Google Releases Free Local Processing Voice Transcription App
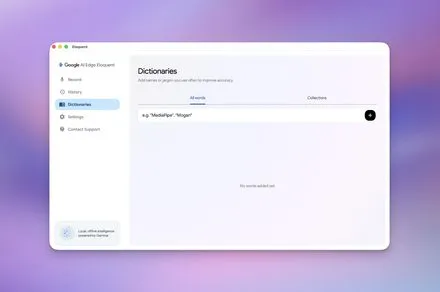
Google has released Google AI Edge Eloquent for macOS, offering free on-device voice transcription powered by local artificial intelligence models. By processing audio directly on the computer rather than sending it to remote servers, the application addresses growing privacy concerns while eliminating subscription costs that currently dominate the dictation software market.
Voice transcription technology has undergone a quiet revolution over the past decade. What began as rudimentary speech-to-text utilities has evolved into sophisticated artificial intelligence systems capable of capturing nuance, filtering background noise, and formatting output for professional use. For years, consumers have accepted that high-quality dictation requires a monthly subscription fee to access advanced features like real-time editing and cloud synchronization. The recent arrival of a new utility from Google challenges this established economic model by offering premium capabilities without requiring ongoing payments.
Google has released Google AI Edge Eloquent for macOS, offering free on-device voice transcription powered by local artificial intelligence models. By processing audio directly on the computer rather than sending it to remote servers, the application addresses growing privacy concerns while eliminating subscription costs that currently dominate the dictation software market.
What is Google AI Edge Eloquent?
The application represents a strategic shift in how major technology companies approach utility software distribution. Previously introduced to iOS devices, the macOS version extends its functionality to desktop workflows where professionals and students typically manage longer dictation sessions. The core function remains consistent across platforms: capturing spoken audio, converting it into written text, and applying algorithmic adjustments to remove conversational fillers while polishing sentence structure for immediate readability.
Unlike traditional dictation tools that require constant internet connectivity, this utility operates entirely within the local operating environment. Users download specific artificial intelligence models directly onto their storage drives before initiating any recording session. This architectural decision fundamentally alters how voice data is handled during active use. The software captures microphone input, processes it through localized neural networks, and outputs formatted text without establishing external network connections for computational purposes.
The interface allows users to select from predefined writing styles that adjust tone, formality, and pacing according to their preference. A dictionary management system enables the addition of specialized terminology, proper nouns, or industry-specific jargon that standard models might otherwise misinterpret. This customization capability addresses a common frustration among professionals who regularly dictate technical documents or legal correspondence where precise vocabulary matters significantly.
The absence of an Android counterpart remains a notable gap in the current ecosystem. Industry observers frequently note that mobile platform prioritization often dictates feature availability across different operating systems. Until the company addresses this discrepancy, users on alternative mobile ecosystems will continue relying on third-party alternatives or waiting for future development cycles to align desktop and mobile capabilities.
How Does On-Device Processing Change the Privacy Landscape?
Data sovereignty has become a central concern for consumers who regularly dictate sensitive information. Cloud-based transcription services historically require audio streams to travel across networks, pass through multiple server clusters, and undergo processing before returning results to the original device. This architecture creates potential exposure points where personal conversations could theoretically be intercepted or stored indefinitely by third-party infrastructure providers.
Local processing eliminates this transmission requirement entirely. When computational work occurs directly on the hardware using downloaded models, audio data never leaves the physical machine during active dictation sessions. This approach aligns with growing regulatory frameworks that emphasize minimizing data collection and reducing unnecessary network exposure. Organizations handling confidential information often mandate such restrictions to maintain compliance with internal security policies and industry standards. Similar concerns have emerged across the broader voice technology sector, where researchers examine how conversational interfaces handle sensitive user data without compromising security protocols.
The technical implementation relies on optimized neural network architectures designed for efficiency without sacrificing accuracy. Modern edge computing capabilities allow sophisticated language models to run smoothly on consumer-grade processors while maintaining low latency during transcription tasks. This balance between performance and resource consumption demonstrates how artificial intelligence has matured beyond requiring massive data center infrastructure for everyday utility applications.
Privacy advocates have long argued that continuous cloud synchronization creates unnecessary surveillance vectors even when companies claim to anonymize data streams. Eliminating remote processing removes the incentive to retain conversation logs for model training or service improvement purposes. Users gain direct control over their digital footprint without needing to navigate complex privacy settings or disable telemetry features that often complicate standard software usage.
