OpenAI Upgrades ChatGPT Memory Architecture for All Users
OpenAI is rolling out an enhanced memory architecture that improves context retention and preference tracking across all subscription tiers. By optimizing computational efficiency, the company now extends advanced background synthesis capabilities to free users for the first time, while Plus and Pro subscribers gain expanded capacity and greater visibility into how personal data shapes future responses.
OpenAI has quietly initiated a substantial overhaul of how ChatGPT retains and utilizes user information, marking a decisive pivot in conversational artificial intelligence. The company is deploying an updated memory architecture that fundamentally changes how the system synthesizes past interactions into actionable context. This update carries particular weight for users operating on complimentary subscription tiers, as efficiency gains finally allow advanced personalization features to reach a broader audience. The evolution from basic prompt-dependent storage to continuous background processing represents one of the most significant structural adjustments in the platform's history.
OpenAI is rolling out an enhanced memory architecture that improves context retention and preference tracking across all subscription tiers. By optimizing computational efficiency, the company now extends advanced background synthesis capabilities to free users for the first time, while Plus and Pro subscribers gain expanded capacity and greater visibility into how personal data shapes future responses.
What is the architectural shift behind OpenAI's latest update?
The foundation of modern conversational models has always relied on context windows, which determine how much information a system can actively process during a single interaction. Early implementations struggled to maintain continuity beyond immediate exchanges, forcing users to repeatedly restate preferences and background details. When OpenAI first introduced its memory capabilities in April 2024, the feature operated through a straightforward mechanism known as saved memories. Users had to provide explicit cues or direct prompts to trigger retention, creating a manual workflow that disrupted natural conversation flow. Many individuals noticed that stored information gradually lost relevance as time passed and new interactions accumulated.
The system lacked an internal mechanism to prioritize, filter, or update retained data without constant user intervention. To address these limitations, developers began experimenting with continuous background processing techniques. This experimental phase introduced a process called dreaming, which allowed the model to synthesize information across multiple separate conversations without requiring explicit instructions. The architecture operated silently behind the scenes, extracting patterns and preferences while maintaining computational stability. While this approach significantly improved personalization capabilities, engineers recognized that it could not function as a complete standalone solution.
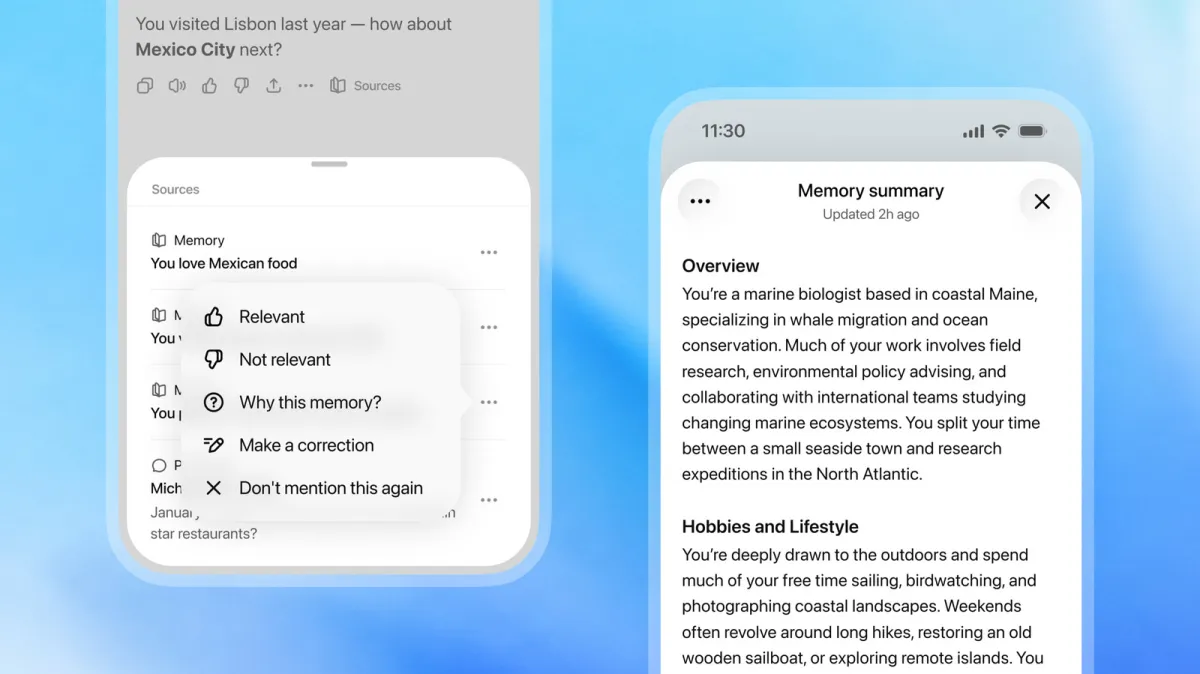
The current release addresses these architectural gaps by introducing a hybrid memory framework that combines background synthesis with structured user management tools. Instead of relying solely on implicit processing, the new system generates readable summaries that users can review, edit, or expand upon at any time. This dual-layer approach bridges the gap between automated data collection and human oversight, allowing individuals to maintain precise control over what information influences future responses. The architecture also integrates seamlessly with existing context visibility tools, creating a more transparent environment for managing personalized interactions.
How does the new memory system function for everyday users?
