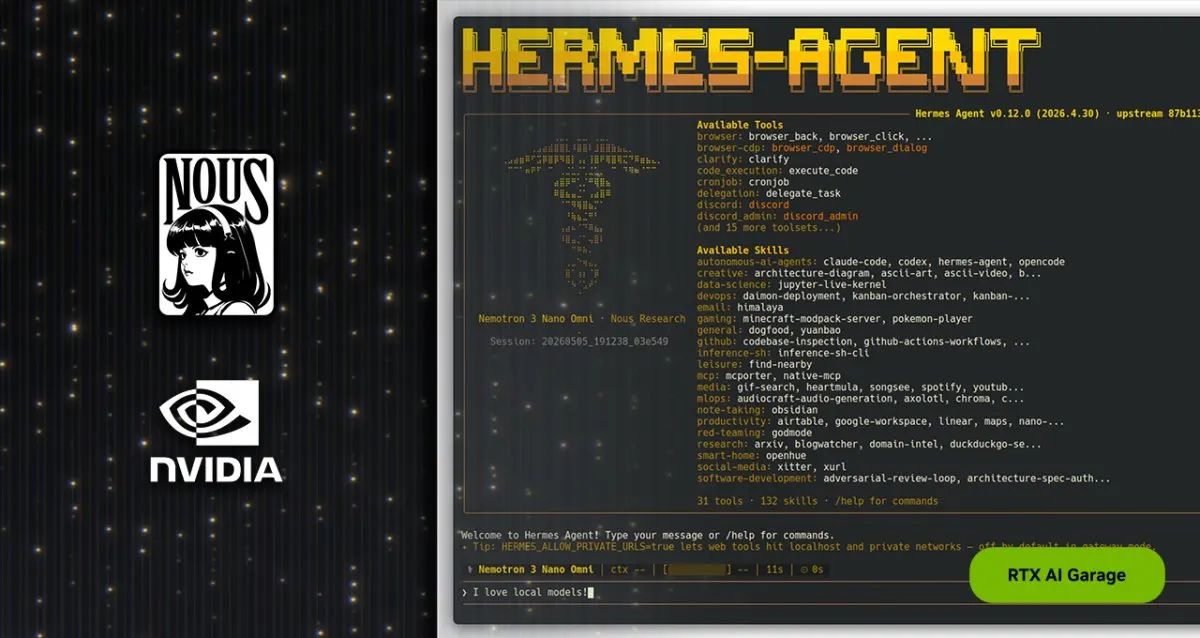
Reliable, self-evolving and powered by the newest agentic large language models, Hermes brings a new class of agents to NVIDIA RTX PCs and workstations.
The boundary between static artificial intelligence and dynamic autonomous systems continues to blur as research teams transition from predictive models to executing frameworks. Developers are no longer satisfied with outputs that merely reflect training data. They require systems capable of observing their own performance, identifying limitations, and adjusting parameters without human intervention. This shift introduces a new category of computational tools designed to operate continuously across distributed environments. The recent introduction of Hermes signals a deliberate move toward self-evolving architectures that combine large language model capabilities with localized hardware acceleration. By grounding these agents in accessible workstations and compact server modules, engineers can test autonomous loops in controlled settings before scaling to production infrastructure.
What Is the Architecture Behind Self-Evolving AI Agents?
Traditional machine learning pipelines rely on fixed checkpoints and periodic retraining cycles. Engineers collect new data, validate models against benchmarks, and deploy updated weights through version control systems. This approach guarantees stability but introduces significant latency when operational environments change rapidly. As a result, organizations struggle to maintain responsiveness in dynamic markets. Self-improving agents operate on a fundamentally different principle. They maintain active feedback loops that monitor task completion rates, error patterns, and resource utilization in real time.
When an agent encounters a failure mode, it does not simply log the event for later analysis. It recalibrates its internal routing mechanisms, adjusts prompt structures, or modifies memory retrieval strategies to bypass the bottleneck. This continuous adaptation requires robust underlying frameworks that can handle dynamic state management without destabilizing the core model. The reliability of such systems depends on strict guardrails that prevent runaway optimization or context drift. Researchers must design evaluation metrics that track both performance gains and behavioral consistency across extended deployment periods.
