Resolving Hypervisor Error on Windows 11: A Technical Guide
The hypervisor error on Windows 11 usually indicates a conflict between system files, virtualization settings, or hardware components. Resolving the issue requires a systematic approach that includes restarting the system, adjusting hypervisor platform settings, verifying memory integrity, repairing file system corruption, updating the operating environment, and, if necessary, performing a complete system reset.
The appearance of a stop code during system boot or heavy processing often signals a fundamental conflict within the operating environment. Users encountering a hypervisor error on Windows 11 frequently face a sudden system halt that interrupts workflow and raises concerns about underlying hardware or software integrity. This specific blue screen event typically stems from how the operating system manages virtualization resources, memory allocation, or core system files. Understanding the technical mechanisms behind this disruption allows administrators and everyday users to apply targeted corrections without unnecessary guesswork.
What is a Hypervisor Error and Why Does It Occur?
The hypervisor serves as a critical layer in modern computing architectures, responsible for managing virtual machine resources and isolating different operating environments. When Windows 11 encounters a stop code related to this component, it typically indicates that the system files governing Hyper-V settings have developed a conflict. This disruption can manifest due to incorrect virtualization configurations, corrupted system files, outdated device drivers, or faulty random access memory. The operating system halts operations to prevent data corruption when it detects that the virtualization layer cannot maintain stable communication with the underlying hardware. Recognizing these root causes provides a clear pathway for troubleshooting and restoration of normal system functionality.
Virtualization technology has evolved significantly over the past two decades, transitioning from niche enterprise tools to standard desktop features. Microsoft integrated Hyper-V directly into the Windows kernel to provide native hardware-assisted virtualization capabilities. When the operating system attempts to allocate memory or processor cycles to this virtualization layer, conflicts can arise if the underlying hardware drivers or system files are misaligned. The stop code functions as a safety mechanism, halting the system to prevent irreversible data corruption. Recognizing the architectural purpose of this error helps users approach troubleshooting with the correct technical mindset.
How to Diagnose and Resolve the Issue
Addressing a virtualization stop code requires a methodical approach that isolates potential failure points. The following procedures outline the standard diagnostic and corrective measures recommended by system engineers. Each step targets a specific layer of the computing stack, from basic system state restoration to deep file integrity verification. Administrators should follow these instructions in the exact order presented to ensure that simpler solutions are exhausted before attempting more invasive recovery methods.
The diagnostic process follows a logical progression from simple state resets to complex file repairs. Each procedure targets a specific layer of the computing stack, ensuring that administrators address the most common causes before moving to invasive recovery methods. Skipping steps often leads to recurring errors because the root cause remains unaddressed. System engineers recommend documenting each action taken during the troubleshooting process. This documentation proves valuable if the issue requires escalation to technical support or further hardware analysis.
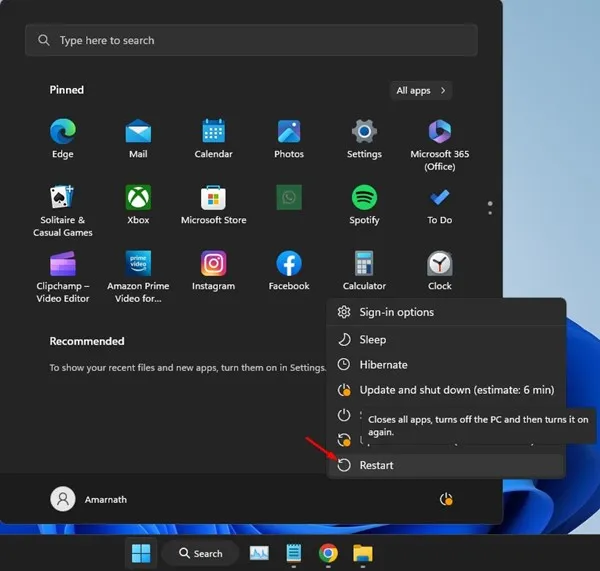
Step 1: Restarting the System
A fundamental recovery procedure involves initiating a complete system restart. This action forces the operating environment to reload pending updates and clear temporary memory states that may be causing software conflicts. Users should access the power menu through the start interface and select the restart option. Once the machine boots back into the desktop environment, administrators can proceed with more advanced diagnostic procedures. This initial step often resolves transient glitches that interfere with normal virtualization processes.
