Google DiffusionGemma: Parallel Text Generation Explained
Google has introduced DiffusionGemma, an open-source experimental model that generates text in parallel blocks rather than sequentially. While it delivers substantial speed improvements on modern hardware, the approach sacrifices some output refinement, positioning it as a specialized tool for responsive workflows rather than a direct replacement for established language models.
The landscape of artificial intelligence is undergoing a fundamental shift in how machines process and generate language. Traditional large language models have long relied on a sequential approach, predicting each subsequent word based on previous inputs. A new experimental framework from Google challenges this established paradigm by treating text generation more like an image diffusion process. This departure from linear prediction introduces significant performance gains, though it demands a careful evaluation of its practical limitations.
Google has introduced DiffusionGemma, an open-source experimental model that generates text in parallel blocks rather than sequentially. While it delivers substantial speed improvements on modern hardware, the approach sacrifices some output refinement, positioning it as a specialized tool for responsive workflows rather than a direct replacement for established language models.
What is DiffusionGemma and how does it differ from traditional models?
Traditional large language models operate through an autoregressive mechanism. This means they construct responses token by token, where each new element depends entirely on the preceding sequence. The process is inherently linear, which creates a bottleneck for computational efficiency. Every prediction must wait for the previous one to complete before the next calculation can begin. This sequential dependency limits how quickly these systems can scale across different hardware configurations.
DiffusionGemma approaches text generation from a completely different angle. Instead of building a response incrementally, the model begins with a canvas of random, noisy tokens. It then applies multiple refinement passes to gradually structure this chaotic input into coherent language. Each iteration reduces the noise while increasing the logical consistency of the output. The system essentially drafts and edits simultaneously rather than writing linearly.
This architectural shift allows the model to process up to two hundred and fifty-six tokens in a single computational step. Every token within that block can attend to every other token, creating a global understanding of the generated content. The model does not wait for a linear sequence to finish before adjusting its direction. It can identify and correct internal contradictions within the same generation cycle, which fundamentally changes how machine-generated text is constructed.
The implications for software development and content creation are notable. Developers who rely on inline coding assistants or real-time writing tools will notice a distinct difference in responsiveness. The system prioritizes immediate structural feedback over perfect grammatical polish. This design choice aligns closely with modern interface paradigms that value instant iteration, much like the principles discussed in The Engineering Behind Intentional Mobile Input Design, where user feedback loops dictate system architecture.
Why does parallel text generation matter for hardware efficiency?
Computational efficiency remains a primary driver for artificial intelligence research. Traditional autoregressive models require massive parallel processing capabilities to achieve acceptable speeds, yet they still struggle with latency in low-concurrency scenarios. When a single user or process interacts with the system, the sequential nature of token prediction creates unavoidable delays. Parallel generation directly addresses this bottleneck by utilizing GPU architecture more effectively.
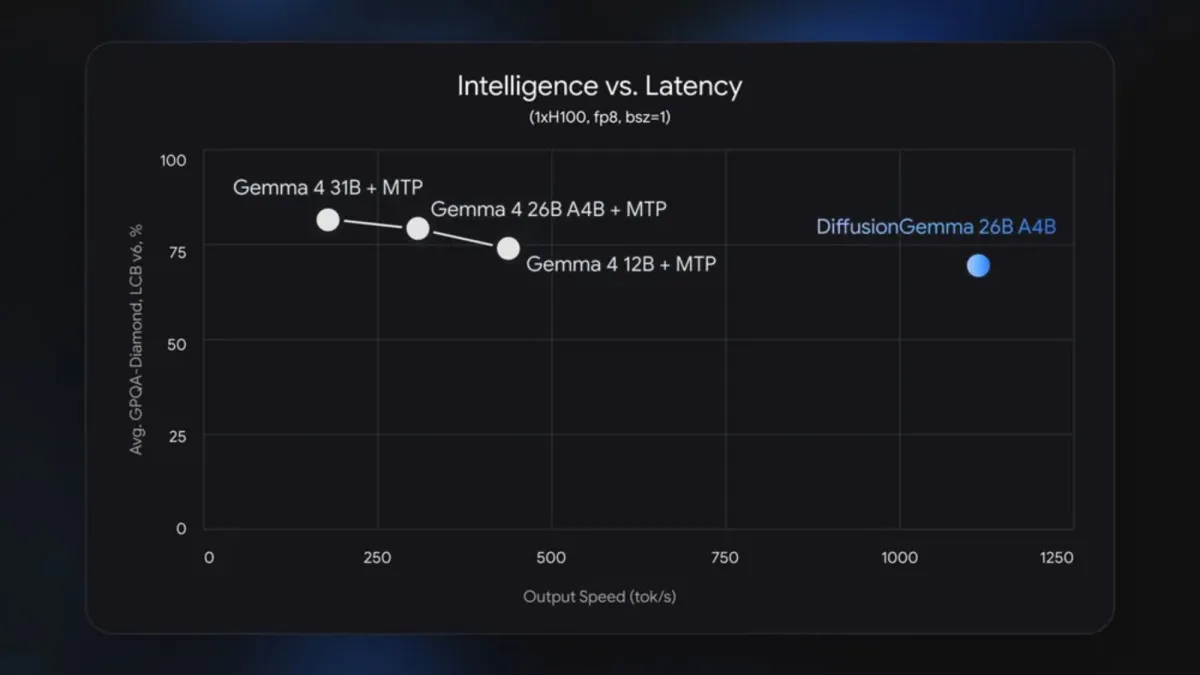
Google reports that DiffusionGemma can achieve speeds up to four times faster than standard autoregressive models in single-user environments. The performance metrics on high-end hardware are particularly striking. The company claims the model can exceed one thousand tokens per second on an NVIDIA H100 accelerator. It also demonstrates over seven hundred tokens per second on consumer-grade hardware like the RTX 5090 graphics card.
