Apple Introduces Context-Aware Voice Control in iOS 27 Preview
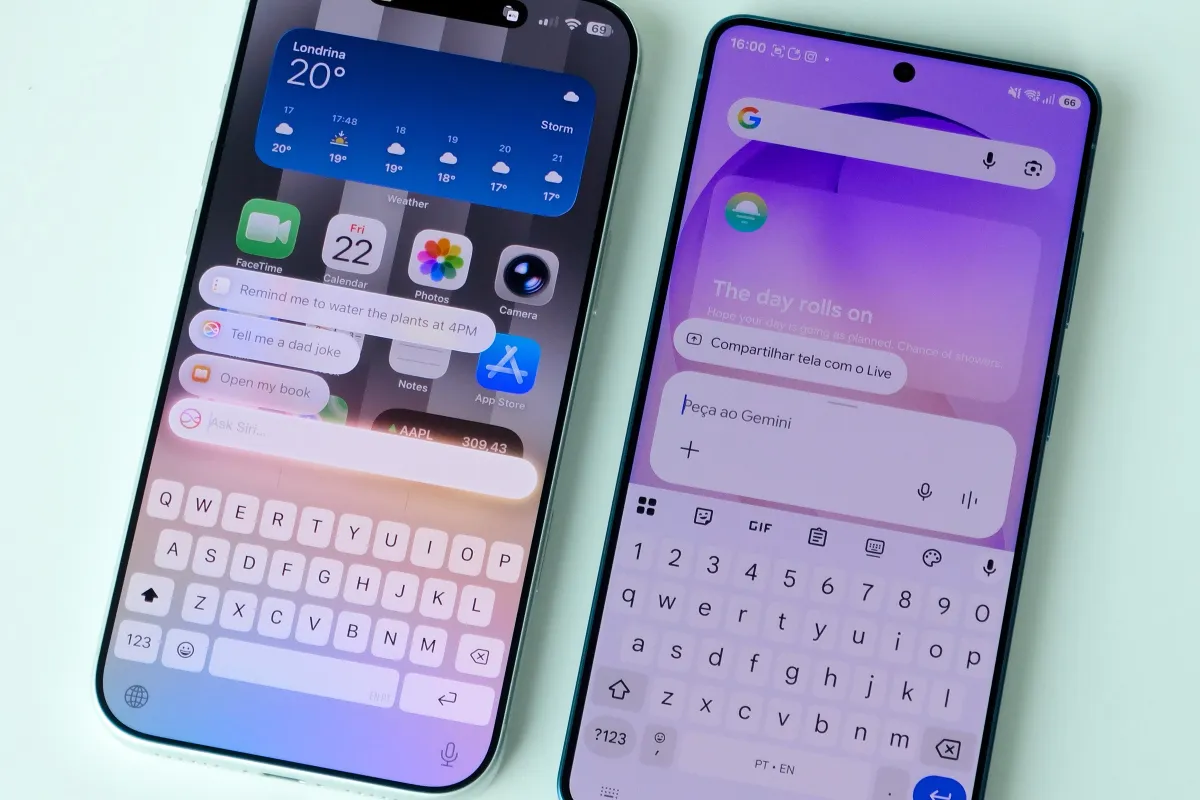
Apple previewed an upgraded Voice Control system for iOS 27 that utilizes Apple Intelligence to process natural language commands and interact with screen elements in real time. This enhancement serves as a functional prototype for next-generation assistant capabilities, bridging accessibility tools with mainstream design while addressing current conversational AI limitations.
Apple has long positioned accessibility tools as specialized utilities for users with specific physical or cognitive needs. Recent developments, however, suggest a strategic pivot toward universal interface design that prioritizes natural interaction over rigid command structures. The company recently previewed an upgraded Voice Control system powered by advanced machine learning models, signaling a fundamental shift in how mobile operating systems will interpret human speech. This development arrives just ahead of the annual Worldwide Developers Conference, where leadership is expected to unveil broader architectural changes for the upcoming software release.
Apple previewed an upgraded Voice Control system for iOS 27 that utilizes Apple Intelligence to process natural language commands and interact with screen elements in real time. This enhancement serves as a functional prototype for next-generation assistant capabilities, bridging accessibility tools with mainstream design while addressing current conversational AI limitations.
What is the new Voice Control feature?
The updated Voice Control system represents a significant departure from traditional speech recognition protocols that rely on fixed syntax and predetermined phrases. Instead of requiring users to memorize specific command sequences, the new implementation processes conversational language directly. When a user speaks naturally, the system analyzes the spoken input against the current visual layout of the device screen. This real-time contextual mapping allows the software to identify interface elements without depending on traditional accessibility labels or rigid menu structures.
Traditional voice interfaces have historically struggled with ambiguity because they lack awareness of the immediate digital environment. The new architecture resolves this limitation by continuously scanning active application windows and rendering layers. When a user requests an action, such as opening a specific folder or zooming into a document section, the system cross-references the spoken request with visual coordinates on the display. This approach eliminates the friction that previously forced users to navigate complex voice command dictionaries just to perform basic navigation tasks.
The underlying technology addresses a persistent challenge in mobile interface design: inconsistent or missing accessibility metadata across third-party applications. Many developers do not implement comprehensive labeling protocols for every interactive element within their software. By bypassing the need for explicit tags, the new system relies on visual recognition and spatial reasoning to locate targets. This method ensures that users can interact with unmarked buttons, dynamic menus, and custom interface components without encountering dead ends or unrecognized command errors.
