Apple's New AI Models Exclude Google's Gemini Architecture
Apple executives confirmed that its latest foundation models utilize none of Google's Gemini assistant code, client software, or search infrastructure. The new architecture relies on custom training, proprietary data, and a hybrid cloud system designed to maintain strict privacy boundaries while delivering advanced computational capabilities.
Apple's approach to artificial intelligence has consistently emphasized a careful balance between computational power and user privacy. When the company unveiled its latest generation of foundation models, executives took the unusual step of publicly addressing the extent of external partnerships. The clarification was direct and unambiguous regarding one of the most prominent technology competitors. This deliberate transparency marks a significant moment in how major hardware manufacturers position their machine learning infrastructure.
Apple executives confirmed that its latest foundation models utilize none of Google's Gemini assistant code, client software, or search infrastructure. The new architecture relies on custom training, proprietary data, and a hybrid cloud system designed to maintain strict privacy boundaries while delivering advanced computational capabilities.
What is the architectural shift behind Apple's latest foundation models?
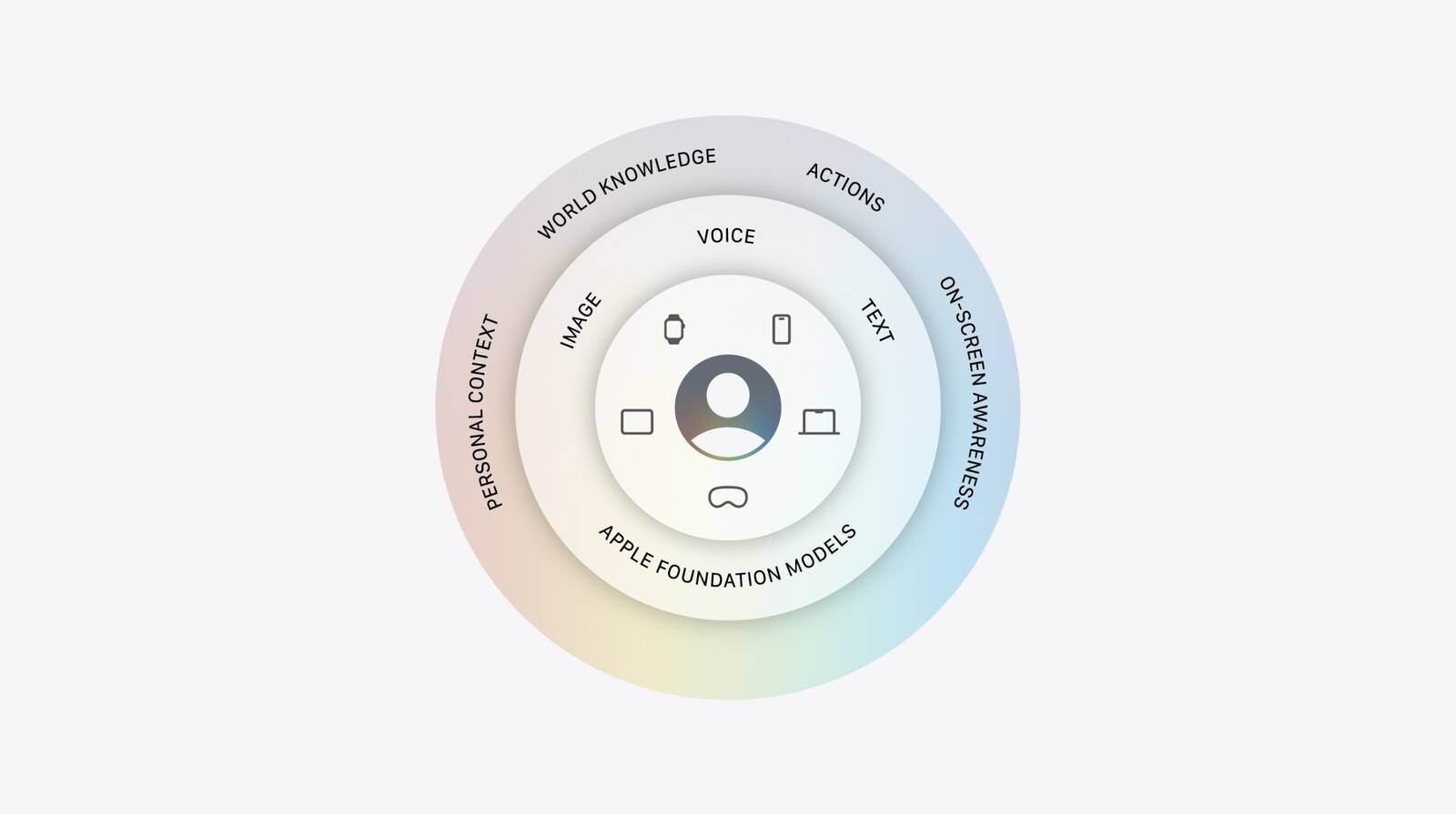
The third generation of Apple Foundation Models represents a fundamental restructuring of how the company processes machine learning tasks. Craig Federighi, Apple's senior vice president of software engineering, outlined this transition during a technical briefing alongside artificial intelligence vice president Amar Subramanya. The new framework abandons the previous reliance on external model weights for core functionality. Instead, the company has constructed a completely independent ecosystem designed specifically for its custom silicon.
This architectural decision reflects a broader industry trend where hardware manufacturers seek to reduce dependency on third-party machine learning providers. The shift also addresses long-standing concerns regarding data sovereignty and model transparency. By building the foundation from the ground up, the company ensures that every layer of the stack aligns with its established privacy standards. The new architecture does not merely update previous systems; it replaces them with a purpose-built network capable of handling increasingly complex computational demands. Historically, the company relied on external partnerships to accelerate development cycles. That strategy has now evolved into a fully independent research pipeline.
How does the new model family operate across devices and servers?
