A Structured Workflow for Decoding Language Model Architectures
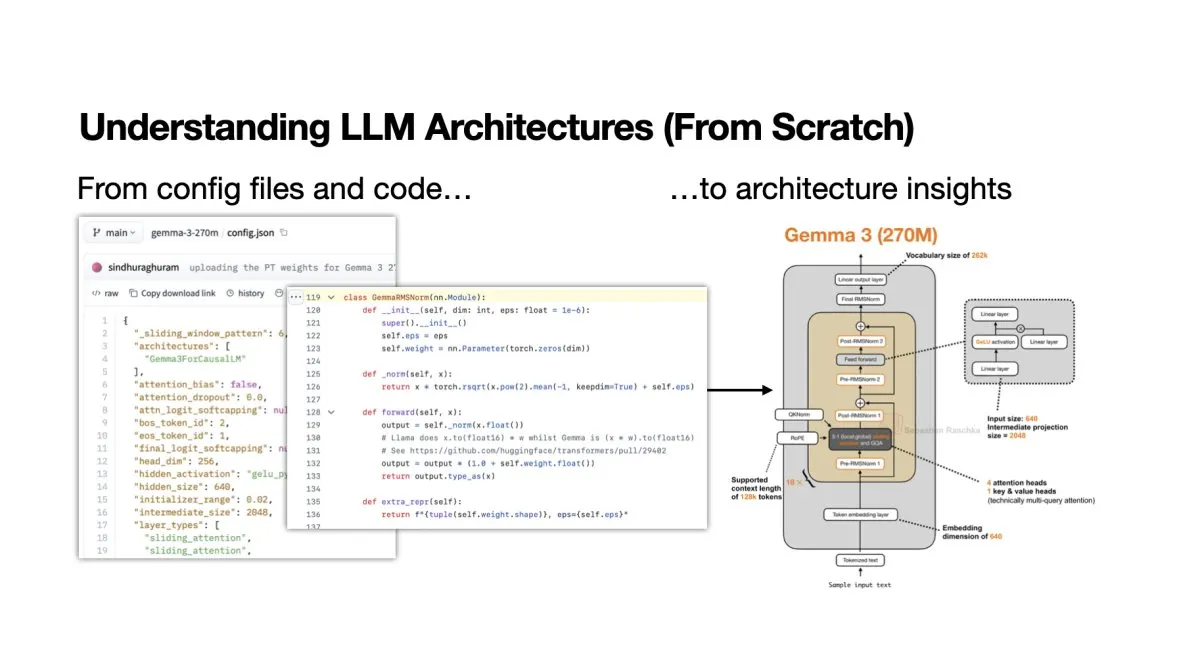
Understanding large language model architectures requires a structured methodology that prioritizes structural analysis, component mapping, and empirical verification over superficial benchmarks. This approach enables practitioners to decode network designs systematically and apply architectural insights across diverse machine learning deployments.
The rapid proliferation of open-weight language models has transformed architectural analysis from an academic exercise into a daily operational requirement. Researchers and engineers must parse complex network designs without relying on proprietary documentation or black-box demonstrations. Establishing a systematic approach to decoding these architectures ensures that technical evaluations remain reproducible and grounded in observable structural principles rather than speculative interpretations.
What is the foundational structure of modern transformer networks?
Modern language models operate on a framework built upon attention mechanisms and layered neural pathways. The core architecture divides processing into distinct stages, beginning with tokenization, which converts raw text into numerical sequences. These sequences pass through embedding layers that map linguistic units to high-dimensional vectors. The subsequent transformer blocks apply self-attention operations to weigh the relevance of each token relative to every other token in the sequence. Positional encoding ensures that the model retains awareness of token order, a critical factor for understanding syntax and contextual relationships. Researchers examining these systems must first map the tokenization vocabulary, verify the embedding dimensions, and trace the flow of data through the residual connections. Understanding these baseline components provides the necessary foundation for evaluating more complex architectural modifications.
