Log Scales and Pearson Correlation in Custom Scatter Plot Tools
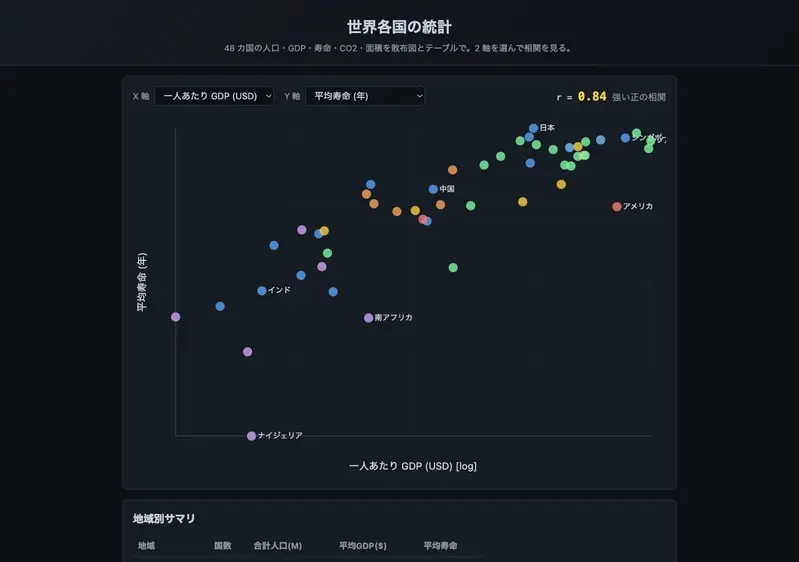
This article examines a custom-built scatter plot explorer designed to analyze global statistics across forty-eight nations. The tool demonstrates why logarithmic scaling prevents data collapse, how hand-rolled Pearson correlation captures true statistical relationships, and why rigorous testing ensures mathematical accuracy in web-based data visualization.
Global statistics present a unique visualization challenge that standard charting libraries often overlook. When analysts attempt to plot economic and demographic data across diverse nations, the sheer disparity in scale frequently obscures meaningful patterns. A recent open-source implementation addresses this problem by constructing a custom scatter plot explorer from scratch. The project demonstrates how deliberate architectural choices regarding scaling, correlation calculation, and coordinate mapping can reveal hidden relationships in cross-national datasets.
This article examines a custom-built scatter plot explorer designed to analyze global statistics across forty-eight nations. The tool demonstrates why logarithmic scaling prevents data collapse, how hand-rolled Pearson correlation captures true statistical relationships, and why rigorous testing ensures mathematical accuracy in web-based data visualization.
Why do standard axes fail when comparing global metrics?
Traditional linear axes assume uniform distribution across all data ranges. This assumption breaks down completely when measuring variables that span multiple orders of magnitude. Population figures, for instance, can differ by factors exceeding two hundred fifty between the smallest and largest nations in a dataset. Gross domestic product per capita often varies by a factor of one hundred across the same group. Linear scaling forces these extreme values to compete for the same pixel space.
The immediate consequence of this mathematical mismatch is severe data collapse. Nearly every data point clusters tightly into the bottom-left corner of the visualization. Only the absolute largest economies or most populous nations manage to stretch toward the visible edges of the chart. This compression destroys the visual resolution required for comparative analysis. Researchers cannot distinguish between medium-sized economies or identify subtle demographic trends when the chart becomes a dense, unreadable mass.
Logarithmic transformation resolves this structural flaw by equalizing spacing per order of magnitude. Instead of treating a difference of one thousand units as equivalent to a difference of one hundred thousand units, the log scale treats multiplicative steps as additive steps. This approach ensures that countries with wildly different absolute sizes share the same visual viewport. The geometric mean naturally aligns with the center of the chart, providing a balanced reference point for comparative analysis.
The distinction between linear and logarithmic metrics requires careful configuration. Variables like life expectancy typically span a narrow range of roughly thirty years across all nations. Plotting this data on a logarithmic axis would distort the actual variance and misrepresent the underlying distribution. Developers must explicitly flag which metrics require log transformation and which must remain linear. This binary configuration directly dictates how the underlying normalization function processes incoming values.
How does log transformation preserve data integrity?
Implementing logarithmic normalization requires precise mathematical handling to avoid computational errors. The normalization function calculates the base ten logarithm of the input value and compares it against the domain minimum and maximum. It then maps the result to a normalized range between zero and one. This process ensures that every data point receives a proportional position regardless of its absolute magnitude. The algorithm must also handle edge cases where the domain minimum equals the maximum.
Testing this normalization layer demands strict assertions about mathematical boundaries. A geometric midpoint must always map exactly to the center of the normalized range. Developers verify this by feeding a known geometric mean into the function and confirming the output matches the expected value within a negligible floating-point tolerance. This verification step prevents subtle scaling errors from propagating through the entire visualization pipeline.
Data positivity serves as a strict precondition for logarithmic processing. The base ten logarithm of zero yields negative infinity, while negative inputs produce undefined results. Any dataset containing zero or negative values will immediately corrupt the visualization layer. Automated integrity checks must verify that every metric field remains strictly positive before any mathematical operations begin. This validation step protects the application from runtime errors and ensures consistent rendering across all country records.
What makes a hand-rolled correlation coefficient necessary?
Standard statistical libraries often abstract away the underlying mathematics of correlation calculation. Building a Pearson correlation coefficient from first principles provides complete control over edge cases and computational behavior. The algorithm computes the mean of both datasets, calculates the deviations from those means, and aggregates the products of those deviations. The denominator multiplies the square roots of the individual variance sums. This direct implementation eliminates dependency overhead and allows for live recomputation as users switch axes.