These architectures demand specialized memory management protocols to store intermediate reasoning steps. Agents must distinguish between transient context and permanent knowledge bases. Without clear boundaries, the system risks conflating temporary observations with foundational training data. Developers implement compartmentalized storage layers to isolate active working memory from long-term archives. This separation ensures that self-correction processes do not corrupt the original model weights. Instead, adjustments remain confined to temporary inference pathways that can be rolled back if performance degrades.
Why Does Local Deployment Matter for Agentic Workflows?
Cloud-based inference engines have historically dominated the deployment landscape for large language models. Centralized data centers offer massive compute pools and simplified maintenance routines. However, agentic workloads demand different characteristics than batch processing or interactive chat applications. Autonomous systems require deterministic latency, consistent memory allocation, and uninterrupted execution cycles. Network dependencies introduce unpredictable jitter that can disrupt multi-step reasoning chains or cause timeout failures during critical operations.
Running agents on localized hardware eliminates these external variables. Workstations equipped with high-bandwidth memory interfaces and specialized tensor cores can process context windows entirely within the machine. This architecture supports rapid iteration cycles where agents test hypotheses, execute code, and validate results without waiting for remote API responses. Organizations also gain direct control over data sovereignty and access policies. Sensitive operational logs remain within the corporate perimeter, reducing exposure during continuous learning phases.
The shift toward localized deployment reflects a broader industry recognition that autonomy requires physical proximity to the data it manipulates. Remote servers introduce compliance complexities when handling proprietary information. Local architectures allow teams to define precise security boundaries and audit access logs directly. This control becomes essential when deploying agents in regulated sectors like finance or healthcare. The ability to manage hardware directly also simplifies troubleshooting and performance tuning. Engineers can optimize thermal profiles and power distribution to sustain continuous workloads without external dependency.
How Do RTX PCs and DGX Spark Enable Autonomous Systems?
Hardware selection directly dictates the feasible complexity of self-improving architectures. Consumer-grade graphics processing units have evolved significantly over the past decade, transitioning from gaming peripherals to accessible computational platforms. Modern RTX workstations integrate dedicated ray tracing cores, tensor units, and high-speed memory bandwidth into compact chassis. These components provide the necessary throughput to run agentic large language models locally. Developers can load substantial context windows, execute parallel reasoning traces, and maintain active memory stores without exceeding available VRAM.
DGX Spark extends this capability into server environments by packaging multiple GPU modules into a single rack-ready unit. The architecture optimizes thermal management, interconnect bandwidth, and power delivery to sustain continuous workloads. When paired with distributed training frameworks, these systems allow researchers to scale autonomous testing from a single desk to a modular cluster. The hardware stack supports dynamic workload balancing, ensuring that inference, fine-tuning, and validation tasks share resources efficiently. This flexibility enables teams to prototype self-evolving agents in isolated environments before committing to full production deployment.
The integration of specialized silicon accelerates the training and inference phases required for autonomous loops. Standard CPUs struggle to handle the parallel matrix operations that drive large language models. Dedicated tensor cores process these calculations at significantly higher speeds while consuming less power. This efficiency allows workstations to run complex agentic frameworks without generating excessive heat or requiring industrial cooling solutions. Engineers can deploy these systems in standard office environments or remote field locations. The compact form factor ensures that autonomous computing remains portable and adaptable to diverse operational settings.
What Are the Practical Implications for Enterprise and Research?
The introduction of self-improving agents forces organizations to reconsider their operational workflows. Manual oversight remains necessary during initial deployment, but the long-term objective involves delegating routine optimization tasks to autonomous systems. Engineering teams can redirect human expertise toward architectural design, constraint definition, and high-level strategy. This transition requires new evaluation protocols that measure agent performance across extended timelines rather than single-session benchmarks. Researchers must track metrics such as task completion consistency, error recovery speed, and resource consumption trends.
The ability to run these systems on accessible hardware lowers the barrier to entry for independent developers and smaller research groups. Academic institutions and startups can experiment with agentic frameworks without requiring enterprise-scale cloud budgets. The democratization of autonomous computing accelerates innovation cycles and encourages cross-disciplinary applications. Financial, healthcare, and logistics sectors are particularly interested in systems that can continuously refine routing algorithms or compliance checks. The practical value lies not in replacing human decision-making, but in augmenting it with persistent, self-correcting support layers.