From a technical standpoint, this capability requires substantial computational overhead to maintain real-time responsiveness while processing both audio input and visual data simultaneously. The system must render a temporary mapping of the active screen state and align it with phonetic interpretations of spoken words. This dual-processing pipeline allows the software to execute precise taps, scrolls, or selections based purely on descriptive language rather than rigid programming syntax.
Why does this matter for iOS 27 and Siri?
The previewed functionality aligns closely with long-standing industry rumors regarding the next generation of Apple Intelligence assistant architecture. Previous announcements highlighted aspirations for an agentic system capable of executing multi-step workflows across different applications without manual intervention. The current Voice Control demonstration provides a tangible glimpse into how that broader vision might operate in practice. By mastering contextual awareness and natural language interpretation within a single application window, the underlying models are being stress-tested for more complex cross-app automation tasks.
Historical patterns in mobile operating system development suggest that specialized accessibility tools frequently evolve into standard interface features over time. Early implementations of gesture navigation, dynamic text scaling, and screen reader technologies initially targeted specific user groups before becoming foundational elements of the core experience. The current Voice Control upgrade follows this established trajectory by introducing conversational interaction paradigms that will eventually benefit all users.
The transition from command-based assistants to context-aware agents represents a fundamental shift in human-computer interaction models. Users no longer need to recall exact phrases or navigate hierarchical voice menus to accomplish tasks. Instead, they can describe their intent using everyday language while the system interprets spatial relationships and application states. This approach reduces cognitive load and accelerates workflow efficiency for individuals who rely on hands-free operation.
Industry analysts have noted that competitors are already implementing similar contextual navigation capabilities within their respective ecosystems. The comparison to Samsung Galaxy S26 Ultra functionality highlights an ongoing industry race toward more intuitive speech interfaces. By previewing this technology ahead of the official developer conference, Apple is signaling its commitment to closing existing gaps in conversational AI performance across mobile platforms.
How does Apple Intelligence change voice interaction?
Current implementations of mobile artificial intelligence have faced consistent criticism regarding their functional scope and contextual awareness. Many existing tools operate as isolated utilities that generate text or summarize content without influencing the underlying operating system state. The new Voice Control architecture addresses this limitation by granting the AI models direct control over interface elements based on spoken instructions. This capability transforms passive information processing into active task execution.
The integration of advanced language models enables the system to parse ambiguous requests and infer user intent with greater accuracy. When a command lacks specific parameters, the software can analyze surrounding visual data to determine the most logical interpretation. For example, if a user requests an action involving multiple similar elements on screen, the system evaluates spatial positioning and contextual relevance before executing the tap or selection.
Practical applications extend far beyond basic navigation tasks into comprehensive workflow automation. Users can dictate detailed instructions that require the software to open specific files, adjust display settings, and transmit data to external contacts within a single conversational exchange. This multi-step execution capability eliminates the need for manual intervention between each action while maintaining state awareness throughout the process.
The underlying machine learning models also improve over time by adapting to individual speech patterns and interaction preferences. As users provide more natural language input, the software refines its contextual mapping algorithms to better anticipate desired outcomes. This continuous learning process enhances responsiveness while maintaining strict privacy boundaries that prevent raw audio data from leaving the device.
What are the broader implications for device accessibility and mainstream adoption?
The evolution of specialized interface tools into universal features demonstrates a consistent pattern in modern operating system development. Technologies originally engineered to overcome physical or cognitive barriers frequently become essential components of everyday digital interaction. AssistiveTouch, Live Captions, and external peripheral support all followed this exact developmental pathway before achieving widespread mainstream integration.
Industry competition regarding natural language processing capabilities has intensified significantly over recent years. Competing platforms have already deployed AI-driven voice interfaces that interpret contextual commands and execute complex application sequences without rigid syntax requirements. The previewed functionality positions the upcoming software release to match or exceed these existing benchmarks in accuracy and responsiveness across all supported hardware.
The widespread adoption of contextual voice control will likely reshape application design standards across the entire mobile ecosystem. Developers will need to account for AI-driven navigation patterns when constructing interface layouts and interactive elements. Traditional reliance on visual hierarchy and touch targets will gradually incorporate spatial awareness protocols that accommodate speech-based interaction methods during daily operations.
Looking ahead to the official developer conference, industry observers anticipate a comprehensive unveiling of the broader assistant architecture that underpins these capabilities. The previewed functionality serves as a functional proof-of-concept for agentic systems capable of managing cross-application workflows with minimal user guidance while maintaining strict privacy safeguards during on-device processing.
Looking Ahead to the Next Generation of Interface Design
The previewed Voice Control functionality represents a strategic stepping stone toward more autonomous mobile operating systems. By demonstrating contextual awareness and natural language processing within an accessibility framework, the company has provided a clear roadmap for upcoming assistant capabilities. Engineers will likely expand these foundational models to support complex multi-application automation while maintaining strict privacy safeguards during on-device processing.
As conversational interface technologies continue to mature, the distinction between specialized accessibility tools and standard operating system features will gradually disappear. Users will expect seamless voice-driven navigation regardless of their specific physical requirements or interaction preferences. This universal design philosophy ensures that advanced speech recognition capabilities become accessible infrastructure rather than optional add-ons.
The broader technology industry must now adapt to an environment where natural language commands replace rigid syntax requirements across all digital platforms. Developers, accessibility advocates, and interface designers will collaborate to establish new standards for spatial awareness, contextual mapping, and conversational AI integration that prioritize user intent over mechanical command structures.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)