admin

Reinforcement Learning From Human Feedback (RLHF) Fo...
Reinforcement Learning from Human Feedback (RLHF) has turned out to be the ke...

Is the future of AI open or closed? Watch today’s Pr...
By Sayash Kapoor, Rishi Bommasani, Percy Liang, Arvind Narayanan Perhaps the ...

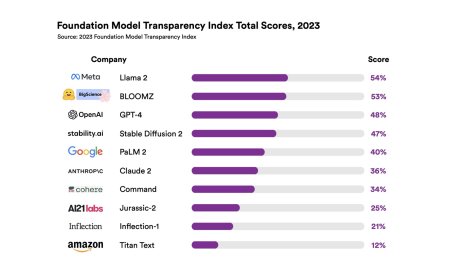
How Transparent Are Foundation Model Developers?
Introducing the Foundation Model Transparency Index
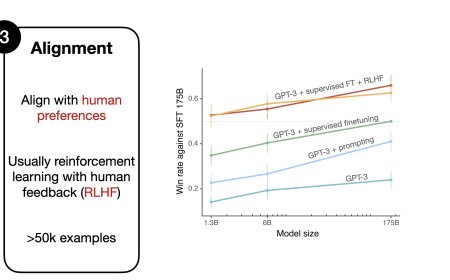
LLM Training: RLHF and Its Alternatives
I frequently reference a process called Reinforcement Learning with Human Fee...

From Self-Alignment to LongLoRA
Another month, another round of interesting research papers ranging from larg...

LLM Business and Busyness: Recent Company Investment...
Discussing Recent Company Investments and AI Adoption, New Small Openly Avail...
A Potential Successor to RLHF for Efficient LLM Alig...
From Vision Transformers to innovative large language model finetuning techni...
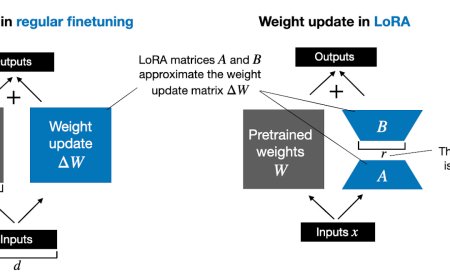
Practical Tips for Finetuning LLMs Using LoRA (Low-R...
Things I Learned From Hundreds of Experiments
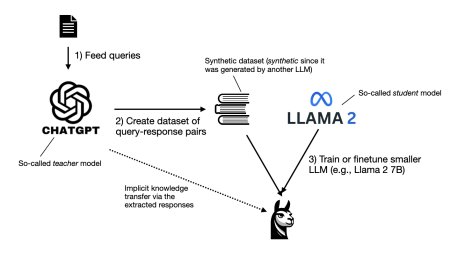
Tackling Hallucinations, Boosting Reasoning Abilitie...
This month, I want to focus on three papers that address three distinct probl...
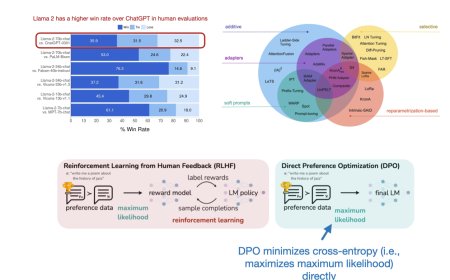
Ten Noteworthy AI Research Papers of 2023
This year has felt distinctly different. I've been working in, on, and with m...
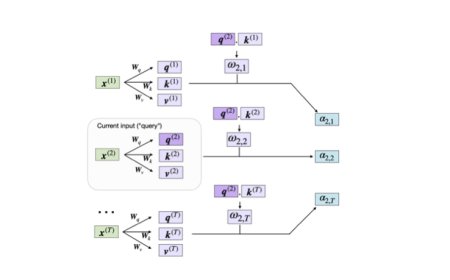
Understanding and Coding Self-Attention, Multi-Head ...
This article will teach you about self-attention mechanisms used in transform...
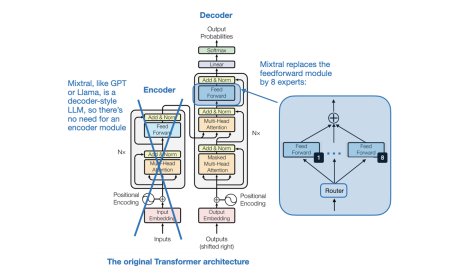
Model Merging, Mixtures of Experts, and Towards Smal...
Model Merging, Mixtures of Experts, and Towards Smaller LLMs
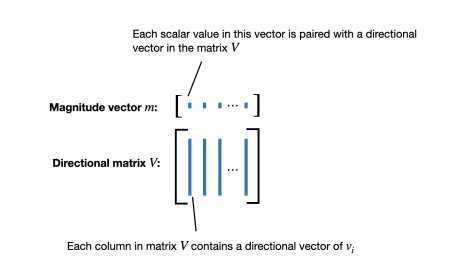
Improving LoRA: Implementing Weight-Decomposed Low-R...
Low-rank adaptation (LoRA) is a machine learning technique that modifies a pr...
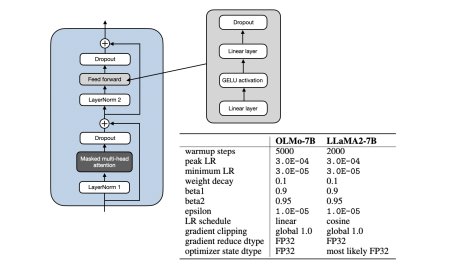
Research Papers in February 2024: A LoRA Successor, ...
Once again, this has been an exciting month in AI research. This month, I'm c...