Why Does This Matter for Paid Subscription Services?
The commercial transcription industry has operated on a subscription-based economic model for over a decade. Companies charge monthly or annual fees to access features that were once considered premium, including real-time editing, advanced formatting controls, and specialized vocabulary management. This pricing structure assumes that continuous server maintenance, cloud storage allocation, and ongoing artificial intelligence development require recurring revenue streams to sustain operations.
A free alternative offering comparable capabilities disrupts this established financial framework. When core functionalities become accessible without payment, consumers naturally question the value proposition of paid competitors. The market must now justify subscription costs through additional services such as cross-platform synchronization, collaborative editing features, or enterprise-grade security compliance rather than basic transcription accuracy alone.
This shift reflects a broader industry trend toward freemium and open-access distribution models for utility software. Technology companies increasingly view foundational tools as customer acquisition channels rather than direct revenue generators. By providing high-quality dictation capabilities at no cost, developers can focus on building user loyalty while exploring alternative monetization strategies through integrated ecosystems or complementary premium offerings.
Established competitors will likely respond by refining their value propositions and emphasizing features that local processing cannot easily replicate. Advanced cloud synchronization across multiple devices, specialized industry templates, and enterprise compliance certifications remain difficult to implement effectively within constrained offline environments. The market differentiation will increasingly depend on service quality rather than feature availability alone.
What Are the Practical Limitations of a Free Tool?
Local processing introduces specific hardware requirements that may not suit every computing environment. Running sophisticated artificial intelligence models directly on consumer devices demands substantial storage capacity and processing power to maintain smooth performance during extended dictation sessions. Older computers or systems with limited memory may experience noticeable slowdowns when managing large language model operations alongside standard productivity applications.
Network connectivity remains necessary for initial software installation and periodic model updates, even though active transcription does not require external connections. Users must also manage storage allocation carefully as artificial intelligence models continue to evolve and expand in complexity. Regular maintenance becomes part of the workflow rather than an automated background process handled by subscription-based service providers.
The accuracy of local transcription depends heavily on the quality of downloaded models and their alignment with specific dialects, accents, and technical terminology. While customization dictionaries help address vocabulary gaps, users may still encounter inconsistencies when processing highly specialized content or complex sentence structures. Continuous model improvements will gradually narrow this performance gap over time.
Support infrastructure also differs significantly between free utility applications and commercial subscription services. Users relying on standalone tools must troubleshoot technical issues independently rather than accessing dedicated customer support teams. Documentation quality, community forums, and peer-to-peer guidance become essential resources for resolving configuration challenges or optimizing performance settings.
What Does This Mean for Future Voice Technology?
The intersection of artificial intelligence and everyday productivity tools continues to reshape how professionals approach documentation workflows. Voice input has transitioned from a novelty feature to an essential component of modern computing environments. As local processing capabilities improve, the distinction between cloud-dependent services and offline utilities will increasingly depend on specific use cases rather than fundamental technological limitations.
Educational institutions and research organizations may particularly benefit from privacy-focused dictation solutions that comply with strict data handling regulations. Students working on sensitive projects or researchers managing confidential interview recordings can utilize local processing without navigating complex institutional approval processes for cloud service integration. This accessibility could accelerate the adoption of voice-to-text workflows across academic environments. Workplace hardware initiatives are also exploring similar localized processing architectures to ensure that professional communication tools operate securely within corporate networks.
The broader implications extend beyond individual productivity to address systemic concerns about data collection practices and digital privacy rights. When foundational tools operate independently of remote servers, users retain greater autonomy over their personal information while maintaining access to advanced computational capabilities. This model demonstrates how technology companies can deliver premium functionality without compromising user control or requiring ongoing financial commitments.
Conclusion
The arrival of a free, locally processed dictation application marks a significant turning point in utility software distribution strategies. Consumers who previously accepted subscription fees as unavoidable costs now have viable alternatives that prioritize privacy and direct hardware utilization. As artificial intelligence models continue optimizing for edge computing environments, the industry will face increasing pressure to justify recurring payments through genuine service enhancements rather than feature gating. The long-term impact will depend on how established providers adapt their business models while users evaluate whether convenience or cost efficiency better serves their specific workflows.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)