The updated model family consists of five distinct components designed to handle different computational loads. Two models operate directly on user hardware, while three function within server environments. The on-device tier includes a next-generation dense architecture model and a sparse architecture variant that supports native multimodal processing. This dual approach allows the system to handle routine tasks locally while reserving heavier computations for remote servers. The server-side components manage latency-optimized requests, image generation, and advanced spatial editing features. Each component communicates through a centralized routing mechanism that evaluates the complexity of each user query.
This distribution model ensures that sensitive personal data remains on the device whenever possible. The separation of duties between local and remote processing creates a flexible system that scales efficiently. Users experience faster response times for everyday interactions while still accessing advanced capabilities when necessary. The architecture also supports continuous improvement through iterative updates that do not require full hardware replacements. Developers can leverage these components to build applications that adapt to individual user needs. The system dynamically adjusts resource allocation based on real-time performance metrics. This approach guarantees consistent functionality across different device generations. Network independence becomes a critical advantage in areas with limited connectivity. The local processing capabilities ensure that core features remain operational regardless of external infrastructure status.
The Role of Distillation and Proprietary Training
Training these models required a highly specialized approach that diverges from standard industry practices. The development team utilized proprietary datasets to establish baseline capabilities before introducing external refinement techniques. Rather than adopting complete model weights from external providers, the company employed a distillation process. This method involves training the new architecture to replicate specific outputs generated by frontier models without inheriting their underlying code. The distillation technique allows the company to absorb advanced reasoning patterns while maintaining complete control over the final implementation.
This approach also mitigates the risk of inheriting architectural vulnerabilities or licensing restrictions. The resulting models demonstrate performance metrics that closely align with industry-leading alternatives. The training pipeline emphasizes reinforcement learning to refine accuracy and reduce hallucination rates. This meticulous process ensures that the final product meets strict quality standards without compromising independent development. Engineers carefully monitored each training cycle to verify that the system retained its intended behavioral boundaries. The outcome is a highly optimized framework that operates efficiently across diverse hardware configurations.
