DeepSeek V3 to V3.2: Architecture and Technical Evolution
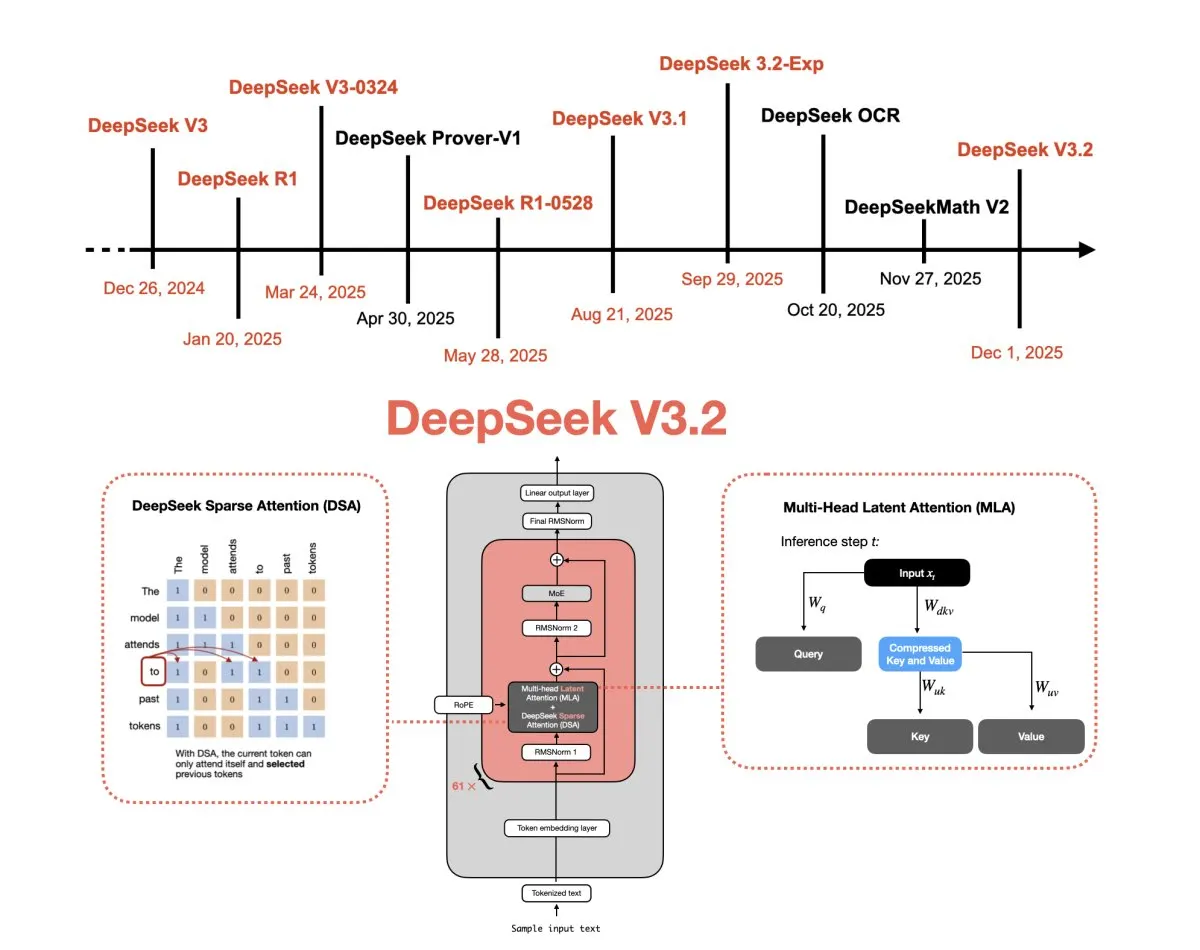
The transition from DeepSeek V3 to V3.2 represents a calculated refinement of mixture-of-experts architecture and tokenization strategies. This analysis examines how incremental adjustments in attention mechanisms and data curation reinforce model efficiency, positioning the series as pivotal benchmarks for open-weight large language model development.
The release of successive iterations in large language model development rarely follows a linear path of radical innovation. Instead, the most significant advances in artificial intelligence emerge through meticulous architectural refinement and systematic data optimization. Examining the progression from DeepSeek V3 to V3.2 reveals how incremental technical adjustments compound to create substantial performance gains. This analysis explores the underlying mechanisms, training methodologies, and structural decisions that define this evolutionary trajectory.
