Apple Intelligence Voice Control Preview Signals iOS 27 Siri Overhaul
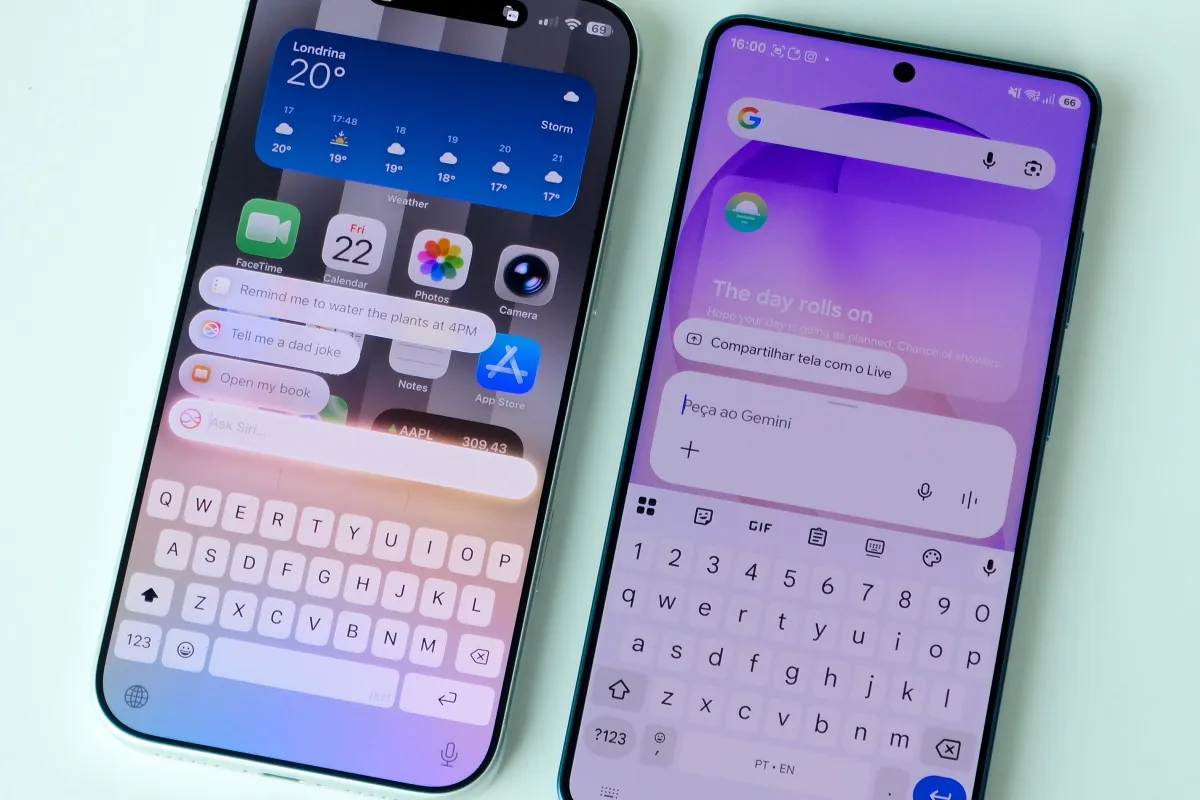
Apple has unveiled a new Voice Control feature powered by Apple Intelligence, enabling natural voice commands like tapping specific on-screen elements. This accessibility enhancement serves as a preview for iOS 27’s upgraded Siri, which promises contextual understanding and agentic capabilities. The technology represents a significant shift in mobile interaction, potentially transforming how users navigate devices and control applications through conversational speech.
What is the new Voice Control feature?
Apple recently provided a glimpse into the next generation of mobile interaction during its annual accessibility preview ahead of the Worldwide Developers Conference. The company introduced a significantly upgraded version of Voice Control that leverages Apple Intelligence to interpret natural language commands. Rather than requiring users to memorize rigid syntax or specific trigger phrases, the updated system allows individuals to speak in a conversational manner while navigating their devices. This announcement has generated considerable discussion within the technology sector regarding the future direction of mobile operating systems and artificial intelligence integration.
Apple has unveiled a new Voice Control feature powered by Apple Intelligence, enabling natural voice commands like tapping specific on-screen elements. This accessibility enhancement serves as a preview for iOS 27’s upgraded Siri, which promises contextual understanding and agentic capabilities. The technology represents a significant shift in mobile interaction, potentially transforming how users navigate devices and control applications through conversational speech.
The core innovation behind this update lies in its ability to process visual context in real time. Traditional voice assistants relied heavily on predefined command lists and exact phonetic matches to execute tasks. The new architecture utilizes machine learning models to identify interface elements, map their spatial relationships, and interpret user intent based on surrounding visual data. This allows the system to respond to requests such as opening a specific folder or zooming into a document section without requiring precise menu navigation paths.
Accessibility remains the primary driver for this technological advancement. Apple has consistently emphasized that tools designed to assist users with motor or visual impairments often yield benefits for the broader user base. When interface elements lack proper semantic labels, standard assistive technologies frequently fail to recognize them. By training models to understand visual layouts alongside spoken language, the system can bypass missing metadata and execute commands based on what is actually displayed on the screen.
How does Apple Intelligence reshape on-screen navigation?
This development aligns with a well-documented pattern in mobile operating system design. Historically, Apple has utilized accessibility initiatives as foundational testing grounds for features that eventually become mainstream. AssistiveTouch began as a solution for users with limited motor control before becoming a standard navigation aid. Live Captions and real-time text transcription started as accessibility tools and are now integrated across all first-party applications. Mouse and trackpad support followed a similar trajectory, fundamentally changing how desktop and mobile devices are operated.
