ChatGPT Memory Architecture Shift: Understanding Automated Context Synthesis
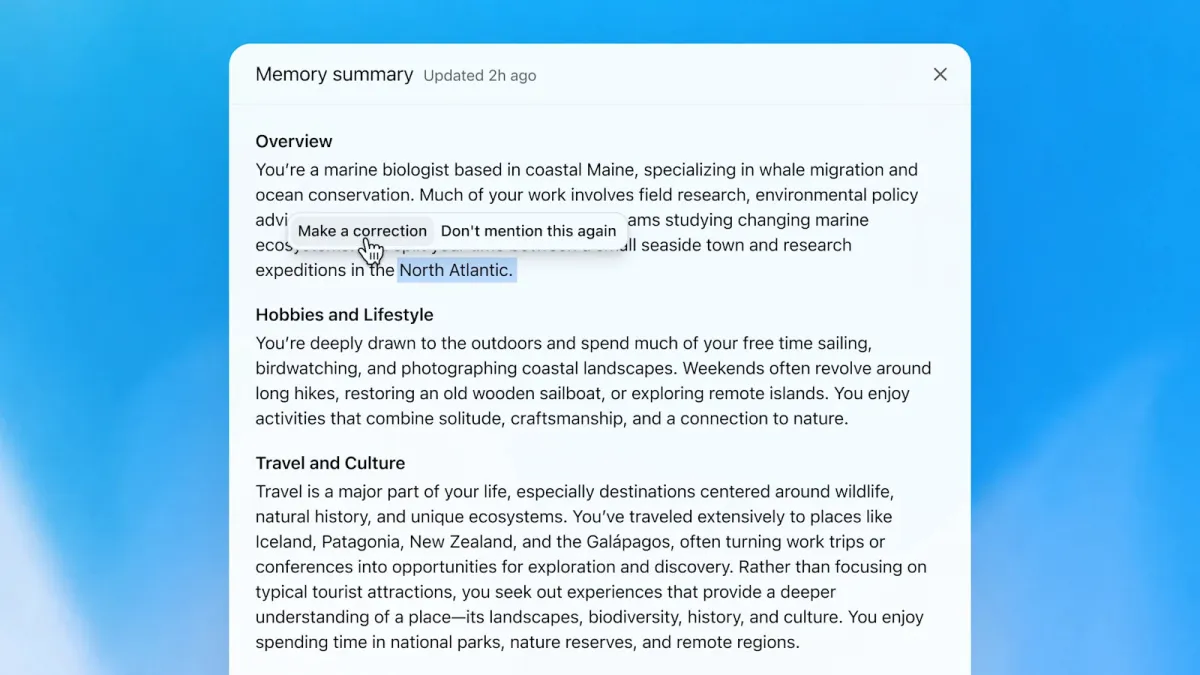
OpenAI has deployed a new dreaming capability within ChatGPT that automatically curates memories from previous conversations to enhance conversational relevance. Users can now generate, review, and edit comprehensive summaries of stored information, ensuring accuracy and control over their personalized data profiles. The feature currently supports paying subscribers in the United States before expanding globally to free and tiered accounts.
OpenAI has introduced a significant architectural shift in how its conversational model retains information across sessions. The newly deployed dreaming capability represents a move away from isolated interactions toward continuous contextual awareness. This development alters the fundamental relationship between users and artificial intelligence assistants by enabling automatic memory curation without manual prompts. The underlying system now processes past exchanges to build a dynamic profile that evolves with every dialogue. Understanding this transition requires examining both the technical mechanisms and the broader implications for digital personalization.
OpenAI has deployed a new dreaming capability within ChatGPT that automatically curates memories from previous conversations to enhance conversational relevance. Users can now generate, review, and edit comprehensive summaries of stored information, ensuring accuracy and control over their personalized data profiles. The feature currently supports paying subscribers in the United States before expanding globally to free and tiered accounts.
What is the new dreaming mechanism?
The term dreaming refers to a background processing routine that synthesizes chat history into structured memory states. Rather than relying on explicit user commands, the system continuously evaluates past interactions to identify recurring preferences, factual details, and contextual patterns. This automated curation allows the model to maintain a coherent narrative across multiple sessions without requiring manual input during active dialogues. The architecture functions by extracting relevant data points and organizing them into a retrievable format that updates dynamically as new conversations occur.
Traditional conversational models operated within strict session boundaries, treating each exchange as an independent event. When developers recognized the limitations of this isolated approach, they introduced explicit memory commands to allow users to store specific information manually. Subsequent iterations enabled automatic retrieval of context from previous dialogues, though the process remained largely reactive rather than proactive. The latest iteration shifts toward continuous background processing, where the system actively curates and refines stored information without direct user intervention during active sessions.
This architectural evolution addresses a fundamental challenge in artificial intelligence design: maintaining long-term contextual awareness while preserving computational efficiency. By synthesizing memory states in real time, the model can prioritize recent interactions alongside historical patterns to deliver more accurate responses. The system does not merely store raw conversation logs but actively filters and organizes data into structured profiles that enhance future dialogue quality. This approach reduces redundancy and allows for smoother conversational continuity across extended usage periods without overwhelming processing capacity.
The distinction between raw data logging and structured memory synthesis represents a critical advancement in system architecture. Early implementations simply archived conversation transcripts, forcing the model to scan extensive logs during subsequent sessions. This method proved computationally expensive and often resulted in irrelevant context retrieval. Modern synthesis techniques compress historical interactions into meaningful summaries that prioritize actionable information over verbatim records. The background routine continuously updates these compressed profiles, ensuring that only verified and relevant details influence future responses while maintaining efficient memory utilization across the platform.
How does automated memory curation function?