Why does the cloud infrastructure partnership matter for privacy?
The deployment of the most advanced model requires significant computational resources that exceed standard data center capabilities. To address this requirement, the company partnered with both a leading semiconductor manufacturer and a major cloud provider. This collaboration involved extending the private cloud compute infrastructure to utilize the latest graphics processing units. The primary concern during this expansion was ensuring that user data remained completely isolated from the host environment. The solution relied on a specialized confidential computing technology that encrypts data during active processing. This configuration prevents the cloud provider from accessing server contents or monitoring computational workloads.
The technical implementation guarantees that all sensitive information stays within a verified secure boundary. Independent researchers can audit the infrastructure to confirm that no data persists after task completion. This verification process establishes a transparent framework for handling highly complex machine learning requests. For users concerned about data privacy, the architecture provides tangible assurances that personal information remains protected. The system also aligns with evolving regulatory requirements regarding cloud data storage. Apple Intelligence usage limits expand for iCloud+ subscribers in iOS 27 to accommodate these advanced computational demands.
The System Orchestrator and Data Routing Mechanism
Managing the flow of information across multiple models requires a sophisticated control layer. The system orchestrator functions as the central nervous system for all artificial intelligence operations. This software component evaluates each incoming request based on complexity, context requirements, and available resources. It determines whether a task should be processed locally or routed to a remote server. The orchestrator also integrates with several auxiliary systems to enhance response accuracy. These include a semantic search index, an application action library, and real-time screen context analysis.
For queries requiring current information, the system accesses a dedicated knowledge service built over several years. This routing architecture ensures that the most appropriate model handles each specific task. The seamless coordination between components creates a unified experience that masks the underlying complexity. Users interact with a single interface while the backend manages the technical distribution. The architecture also supports continuous optimization through machine learning feedback loops. Developers can monitor performance metrics to identify bottlenecks and improve response times. This systematic approach guarantees reliable functionality across diverse usage scenarios.
What are the practical implications for users and developers?
The architectural changes introduce several tangible benefits for everyday users and software creators. Device performance improves significantly because routine tasks no longer require network connectivity. Battery efficiency increases as processing loads are distributed more intelligently across available hardware. Developers gain access to a more predictable and secure environment for integrating artificial intelligence features. The strict privacy boundaries allow organizations to deploy advanced capabilities in regulated industries without violating data compliance requirements. The hybrid processing model also reduces infrastructure costs by minimizing unnecessary cloud requests.
This efficiency translates to faster feature rollouts and more responsive software updates. The independent verification framework provides additional assurance for enterprise customers who prioritize data sovereignty. The overall system design reflects a mature approach to scaling artificial intelligence responsibly. Future iterations will likely build upon this foundation as processing demands continue to grow. The industry will watch closely to see how these architectural decisions influence broader AI development strategies. Software creators will need to adapt their development workflows to accommodate the new routing architecture. The system orchestrator requires precise metadata tagging to function correctly. Developers must optimize their applications to communicate efficiently with the underlying models. This transition period will likely involve extensive testing and iterative refinement. The long-term benefits include more reliable feature performance and enhanced security protocols. Organizations that invest in these adjustments will gain a competitive advantage. The ecosystem will mature as more developers adopt the updated standards.
Conclusion
The technology landscape continues to evolve as manufacturers navigate the complexities of machine learning integration. Establishing clear boundaries between internal development and external partnerships remains essential for maintaining user trust. The new architecture demonstrates how hardware companies can achieve advanced computational performance without compromising established privacy principles. Regulatory frameworks continue to shape how artificial intelligence features are deployed globally. Apple's Siri AI EU Rollout Delayed Amid Regulatory Dispute illustrates how regional policies influence technical design choices. Future iterations will likely build upon this foundation as processing demands continue to grow. The industry will watch closely to see how these architectural decisions influence broader AI development strategies.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)