Returning null for zero variance cases proves essential for maintaining visual accuracy. When a dataset contains identical values across all records, the denominator becomes zero. Attempting to divide by zero produces a not-a-number result that would corrupt axis labels and break downstream rendering logic. Explicitly returning null allows the interface to gracefully handle undefined relationships without displaying misleading numerical artifacts. This defensive programming practice keeps the visualization stable during rapid user interaction.
The mathematical definition of Pearson correlation measures only linear relationships. A symmetric V-shape or a perfect parabola will yield a correlation coefficient near zero despite exhibiting a strong deterministic relationship. Developers must document this limitation clearly to prevent misinterpretation. The tool includes specific test cases that verify zero correlation for non-linear patterns. This documentation ensures users understand that a null result indicates a lack of linear association, not a lack of any association.
Correlating data on a logarithmic scale reveals power-law relationships that linear correlation misses. Economic and demographic variables frequently follow exponential growth patterns that appear curved on standard axes. Transforming both axes into logarithmic space straightens these curves into linear relationships. The Pearson coefficient then accurately measures the strength of the underlying association. This approach reproduces the famous Preston curve, which demonstrates a strong positive correlation between income levels and longevity.
How does coordinate mapping affect visual accuracy?
SVG coordinate systems originate at the top-left corner of the rendering canvas. This mathematical convention means that higher numerical values naturally render lower on the screen. Standard charting libraries automatically invert the Y-axis to match human reading habits, but custom implementations require explicit inversion logic. The normalization function must subtract the calculated Y value from one to flip the coordinate system correctly. This simple mathematical adjustment ensures that taller bars and higher values visually ascend toward the top of the chart.
Verifying coordinate inversion requires targeted assertions that compare actual data values against rendered positions. The test suite identifies the record with the highest metric value and confirms that its corresponding Y coordinate is the smallest number in the dataset. All other records must possess Y coordinates that are greater than or equal to this minimum value. This verification step guarantees that the visual representation accurately mirrors the underlying data hierarchy without accidental inversion errors.
Domain scaling must account for the full range of available data points. The normalization function requires explicit minimum and maximum values for both axes to establish the mapping boundaries. These boundaries shift dynamically as users select different metrics or filter the country pool. The application must recalculate these domains before computing normalized coordinates. Failing to update the domain boundaries results in points plotting outside the visible canvas or clustering incorrectly within the available space.
What architectural principles support reliable statistical exploration?
Separating data storage from computational logic creates a maintainable and testable architecture. The dataset resides in a dedicated module containing country names, codes, regions, and metric values sourced from the World Bank and the United Nations. The core computation layer handles normalization, correlation calculation, and coordinate mapping without direct DOM manipulation. The application layer manages SVG rendering and user interaction. This separation allows developers to run extensive unit tests against the mathematical layer without requiring a browser environment.
Rigorous testing forms the foundation of any statistical tool. The computation layer includes thirty-four automated tests that verify mathematical correctness, edge case handling, and data integrity. These tests cover perfect positive correlation, zero correlation scenarios, undefined variance cases, and geometric midpoint alignment. The test suite also validates that no duplicate ISO codes exist and that all metric fields remain within expected ranges. This comprehensive coverage prevents regression bugs when modifying the underlying algorithms.
Choosing vanilla JavaScript over heavy charting libraries reduces bundle size and increases transparency. Developers can inspect every line of code to understand exactly how data transforms from raw numbers into visual elements. This transparency builds trust with users who need to verify the mathematical accuracy of their analyses. The approach also simplifies deployment and improves performance on slower network connections. The resulting tool remains lightweight while delivering professional-grade analytical capabilities.
The broader implications of this implementation extend beyond technical architecture. Custom-built analytical tools empower researchers to explore complex datasets without relying on proprietary software. Open-source statistical explorers democratize access to data visualization techniques that were previously reserved for specialized institutions. By documenting the mathematical foundations and testing strategies, developers provide a reusable blueprint for future projects. This transparency accelerates innovation in data science and encourages rigorous validation practices across the industry.
What lessons emerge for developers building analytical tools?
Scaling decisions dictate the entire success of a data visualization project. Developers must evaluate the mathematical distribution of every variable before choosing an axis type. Logarithmic scaling prevents data collapse but requires strict positivity constraints and careful domain boundary management. Linear scaling preserves intuitive interpretation but fails completely when metrics span multiple orders of magnitude. Understanding these tradeoffs allows engineers to select the appropriate transformation for each specific dataset.
Correlation calculation demands explicit handling of mathematical edge cases. Returning null for undefined variance prevents downstream rendering failures and maintains interface stability. Documenting the linear limitation of Pearson correlation prevents users from misinterpreting non-linear relationships. These defensive programming practices ensure that statistical tools remain reliable under rapid user interaction. Developers who prioritize mathematical correctness over convenience build more robust and trustworthy applications.
Coordinate mapping requires careful alignment between mathematical models and rendering conventions. SVG origin inversion must be applied consistently to match human reading expectations. Dynamic domain recalculation ensures that points remain visible when users switch metrics or filter datasets. These seemingly minor implementation details accumulate into a polished and professional user experience. Attention to these technical nuances separates functional prototypes from production-ready analytical software.
Conclusion
Custom statistical explorers demonstrate how deliberate engineering choices can transform raw numbers into meaningful insights. The combination of logarithmic scaling, precise correlation calculation, and rigorous testing creates a reliable foundation for cross-national analysis. Developers who prioritize mathematical accuracy and transparent architecture build tools that withstand scrutiny and empower independent research. The future of data visualization depends on open, verifiable implementations that prioritize clarity over convenience.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)