A complete power cycle clears volatile memory registers that may hold conflicting instructions. The operating system uses these registers to manage temporary processes and pending update installations. When a restart occurs, the kernel reloads all core drivers and initializes the virtualization stack from a clean state. This process eliminates software conflicts that develop during extended uptime periods. Users should verify that all open applications are properly closed before initiating the power cycle. This precaution prevents data loss and ensures a smooth transition to the diagnostic phase.
Step 2: Disabling the Hypervisor Platform
Systems that do not require virtual machine functionality may experience conflicts when the hypervisor platform remains active. Disabling this feature can eliminate the stop code by removing the conflicting virtualization layer. Users should navigate to the control panel and select the programs section. From there, they must access the option to turn Windows features on or off. Locating the Windows Hypervisor Platform and unchecking the box will deactivate the feature. After applying the changes, a system restart is required to finalize the configuration shift.
The Windows Hypervisor Platform enables third-party virtualization software to interact with the operating system. Systems that do not run virtual machines or containerized applications often experience unnecessary conflicts when this feature remains active. Disabling the platform removes the communication bridge that triggers the stop code. Administrators should verify that no dependent applications require virtualization support before making this change. The configuration shift takes effect only after the system reboots. This step effectively isolates the virtualization layer from the standard operating environment.
Step 3: Restarting Hyper-V Services
The virtualization infrastructure relies on several background services to maintain stable operation. When these services encounter a state mismatch, the system may trigger a stop code. Administrators should open the services application and locate all entries associated with Hyper-V. Each service must be manually restarted by selecting the restart command from the context menu. If the restart option is unavailable, stopping the service first and then starting it again will force a clean initialization. Repeating this process across all related services ensures a consistent state.
Background services manage the continuous operation of virtualization components. These services monitor hardware resources and allocate processing power to virtual environments. When a service encounters a memory leak or configuration mismatch, it may fail to communicate with the kernel. Manually restarting each service forces the operating system to reload the associated configuration files. Administrators should verify that each service transitions to a running state before proceeding to the next entry. Consistent service operation is essential for maintaining stable virtualization performance.
Step 4: Ruling Out Memory Failures
Faulty random access memory is a prominent contributor to virtualization stop codes. The operating system depends on stable memory pathways to manage hypervisor operations, and damaged hardware can cause immediate system halts. Before initiating diagnostics, users should save all active work to prevent data loss. The Windows Memory Diagnostic tool can be launched through the search interface to begin the hardware verification process. Selecting the option to restart and check for problems will initiate a full memory scan during the boot sequence. Results will appear in a system notification after the machine returns to the desktop.
Random access memory serves as the primary pathway for data exchange between the processor and system files. Damaged memory modules can corrupt the instructions sent to the hypervisor, triggering immediate system halts. The diagnostic tool performs a comprehensive scan of every memory address during the boot sequence. This process identifies physical defects that standard software utilities cannot detect. Users should allow the scan to complete without interrupting the power supply. The resulting report provides definitive evidence of hardware integrity or failure.
Step 5: Checking Drive File System Integrity
File system corruption on the primary installation drive can disrupt virtualization processes and trigger unexpected stop codes. The operating system relies on a healthy file allocation table to manage system resources, and errors in this structure can cause critical failures. Users should open the file explorer and access the properties menu for the Windows installation drive. Switching to the tools tab reveals the error checking section, which contains a scan drive button. Executing this scan will identify and attempt to repair file system inconsistencies that may be interfering with system stability.
The file allocation table directs the operating system to the precise location of every system file. Corruption within this structure can cause the virtualization layer to request resources from invalid addresses. The error checking utility scans the drive for logical inconsistencies and attempts automatic repairs. This process rebuilds the directory structure and restores proper file routing. Administrators should monitor the scan progress to ensure it completes without interruption. A healthy file system is a prerequisite for stable virtualization operations.