The underlying process relies on continuous analysis of chat history to identify meaningful patterns and recurring details. When users engage with the system, the background routine evaluates each exchange to determine which elements warrant long-term retention. Factual preferences, project specifics, and stylistic choices are extracted and compiled into a comprehensive summary that reflects the user's current profile. This automated synthesis ensures that relevant context remains accessible without requiring manual organization or explicit storage commands during active conversations.
Once the system generates a memory summary, users gain direct visibility into what information has been retained. The interface provides tools to review the compiled data and verify its accuracy against actual interactions. If discrepancies appear or preferences change, individuals can manually edit the summary to align it with their current needs. This transparency mechanism addresses common concerns regarding automated data collection by placing verification and correction capabilities directly in user hands rather than leaving memory management entirely to algorithmic processes.
The integration of manual editing alongside automatic curation creates a hybrid workflow that balances efficiency with precision. Users benefit from the system's ability to identify relevant information automatically while retaining full authority over what remains stored. This collaborative approach prevents unnecessary data accumulation and ensures that retained memories accurately reflect current priorities rather than outdated preferences. The design philosophy emphasizes user agency, allowing individuals to shape their personalized context profiles through both passive observation and active management strategies.
Verification workflows operate through a straightforward interface that presents compiled memories in an organized format. Users can navigate through categorized entries to confirm accuracy or flag outdated information for removal. The editing tools allow direct modification of stored details without requiring technical expertise or complex command structures. This accessibility ensures that individuals maintain complete oversight of their digital profiles while benefiting from automated background processing. The system treats user corrections as immediate updates, rapidly adjusting future context retrieval to reflect the newly verified information accurately.
Why does persistent context matter for conversational systems?
Maintaining continuity across multiple sessions fundamentally changes how artificial intelligence assists with complex tasks. When a system remembers previous discussions, it eliminates the need to repeatedly provide background information or restate project parameters. This continuity reduces cognitive load and accelerates workflow efficiency by allowing conversations to build upon established foundations rather than starting from scratch each time. Users experience fewer interruptions and more coherent dialogue progression when historical context remains actively accessible throughout extended usage periods.
The shift toward persistent memory also addresses the limitations of traditional short-term contextual windows. Earlier models could only retain information within a single session or required users to manually paste previous exchanges into new chats. By automating this process, developers have removed friction from long-term project management and ongoing research workflows. The system now functions as an extended cognitive partner that gradually accumulates relevant knowledge rather than treating each interaction as an isolated event requiring complete contextual reconstruction.
Persistent context also influences how personalized responses are generated over time. As the model synthesizes more interactions, it develops a clearer understanding of individual communication styles, preferred formats, and recurring topics. This accumulated awareness allows for more tailored suggestions and fewer generic responses during subsequent conversations. The system becomes increasingly aligned with user expectations without requiring explicit training or repeated instruction, creating a feedback loop that continuously refines response quality based on actual usage patterns rather than theoretical assumptions about user needs.
Productivity metrics in professional environments often depend heavily on how quickly teams can access historical project data. Persistent memory systems eliminate repetitive briefing cycles that previously consumed valuable working hours. Researchers and analysts benefit from continuous documentation of methodological choices, source preferences, and analytical frameworks without manual transcription efforts. This seamless continuity allows complex projects to advance at a consistent pace regardless of session boundaries or platform interruptions. The reduction in administrative overhead directly translates to increased focus on substantive work rather than contextual reconstruction.
What are the practical implications for everyday users?
The rollout of this capability follows a phased deployment strategy that initially targets paying subscribers in specific regions. Users with Plus and Pro accounts in the United States can currently access the automated memory curation features while observing how the system handles data synthesis and retention. This controlled release allows developers to monitor performance metrics, identify potential edge cases, and refine the background processing algorithms before expanding to broader audiences. The gradual approach ensures that infrastructure capacity remains stable during peak adoption periods.
Future expansion plans include extending access to free tier users and international markets across multiple geographic regions. This progression reflects a standard software development lifecycle where advanced features transition from premium exclusives to widely available tools as optimization improves. Free and Go subscribers will eventually gain access to the same memory management capabilities, though implementation timelines may vary based on regional infrastructure requirements and localized testing protocols. The expansion strategy prioritizes system stability over rapid global deployment.
Users should approach automated memory features with an understanding of how background data processing operates within modern digital assistants. While the system provides valuable continuity and personalization benefits, it also requires regular verification to ensure stored information remains accurate and relevant. Periodic review of memory summaries helps maintain alignment between actual preferences and algorithmically compiled profiles. This proactive management style ensures that automated curation enhances rather than complicates daily interactions with conversational artificial intelligence tools across various professional contexts.
Development teams monitor system performance closely during the initial deployment phase to identify optimization opportunities. Feedback from early adopters informs adjustments to background processing algorithms and memory synthesis thresholds. Future iterations will likely introduce more granular control options, allowing users to define specific retention parameters for different conversation categories. The gradual rollout ensures that infrastructure scaling keeps pace with increasing demand while maintaining reliable performance standards across all subscriber tiers. Continuous refinement will ultimately determine how effectively the feature integrates into broader digital assistant ecosystems worldwide.
Conclusion
The evolution from isolated sessions to continuous contextual awareness marks a significant milestone in conversational interface design. Automated memory synthesis reduces friction while increasing the utility of long-term project workflows and ongoing research initiatives. Users who engage regularly with these systems will experience fewer repetitive explanations and more coherent dialogue progression across extended usage periods. As the technology expands beyond initial subscriber tiers, broader audiences will encounter similar capabilities integrated into standard digital assistant ecosystems. The focus remains on balancing computational efficiency with user control to ensure that persistent context serves practical needs rather than creating unnecessary data complexity.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)