Organizations must also address the cultural shift required to trust autonomous systems. Historical failures with automated tools often stem from opaque decision-making processes. Transparent logging and explainable outputs become critical components of agent design. Teams need visualization dashboards that track agent reasoning steps in real time. These interfaces allow human supervisors to intervene when necessary while allowing the system to operate independently during stable periods. The goal is to establish a collaborative environment where machines handle repetitive optimization while humans focus on creative problem-solving and strategic planning. The integration of frameworks like NextGenAI provides a foundation for standardizing these workflows across diverse teams.
How Will Autonomous Systems Reshape Software Development?
Software engineering has traditionally relied on version control, code review, and automated testing to maintain quality standards. Agentic workflows introduce a new layer of continuous integration where models actively participate in the development lifecycle. Instead of awaiting manual prompts for code generation or bug analysis, self-improving agents monitor repository changes, execute test suites, and propose patches based on observed failure patterns. This capability aligns closely with the principles behind modern engineering acceleration frameworks. When agents can autonomously validate changes and adjust parameters, development velocity increases without sacrificing stability.
Teams that adopt these systems often report faster iteration cycles and reduced overhead for routine maintenance tasks. The integration of localized hardware ensures that sensitive proprietary code remains within secure boundaries during automated analysis. As these tools mature, they will likely become standard components in continuous delivery pipelines. The focus will shift from building isolated models to orchestrating interconnected agent networks that share knowledge across projects. This evolution demands robust monitoring dashboards and clear accountability frameworks to track autonomous actions. Organizations can leverage strategies similar to accelerating engineering cycles to maximize the efficiency of these automated workflows.
The long-term impact extends beyond individual repositories to entire organizational knowledge bases. Agents can analyze historical documentation, identify recurring technical debt, and suggest architectural improvements before problems escalate. This proactive approach reduces downtime and prevents minor issues from compounding into systemic failures. Engineers gain more time to focus on novel feature development and cross-team collaboration. The automation of routine maintenance creates a more resilient software ecosystem that adapts to changing requirements without constant human intervention.
What Are the Limitations and Safeguards Required for Reliable Deployment?
Autonomous systems are not immune to structural constraints. Self-improving architectures can drift into suboptimal loops if feedback mechanisms lack proper validation. Without rigorous oversight, an agent might optimize for short-term efficiency at the expense of long-term reliability. Developers must implement strict evaluation checkpoints that compare agent outputs against established ground truth datasets. These checkpoints should trigger human review when performance deviates beyond acceptable thresholds. Additionally, memory management remains a critical challenge. Agents that continuously accumulate context may exhaust available resources or introduce conflicting information into their decision trees.
Effective systems require periodic memory compaction, relevance filtering, and state reset protocols. Security considerations also demand attention. Autonomous tools that modify their own configurations must operate within sandboxed environments to prevent unintended system alterations. Regulatory frameworks will likely evolve to address auditability and accountability for self-modifying software. Organizations must establish clear policies regarding which operational domains agents can access and how changes are documented. Transparent reporting mechanisms ensure that autonomous decisions remain traceable and compliant with industry standards.
Conclusion
The trajectory of artificial intelligence continues to move toward increasingly autonomous architectures. The transition from static models to self-evolving agents represents a fundamental shift in how computational systems interact with complex environments. Hardware acceleration through specialized workstations and compact server modules provides the necessary foundation for these dynamic workflows. Researchers and engineers must balance innovation with rigorous oversight to ensure reliability. The integration of localized processing, continuous feedback loops, and standardized evaluation metrics will determine the success of this next phase.
As autonomous tools mature, they will reshape development pipelines, operational workflows, and research methodologies. The focus will remain on building systems that enhance human capability while maintaining strict accountability. The coming years will test our ability to design, monitor, and scale these networks responsibly across diverse industries. The convergence of accessible hardware and adaptive software will define the next era of computational productivity. Success depends on disciplined implementation, continuous validation, and a commitment to transparency in all autonomous operations.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)