Historical developments in neural network design reveal a consistent shift toward modular, composable structures. Early sequence models relied on recurrent pathways that struggled with long-range dependencies. The introduction of parallel attention mechanisms resolved these bottlenecks by allowing simultaneous processing of all sequence positions. This architectural pivot fundamentally changed how information flows through deep networks. Engineers who study this evolution recognize that modern designs prioritize computational efficiency alongside representational capacity. Documenting these structural choices helps researchers trace how theoretical constraints shape practical implementations.
Evaluating the embedding and normalization stages requires careful attention to numerical precision and scaling factors. Researchers must verify how input vectors are projected, how layer normalization stabilizes activations, and how residual connections prevent gradient degradation. These components operate invisibly during inference but dictate the stability and convergence properties of the entire system. Mapping these pathways reveals where architectural innovations actually occur and highlights which modules require targeted optimization. A disciplined documentation practice ensures that structural observations remain tied to measurable system behavior rather than abstract mathematical descriptions.
How does architectural variation influence model behavior?
Deviations from the standard transformer blueprint typically emerge to address computational efficiency, memory constraints, or specialized processing requirements. Some designs replace dense attention with sparse or linearized attention mechanisms to reduce the quadratic scaling of computational operations. Others introduce mixture-of-experts routing, which directs different input sequences through specialized subnetworks rather than activating the entire model simultaneously. Researchers analyzing these variations must inspect the routing logic, verify the activation thresholds, and assess how the model handles expert selection during inference. Mapping these structural differences reveals how architectural choices directly impact latency, memory footprint, and reasoning capabilities.
Engineers who track these modifications can better predict which models will align with specific deployment constraints. The trade-offs between parameter density and computational throughput determine which architectures suit high-frequency inference versus batch processing. Some implementations prioritize flash attention optimizations to minimize memory bandwidth usage, while others focus on quantization compatibility to reduce storage requirements. Understanding these engineering priorities requires examining how structural changes interact with underlying hardware capabilities. Researchers who document these interactions build a reliable reference for future architectural comparisons.
Analyzing routing algorithms and conditional computation pathways demands precise measurement of activation patterns. Researchers should monitor how often specific experts are selected, how load balancing mechanisms function, and how routing overhead impacts overall throughput. These metrics clarify whether conditional computation actually delivers the promised efficiency gains or introduces unpredictable latency spikes. Systematic tracking of these variables transforms subjective architectural assessments into objective engineering evaluations. The resulting data supports informed decisions about model selection and infrastructure allocation.
Evaluating Parameter Distribution and Computational Load
The evaluation of a new architecture extends beyond examining its forward pass. The training configuration dictates how parameters initialize, how gradients propagate, and how the model generalizes to unseen data. Researchers must document the optimizer settings, learning rate schedules, and weight decay parameters that shape the optimization trajectory. The distribution of parameters across different components also matters significantly. Some architectures allocate the majority of parameters to feedforward layers, while others concentrate them within attention heads or normalization modules. Analyzing these distributions helps identify computational bottlenecks and highlights where architectural innovations actually occur.
Cross-referencing these training configurations with publicly available implementation code ensures that theoretical designs match practical execution. Engineers should verify how layer dimensions scale, how hidden states align across blocks, and how residual connections maintain signal integrity. These structural details often diverge between research papers and production repositories. Reconciling these differences requires meticulous code review and empirical testing. Researchers who maintain standardized verification protocols prevent analytical drift and ensure that conclusions remain tied to observable evidence.
Tracking parameter density across different architectural layers reveals how computational resources are allocated during inference. Models that concentrate parameters in early layers may prioritize rapid contextual encoding, while those that distribute parameters more evenly often emphasize fine-grained feature extraction. Understanding these allocation strategies helps engineers predict which architectures will perform best under specific hardware constraints. Documenting these observations creates a reusable framework for future architectural assessments.
Why does empirical verification matter in architectural analysis?