The technical requirements for this type of system are considerable. Processing visual data and natural language simultaneously demands significant on-device computational resources. Apple has been developing custom silicon architecture specifically to handle these workloads efficiently while maintaining battery life and thermal management. The integration of Apple Intelligence models directly into the operating system core allows for low-latency responses and ensures that personal data remains processed locally rather than relying on cloud-based inference.
The underlying architecture for contextual voice control requires a fundamental rethinking of how operating systems interpret user input. Traditional speech recognition pipelines convert audio waves into phonetic strings before searching command databases. The new approach utilizes multimodal models that process visual frames and audio simultaneously. This allows the system to correlate spoken phrases with on-screen coordinates and interface states. The computational pipeline must handle real-time inference without introducing perceptible latency to the user experience.
Why does this matter for the future of Siri?
The implications for the upcoming iOS 27 release are substantial. Industry analysts and developers have long anticipated an overhaul of the built-in digital assistant to incorporate agentic capabilities. Current implementations require users to initiate specific workflows through explicit commands or app shortcuts. The upcoming architecture appears designed to understand on-screen context, execute tasks across multiple applications, and manage complex sequences without constant user intervention. This shift moves the interface from a reactive command line to a proactive contextual manager.
Voice interfaces have undergone multiple evolutionary cycles since their initial introduction. Early implementations relied on rigid grammar trees and fixed vocabulary lists to minimize recognition errors. Subsequent iterations introduced continuous speech recognition and natural language processing to improve usability. The current generation represents a third major shift, moving away from command-and-control paradigms toward intent-based interaction. This progression mirrors broader trends in human-computer interaction research, which consistently prioritizes reducing cognitive load during device operation.
The widespread adoption of contextual voice control will necessitate significant adjustments across the developer ecosystem. Application teams must ensure that their interfaces maintain consistent semantic structures regardless of layout variations or dynamic content updates. Framework updates will likely include standardized metadata schemas that allow system-level models to accurately map spoken requests to specific UI components. Third-party developers will need to test their applications against the new accessibility standards to ensure full compatibility with the updated navigation layer.
How does this compare to competitor implementations?
Competitor implementations have already demonstrated the viability of this approach. Samsung recently updated its Voice Access feature on the Galaxy S26 Ultra to include artificial intelligence models capable of natural language navigation. Users can open applications, scroll through content, and interact with specific interface elements using conversational speech. The feature operates independently of traditional voice assistant frameworks, functioning as a direct overlay for screen control. This parallel development suggests a broader industry shift toward context-aware voice interfaces.
The current state of artificial intelligence features on mobile devices often draws criticism for its limited scope. Existing tools primarily focus on content generation, text summarization, and image manipulation. While these functions provide occasional convenience, they do not fundamentally alter how users interact with their operating systems. A truly contextual voice interface would bridge the gap between information retrieval and task execution, allowing users to accomplish complex workflows through simple conversational requests rather than manual navigation.
Security and privacy considerations remain paramount as voice interfaces gain deeper system access. Automated task execution requires robust authentication mechanisms to prevent unauthorized operations. The system will likely implement contextual verification steps for sensitive actions, such as financial transactions or data modification. Users will retain control over which applications can respond to voice commands and under what conditions. Transparent logging and permission management interfaces will be essential for maintaining user trust in automated workflows.
What are the practical implications for everyday users?
The transition to natural language control will require significant adjustments to user expectations and interface design. Developers will need to ensure that applications maintain robust semantic structures even when visual layouts change. System-wide accessibility standards will likely evolve to accommodate context-aware processing. The technology also raises important considerations regarding privacy, security, and user consent for automated actions. Clear indicators and confirmation mechanisms will be necessary to prevent unintended operations in sensitive applications.
Looking ahead, the upcoming Worldwide Developers Conference keynote will likely provide additional details regarding the rollout timeline and technical specifications. The company has historically kept major interface innovations under wraps until official announcements. The preview event served primarily to highlight accessibility commitments while subtly signaling the direction of future software updates. Industry observers will closely monitor how the new architecture integrates with existing developer frameworks and third-party applications.
The broader technology industry is simultaneously pursuing similar advancements in natural language interaction. Competitors are investing heavily in multimodal foundation models capable of understanding visual context and executing cross-application tasks. The race to establish the most intuitive voice interface will likely drive rapid innovation in speech recognition, computer vision, and task planning algorithms. Companies that successfully integrate these capabilities into their operating systems will gain a significant competitive advantage in user engagement and ecosystem loyalty.
Mainstream adoption of conversational voice control will depend heavily on reliability and accuracy in diverse environments. Users expect consistent performance across different lighting conditions, background noise levels, and accent variations. The system must continuously adapt to individual speech patterns without compromising security or privacy standards. Training data collection and model refinement will play a crucial role in achieving the necessary precision for everyday use. Iterative updates will likely focus on reducing false positives and improving contextual disambiguation.
What does the future hold for mobile interaction?
The evolution of mobile interaction continues to be driven by the convergence of accessibility engineering and artificial intelligence. What began as a specialized tool for users with specific needs has gradually transformed into a foundational component of modern operating systems. The upcoming integration of contextual voice control represents a logical progression in this trajectory. As these technologies mature, they will likely redefine the boundaries between human intent and machine execution, establishing new standards for intuitive device interaction.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)