Serverless FastAPI Deployment on AWS Lambda Explained
This analysis examines a streamlined deployment methodology for FastAPI applications on Amazon Lambda using an open-source translation layer. By eliminating custom handler requirements and container dependencies, engineering teams can maintain environment parity while leveraging automatic scaling mechanisms. The approach reduces operational complexity, minimizes baseline infrastructure costs, and preserves framework portability across multiple cloud providers and local development environments.
Modern software engineering has increasingly shifted toward serverless architectures to eliminate infrastructure management overhead. Python developers historically encountered significant friction when attempting to run high-performance web frameworks within event-driven cloud environments. Traditional deployment methodologies required custom handler functions, containerized build processes, and framework-specific adapters that fractured development workflows. The introduction of standardized translation layers has fundamentally altered this landscape by allowing standard application code to operate seamlessly across distributed compute boundaries.
This analysis examines a streamlined deployment methodology for FastAPI applications on Amazon Lambda using an open-source translation layer. By eliminating custom handler requirements and container dependencies, engineering teams can maintain environment parity while leveraging automatic scaling mechanisms. The approach reduces operational complexity, minimizes baseline infrastructure costs, and preserves framework portability across multiple cloud providers and local development environments.
What is Lambda Web Adapter and how does it resolve historical deployment friction?
Serverless computing platforms operate on an event-driven model that differs fundamentally from traditional long-running web servers. Developers previously relied on adapter libraries to translate incoming network requests into framework-specific application programming interface calls. These adapters required explicit configuration, introduced additional dependency layers, and often forced developers to modify their routing logic to accommodate platform constraints. The architectural compromise frequently resulted in fragmented codebases that struggled to maintain consistency across different deployment targets.
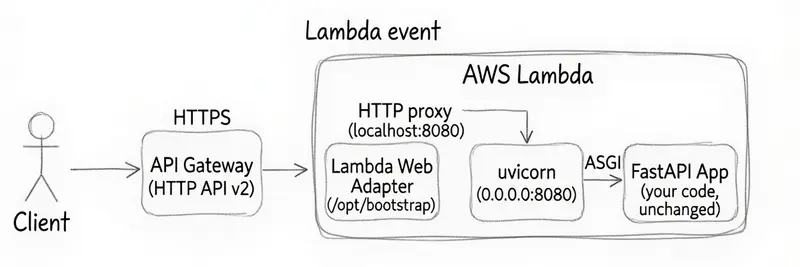
Amazon recently released an open-source translation layer designed specifically to bridge this gap without requiring application modifications. The component functions as a managed runtime extension that intercepts platform invocations and proxies them directly to a local network port. By establishing a standardized communication channel, the tool allows standard web servers to process incoming traffic exactly as they would on conventional virtual machines or container orchestration platforms. This mechanism effectively decouples framework logic from infrastructure requirements.
The implementation relies on a lightweight bootstrap wrapper that initializes alongside the primary application process. When network traffic reaches the distributed gateway, the system routes requests through the adapter before forwarding them to the local server instance. The translation layer handles protocol conversion, header mapping, and payload serialization automatically. Developers retain complete control over routing definitions, middleware configuration, and response formatting without introducing platform-specific dependencies into their core codebase.
Why does zero-code adaptation matter for modern Python development?
Engineering teams consistently prioritize environment parity when designing scalable software systems. Discrepancies between local testing configurations and production deployment targets frequently introduce subtle bugs that remain undetected until late in the release cycle. Maintaining identical execution environments across different stages of the software development lifecycle reduces debugging overhead and accelerates feature delivery timelines. Framework purity becomes a strategic asset rather than an aesthetic preference.
Traditional serverless deployment strategies required developers to wrap their application logic within platform-specific handler functions. This practice introduced coupling between business rules and infrastructure requirements, making code reuse across different cloud providers increasingly difficult. Engineers often found themselves maintaining separate routing configurations for local development versus production environments. The resulting technical debt accumulated rapidly as applications grew in complexity and feature scope.
Eliminating adapter dependencies allows engineering teams to treat the serverless platform as a transparent compute runtime rather than a framework constraint. Standardized deployment tools abstract away infrastructure provisioning while preserving original application architecture. Developers can execute identical startup commands locally and remotely, ensuring consistent behavior across all environments. This approach simplifies onboarding processes for new team members and reduces operational friction during routine maintenance cycles.
How does serverless pricing reshape infrastructure economics for Python APIs?
Traditional virtual machine hosting models require organizations to pay for baseline capacity regardless of actual utilization rates. Applications running continuously on dedicated instances generate fixed monthly expenses even during periods of minimal traffic or complete inactivity. This financial structure creates inefficiency for projects experiencing variable demand patterns or early-stage growth phases where resource allocation remains unpredictable.
Serverless computing platforms operate on a consumption-based pricing model that charges strictly for active execution time and memory utilization. Organizations pay nothing when applications remain idle, effectively eliminating baseline infrastructure costs during development or low-traffic periods. The financial structure aligns directly with actual business value generation rather than speculative capacity planning. This alignment proves particularly advantageous for side projects, internal tools, and early-stage commercial applications.
Network gateway fees introduce a secondary cost component that scales alongside request volume. Modern distributed gateways offer tiered pricing structures that significantly reduce per-request expenses compared to legacy routing systems. The combination of compute consumption billing and optimized network pricing creates a highly efficient economic model for applications experiencing unpredictable traffic patterns. Organizations can scale from zero to thousands of concurrent users without modifying their financial forecasting approaches.
What are the practical trade-offs regarding initialization latency?
Historical serverless architectures frequently suffered from prolonged startup delays that impacted user experience during infrequent access periods. The platform must allocate compute resources, download dependencies, and initialize runtime environments before processing any incoming requests. These initialization phases created noticeable delays that frustrated users and complicated real-time application design patterns. Engineering teams historically weighed these latency penalties against operational simplicity benefits.
Modern translation layers introduce a predictable startup overhead as the local web server initializes within the execution environment. The additional delay typically ranges between one hundred to two hundred milliseconds during cold start scenarios. This timeframe represents the period required for dependency loading, process spawning, and network binding operations. The duration remains consistent across similar runtime configurations and hardware architectures.
Subsequent requests benefit from maintained execution environments that persist between invocations, effectively eliminating initialization delays during active usage periods. Platform infrastructure retains warm instances for extended durations when traffic patterns remain steady. Organizations requiring guaranteed response times can implement provisioned concurrency mechanisms or utilize snapshot-based initialization features. These strategies absorb latency penalties while preserving the economic advantages of consumption-based billing models.
How should engineering teams approach operational scaling?
Initial deployment establishes a functional baseline, but long-term success requires systematic attention to observability and maintenance workflows. Engineering teams must implement comprehensive monitoring solutions that track request latency, error rates, and resource utilization across distributed components. Traditional debugging approaches prove insufficient when applications operate across ephemeral compute boundaries without persistent storage or fixed network addresses.
Persistent data management represents a critical architectural consideration for production environments relying on transient compute instances. In-memory storage mechanisms function adequately during development phases but require migration to distributed database services before handling user data. Organizations typically integrate managed key-value stores or relational database proxies that maintain state independently of the compute layer. This separation ensures data durability regardless of underlying infrastructure scaling events.
Continuous integration pipelines automate deployment processes while enforcing quality gates before changes reach production environments. Automated testing frameworks validate routing configurations, dependency compatibility, and response formatting across different runtime versions. Engineering teams establish standardized deployment workflows that eliminate manual configuration steps and reduce human error during routine updates. The resulting operational maturity allows developers to focus on feature development rather than infrastructure maintenance.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.









Comments (0)