Structural diagrams and documentation often oversimplify complex implementation details. Running inference on sample inputs reveals how the model actually processes information. Researchers should test edge cases, monitor attention weights across different layers, and observe how intermediate representations evolve. Comparing outputs across varying input lengths helps identify scaling behaviors and reveals whether the architecture maintains consistency under different conditions. This empirical phase bridges the gap between theoretical design and functional reality.
Collaborative research initiatives, such as those highlighted in the 1,000 Scientist AI Jam Session, demonstrate how shared testing protocols accelerate architectural understanding across distributed teams. Standardized verification reduces subjective interpretation and produces reproducible findings. When multiple researchers apply identical evaluation pipelines, architectural discrepancies become immediately apparent. This transparency fosters trust in published benchmarks and prevents the propagation of unverified claims. Empirical rigor remains the cornerstone of reliable machine learning research.
Monitoring activation distributions and gradient magnitudes during early training phases exposes potential optimization failures. Researchers can detect vanishing signals, exploding gradients, or dead neurons before they degrade model performance. Logging these metrics alongside architectural configuration files creates a comprehensive record of system behavior. Engineers who maintain these logs can quickly diagnose convergence issues and adjust hyperparameters accordingly. This proactive approach minimizes wasted computational resources and accelerates the debugging cycle.
Building a Reproducible Analysis Pipeline
A sustainable workflow requires systematic documentation and version control for every architectural component. Researchers should maintain a structured ledger that records model identifiers, configuration files, and implementation versions. Each structural modification must be tracked alongside its corresponding performance metrics and resource utilization data. Automated logging tools can capture activation patterns, memory allocation, and computational throughput during both training and inference phases. This data collection framework prevents analytical drift and ensures that conclusions remain tied to observable evidence rather than speculative assumptions.
Engineers who adopt standardized evaluation templates can compare disparate architectures without introducing measurement bias. Consistent input generation, fixed random seeds, and identical hardware configurations eliminate confounding variables that obscure true performance differences. Researchers must also document external dependencies, including compiler versions, library updates, and operating system patches. These environmental factors frequently influence numerical precision and execution speed. Capturing them ensures that architectural comparisons remain valid across different computing environments.
Maintaining a centralized repository of architectural observations streamlines future research efforts. Researchers can quickly retrieve configuration details, verify implementation choices, and trace historical design decisions. This institutional memory prevents redundant analysis and accelerates the onboarding process for new team members. Structured documentation transforms isolated technical evaluations into reusable organizational assets. Teams that prioritize this discipline consistently outperform those relying on informal knowledge sharing.
Navigating Future Architectural Developments
The trajectory of language model design continues to shift toward hybrid systems that combine discrete and continuous processing pathways. Emerging research explores neuro-symbolic integration, dynamic computation routing, and adaptive precision scaling. Understanding these developments requires maintaining a flexible analytical framework that can accommodate novel structural paradigms without discarding established evaluation methods. Researchers who track foundational principles rather than fleeting implementation trends will remain equipped to assess upcoming innovations.
Initiatives like Introducing NextGenAI illustrate how forward-looking research agendas prioritize architectural transparency and standardized benchmarking. Open documentation, shared evaluation code, and reproducible experimental setups accelerate collective progress. Engineers who contribute to these ecosystems gain early access to architectural insights that inform infrastructure planning. Collaborative transparency ensures that technological advancement does not outpace analytical capacity. The field advances most effectively when practitioners share standardized workflows and maintain transparent documentation across all stages of model assessment.
Conclusion
Architectural analysis ultimately depends on disciplined observation and systematic documentation. Researchers who prioritize structural mapping, empirical testing, and reproducible pipelines build a reliable foundation for evaluating complex neural networks. This methodology transforms architectural decoding from an ad hoc exercise into a repeatable engineering practice. Sustained analytical rigor ensures that technical evaluations remain grounded in observable evidence rather than speculative interpretation. The field advances most effectively when practitioners share standardized workflows and maintain transparent documentation across all stages of model assessment.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.







Comments (0)