User interaction with the updated framework centers around transparency and direct management capabilities. Individuals can now access a dedicated summary that outlines what the system has recorded about their preferences, habits, and stated requirements. This document functions as an active interface rather than a static archive, allowing users to add new details, correct outdated information, or remove specific entries entirely. The design philosophy emphasizes user agency, ensuring that automated processing never operates without the possibility of manual verification or adjustment. People who prefer granular control can explicitly instruct the model when to reference stored data during active conversations.
For individuals interested in understanding how personalization occurs behind the scenes, the system provides direct access to source documentation. This feature reveals exactly which recorded information influenced a specific response, enabling users to trace how past interactions shape current outputs. The ability to edit or delete contextual references before they impact future answers creates a feedback loop that maintains accuracy over extended usage periods. Users can also initiate direct conversations with the model to explore stored data in greater depth, asking clarifying questions about why certain preferences were recorded or how specific details will be applied going forward.
Context retention has been substantially improved through careful algorithmic adjustments. The system now tracks ongoing projects and long-term interests more effectively, reducing the need for users to repeat background information during follow-up requests. Photography enthusiasts who previously had to restate their equipment specifications before each gear recommendation can now expect automatic compatibility checks based on recorded preferences. Travel planners benefit similarly, as the model cross-references past itinerary discussions with current destination queries to generate more relevant suggestions.
Context retention and preference tracking
Maintaining accurate contextual awareness requires sophisticated filtering mechanisms that distinguish between temporary conversational remarks and enduring preferences. The updated framework employs continuous evaluation processes to determine which data points warrant long-term storage. When users discuss specific equipment, travel destinations, or professional requirements across multiple sessions, the system identifies recurring themes and consolidates them into structured summaries. This consolidation prevents contextual fragmentation while ensuring that critical details remain accessible during future interactions.
The automatic revision process continuously monitors stored information for accuracy, flagging entries that may have become obsolete as user circumstances evolve. Preference tracking operates through pattern recognition rather than explicit categorization. The model analyzes linguistic cues and repeated requests to identify consistent priorities across different conversation topics. A user who consistently asks for vegetarian restaurant recommendations while planning trips will naturally trigger preference storage without requiring manual setup.
Why does compute efficiency matter for free-tier access?
Computational resource allocation has always dictated which features remain available across different subscription tiers. Advanced personalization capabilities typically require substantial processing power to maintain continuous background synthesis without degrading response times or system stability. Historically, this requirement meant that sophisticated memory architectures remained exclusive to paying subscribers who could justify the infrastructure costs through recurring revenue models. Free users experienced basic functionality while premium accounts received enhanced personalization and expanded storage capacity.
This tiered approach created a clear distinction between casual experimentation and professional usage environments. The current architectural overhaul directly addresses these resource constraints through algorithmic optimization. Engineers have redesigned background processing pipelines to reduce computational overhead while maintaining synthesis accuracy. These efficiency improvements allow the system to record memories through continuous dreaming processes for complimentary accounts without straining server infrastructure.
The technical achievement lies in balancing sophisticated data extraction with minimal resource consumption, enabling broader feature distribution across all user categories. This shift represents a strategic expansion of personalization capabilities rather than a simple feature downgrade for premium subscribers. Expanding advanced memory features to free users fundamentally changes how people interact with conversational models on a daily basis.
What are the broader implications for conversational AI development?
Individuals who previously relied on manual note-taking or external documentation can now leverage automated context retention during casual usage sessions. The democratization of these tools reduces the learning curve associated with prompt engineering and contextual management, allowing newcomers to experience personalized interactions without technical overhead. This expansion also encourages more consistent platform engagement, as users recognize that their historical conversations will actively improve future response quality rather than remaining isolated within individual sessions.
The evolution of memory architectures signals a fundamental shift in how artificial intelligence systems approach personalization and contextual continuity. Early models treated each interaction as an independent event, requiring users to reconstruct background information before every new request. Modern frameworks now recognize that sustained utility depends on maintaining accurate historical awareness while preventing data accumulation from degrading response quality.
This paradigm shift influences how developers design retrieval mechanisms, prioritize information relevance, and balance automation with user oversight. The industry is moving toward systems that adapt continuously rather than requiring manual configuration for personalized functionality. Privacy considerations remain central to this architectural evolution as personalization capabilities expand across subscription tiers. Users increasingly expect transparency regarding what data gets recorded, how long it remains active, and which responses it influences.
The introduction of readable summaries and direct source documentation addresses these expectations by providing clear visibility into automated processing workflows. This transparency builds trust while maintaining the utility that drives platform adoption. Developers must continue refining retrieval accuracy to ensure that stored information improves rather than complicates user experiences over extended usage periods. The strategic decision to extend advanced synthesis capabilities to complimentary accounts reflects broader industry trends toward accessible personalization.
As computational efficiency improves, features once reserved for premium environments naturally migrate toward universal availability. This progression encourages more sophisticated interaction patterns while reducing the friction associated with manual context management. Future iterations will likely focus on refining automatic revision processes and enhancing cross-session continuity without increasing infrastructure demands. The transition from explicit prompt-dependent storage to continuous background synthesis represents a mature step in conversational platform development.
OpenAI has demonstrated that computational optimization can successfully bridge the gap between advanced personalization and broad accessibility. Users now benefit from structured oversight tools, improved context retention, and automated preference tracking regardless of their subscription level. This architectural foundation supports more natural interactions while maintaining clear boundaries around data management and retrieval accuracy.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)