Posts

AI Snake Oil is now available to preorder
What artificial intelligence can do, what it can't, and how to tell the diffe...

AI safety is not a model property
Trying to make an AI model that can’t be misused is like trying to make a com...

A safe harbor for AI evaluation and red teaming
An argument for legal and technical safe harbors for AI safety and trustworth...
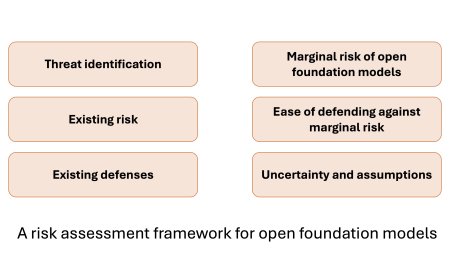



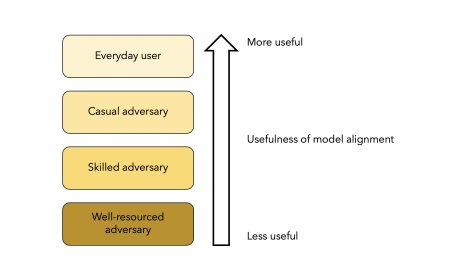
Model alignment protects against accidental harms, n...
The hand wringing about failures of model alignment is misguided
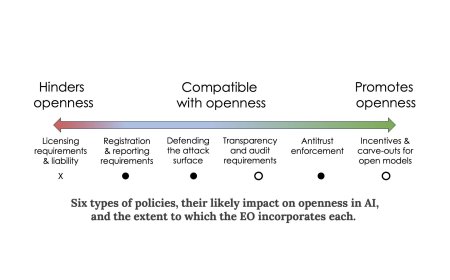
What the executive order means for openness in AI
Good news on paper, but the devil is in the details
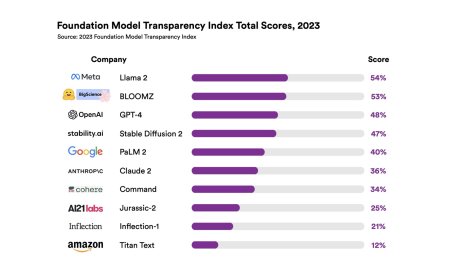
How Transparent Are Foundation Model Developers?
Introducing the Foundation Model Transparency Index


Reinforcement Learning From Human Feedback (RLHF) Fo...
Reinforcement Learning from Human Feedback (RLHF) has turned out to be the ke...

LLM For Structured Data
It is estimated that 80% to 90% of the data worldwide is unstructured. Howeve...

Strategies For Effective Prompt Engineering
When I first delved into machine learning, prompt engineering seemed like a n...

LLM Evaluation For Text Summarization
Text summarization is a prime use case of LLMs (Large Language Models). It ai...