Step 6: Running the Deployment Image Servicing Tool
Corrupted system files often require deep-level repair that standard utilities cannot address. The Deployment Image Servicing and Management utility provides a command-line interface for restoring the health of the Windows component store. Administrators must open the command prompt with elevated privileges to execute system-level commands. Running the restoration health command will initiate a comprehensive scan of the operating environment. The process compares current files against a known good state and replaces damaged components. Waiting for the scan to complete before restarting ensures that all repairs are properly applied.
The component store maintains backup copies of core operating files to enable automatic repairs. When these backup files become corrupted, the system loses its ability to restore damaged components. The servicing utility compares the current file state against the known good baseline and replaces any discrepancies. This process requires administrative privileges to access protected system directories. Users should allow the utility to complete its verification cycle before closing the command interface. Successful execution often resolves deep-seated file corruption issues.
Step 7: Updating the Operating System
Outdated system builds frequently contain unresolved bugs that conflict with virtualization features. Microsoft regularly releases updates that address compatibility issues and improve system stability. Users should navigate to the settings interface and select the Windows update section. Initiating a check for updates will prompt the system to download and install any available patches. Installing these updates ensures that the operating environment includes the latest fixes for known virtualization conflicts. This step should be performed after completing previous diagnostic procedures to maintain a clean baseline.
Software updates contain critical patches that address known compatibility issues between the kernel and virtualization drivers. Microsoft regularly releases cumulative updates that improve system stability and resolve driver conflicts. The update manager verifies digital signatures before installing any new components. This verification process ensures that only authorized files modify the operating environment. Users should connect to a stable network connection before initiating the update process. Installing the latest patches aligns the system with current virtualization standards.
Step 8: Performing a System Reset
When all other troubleshooting methods fail, resetting the operating environment becomes the final recovery option. This procedure reinstalls the core system files while preserving user data. Administrators should access the recovery settings through the system configuration menu. Selecting the reset option will launch the recovery wizard, which prompts users to choose between keeping personal files or removing everything. Choosing to keep files ensures that documents and settings remain intact during the reinstallation. Users must then select between a cloud download or a local reinstall before confirming the reset. The process requires patience, as interrupting the installation can cause further system damage.
A system reset reinstalls the core operating files while preserving user data and applications. This procedure rebuilds the virtualization stack from a factory baseline configuration. Administrators should choose the cloud download option to ensure the installation uses the latest system files. Local reinstalls may utilize older cached files that could perpetuate the original conflict. The recovery wizard guides users through each configuration step to prevent accidental data loss. This final measure restores the system to a known stable state.
What Are the Long-Term Implications of Virtualization Errors?
Persistent virtualization stop codes often indicate deeper architectural conflicts that require careful management. The hypervisor layer plays a crucial role in modern computing, enabling resource isolation and secure execution environments. When this layer fails, it can disrupt not only system stability but also the functionality of dependent applications. Users who rely on virtualization tools should monitor system logs to identify recurring triggers. Implementing regular maintenance schedules and keeping drivers updated can prevent future conflicts. Understanding the underlying mechanics of these errors empowers administrators to maintain robust computing environments without unnecessary downtime.
Virtualization technology continues to expand across desktop and enterprise environments, making system stability increasingly critical. Persistent stop codes indicate that the operating environment cannot maintain the required resource isolation. Users who ignore these errors risk progressive hardware degradation and data corruption. Regular maintenance and proactive monitoring prevent minor conflicts from escalating into major system failures. Understanding the architectural dependencies of the hypervisor layer empowers administrators to maintain robust computing environments. Continuous monitoring ensures that virtualization resources operate within safe parameters.
Conclusion
Resolving a hypervisor stop code requires patience and a systematic approach to troubleshooting. By following established diagnostic procedures, users can isolate the specific component causing the conflict and apply targeted corrections. The operating environment relies on precise coordination between hardware, drivers, and system files to maintain stability. Addressing these issues promptly ensures that computing resources remain available for daily tasks. Maintaining regular system updates and monitoring hardware health will reduce the likelihood of future disruptions.
System administrators should treat virtualization errors as indicators of underlying architectural stress rather than isolated software glitches. Implementing routine health checks and maintaining updated driver ecosystems significantly reduces the probability of recurrence. The structured diagnostic methodology outlined above provides a reliable framework for restoring system integrity. Users who apply these corrections systematically will preserve both data security and operational continuity.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)