These numbers highlight a significant shift in how computational resources are allocated. Parallel processing allows multiple calculations to occur simultaneously, reducing the idle time that typically plagues sequential prediction engines. The model does not force the hardware to wait for a single chain of dependencies to resolve. Instead, it distributes the workload across available cores, maximizing throughput during the refinement phases.
Hardware manufacturers and cloud providers will likely take notice of these efficiency gains. Lower latency and higher throughput reduce operational costs for data centers running inference workloads. The ability to run complex models on consumer hardware also democratizes access to advanced artificial intelligence capabilities. Researchers and independent developers can experiment with sophisticated architectures without requiring enterprise-grade infrastructure.
How does the architecture balance speed with computational constraints?
Large language models typically require enormous computational power to function effectively. DiffusionGemma addresses this challenge through a Mixture-of-Experts architecture containing twenty-six billion parameters. However, the model does not activate every parameter during a single inference pass. It selectively engages only approximately three point eight billion parameters for each generation task. This dynamic routing mechanism significantly reduces the computational burden.
The selective activation strategy keeps memory requirements manageable for modern graphics cards. When the model is quantized, it operates with a virtual memory footprint of roughly eighteen gigabytes. This specification allows the system to run on high-end consumer hardware rather than exclusively relying on specialized data center accelerators. The reduced memory demand also means faster data transfer rates between the GPU and system memory.
Parameter efficiency is crucial for scaling artificial intelligence across diverse environments. By activating only the necessary components for a specific task, the model avoids wasting computational cycles on irrelevant pathways. This approach mirrors biological neural networks, which activate specific regions based on the nature of the input. The selective routing ensures that processing power is directed precisely where it is needed most.
The architectural design also influences how the model handles complex instructions. While the active parameter count is lower, the global attention mechanism compensates by maintaining context across the entire generated block. The model does not lose track of earlier tokens because it processes them simultaneously. This balance between parameter efficiency and contextual awareness defines the practical viability of the architecture.
What are the practical limitations and intended use cases?
Every architectural innovation introduces specific trade-offs, and DiffusionGemma is no exception. Google explicitly acknowledges that the model does not match the output quality of its standard Gemma four series. The text can appear less stable and less refined during the initial generation phases. The parallel processing approach prioritizes structural coherence over nuanced linguistic polish, which affects the final reading experience.
This quality trade-off determines the model's ideal deployment scenarios. It is not designed to replace established language models for creative writing or complex analytical tasks. Instead, it excels in environments where responsiveness outweighs perfection. Real-time applications, such as live coding assistants or dynamic content generation tools, benefit most from this speed-first philosophy. Users can iterate rapidly without waiting for lengthy processing delays.
Structured and rule-based tasks represent another strong use case for this architecture. The model performs exceptionally well when filling in missing code sections or completing rigid formats like JSON. It can navigate logic-heavy problems, such as mathematical patterns or puzzle-solving scenarios, where consistency across the entire output matters more than linear flow. The global view allows it to enforce rules uniformly across the generated block.
Researchers and developers will likely use this model as an experimental framework rather than a production-ready solution. The open-source Apache two point zero license encourages community exploration and modification. Teams can study the diffusion-based generation process to inform future model designs. The current version serves as a proof of concept for parallel text synthesis, demonstrating both its potential and its boundaries.
Where does this experimental approach fit in the broader AI landscape?
The artificial intelligence industry has spent years optimizing autoregressive models. These systems have proven highly effective for natural language understanding and generation. However, the linear nature of token prediction has always imposed a hard limit on speed. Parallel generation challenges this long-standing industry standard by borrowing concepts from computer vision and image synthesis. The cross-pollination of techniques between different AI subfields continues to drive innovation.
This shift reflects a broader trend toward specialized model architectures. Rather than forcing a single framework to handle every possible task, developers are creating tools optimized for specific workflows. DiffusionGemma targets responsiveness and hardware efficiency, leaving nuanced language generation to other models. This modular approach allows organizations to combine different systems for optimal results. Speed and accuracy can coexist when deployed correctly.
The research community will likely focus on improving the refinement process to close the quality gap. Future iterations may introduce better noise reduction techniques or more sophisticated attention mechanisms. The goal is to maintain the parallel processing advantages while restoring the linguistic polish that users expect. Incremental improvements in the generation passes could eventually make the model viable for mainstream applications.
Developers should monitor how this architecture influences the next generation of language models. The underlying principles of parallel token synthesis may become standard practice for high-throughput applications. Understanding these mechanisms helps engineers design more efficient software ecosystems. The experiment provides valuable data on how computational efficiency and language quality interact under different architectural constraints.
What does the future hold for parallel language models?
The introduction of DiffusionGemma marks a deliberate pivot toward speed and hardware optimization in artificial intelligence. By abandoning strict sequential prediction, Google has demonstrated that parallel text generation can deliver substantial performance gains. The model remains an experimental framework, deliberately trading some output refinement for rapid responsiveness. As researchers continue to refine the underlying mechanisms, this approach may eventually reshape how developers build real-time language applications.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.









Comments (0)