What is the architectural foundation of DeepSeek V3?
The foundational design of the initial flagship model relies heavily on a sparse mixture-of-experts configuration. This architecture partitions computational resources across numerous specialized routing pathways, allowing the system to activate only the most relevant subsets of parameters for any given input sequence. By decoupling capacity from active computation, the model maintains high throughput while scaling its effective parameter count.
The underlying transformer blocks utilize grouped-query attention mechanisms to reduce memory bandwidth requirements during inference. This structural choice balances context window expansion with hardware efficiency, ensuring that training runs remain feasible across distributed GPU clusters. The routing algorithms employed to distribute tokens across experts require careful calibration to prevent load imbalance and ensure stable convergence during the multi-stage training process.
Expert selection thresholds are dynamically adjusted throughout the training lifecycle to prevent routing collapse. When certain experts dominate the computation graph, the model struggles to learn diverse feature representations. Implementing auxiliary loss functions encourages a more uniform distribution of tokens across the available pathways. This technique stabilizes gradient flow and prevents early saturation, which is critical when training networks with billions of parameters.
How does the V3.2 iteration improve upon its predecessor?
The subsequent release introduces targeted modifications to the original architecture, focusing primarily on sequence handling and computational precision. Adjustments to the attention rollout procedures allow for more accurate probability distributions across longer contexts. These refinements reduce the accumulation of approximation errors that typically degrade performance in extended text generation tasks. Engineers also recalibrated the normalization layers to stabilize gradient propagation during the final training phases.
The update also incorporates enhanced numerical stability protocols within the expert routing layers. By tightening the thresholds for expert selection, the system minimizes redundant computations and improves token-level accuracy. These modifications demonstrate a shift toward optimizing inference efficiency without sacrificing the raw reasoning capabilities that established the original series as a prominent benchmark. The iterative updates highlight how mature model development prioritizes precision over sheer parameter scaling.
Data curation strategies underwent parallel optimization to complement the architectural adjustments. Filtering mechanisms were applied to remove low-quality textual sources and reduce noisy signal exposure during pretraining. High-quality mathematical and code corpora received weighted prioritization to strengthen logical reasoning pathways. This deliberate curation process ensures that the model allocates its computational budget toward high-signal patterns rather than statistical artifacts present in unfiltered web data.
Why does tokenization strategy matter in modern language models?
The efficacy of any large language model depends fundamentally on how it parses and represents raw text data. The transition between iterations reveals a deliberate evolution in byte-level pair encoding techniques and vocabulary expansion. By incorporating specialized subword algorithms, the system achieves higher compression ratios and reduces the total number of tokens required to represent complex technical documentation.
This efficiency directly impacts training duration and memory allocation during the pretraining phase. A well-calibrated tokenizer also mitigates out-of-vocabulary errors and improves cross-lingual alignment. When developers integrate these models into production environments, understanding token boundaries becomes critical for managing context windows and optimizing downstream processing pipelines. The relationship between tokenizer design and model performance remains a decisive factor in computational economics.
Vocabulary pruning and frequency-based filtering further refine the lexical representation space. Removing extremely rare character sequences prevents the model from overfitting to idiosyncratic formatting patterns found in specific datasets. Simultaneously, expanding the character-level subword inventory allows the network to handle specialized scientific terminology without fragmenting words into excessively long token chains. This balance maximizes both compression efficiency and semantic coherence during generation.
Vocabulary alignment across different software ecosystems remains a persistent engineering challenge. When models are exported to various deployment frameworks, token sequence boundaries can shift due to encoding discrepancies. Developers must implement strict version control for tokenizer binaries to ensure consistent inference behavior. These operational details often determine the reliability of production systems more than the underlying transformer weights themselves.
What are the broader implications for the open-weight AI landscape?
The continued publication of progressively refined models reshapes the competitive dynamics within the artificial intelligence research community. By maintaining an open-weight framework, developers provide academic institutions and independent engineers with transparent access to advanced architectures. This transparency accelerates benchmarking efforts and encourages independent verification of claimed capabilities. Organizations can now fine-tune these architectures for specialized domains without incurring the massive infrastructure costs associated with proprietary alternatives.
The availability of detailed technical documentation also facilitates more accurate comparisons across competing frameworks. As computational budgets tighten, the industry increasingly values models that deliver high performance through architectural elegance rather than brute-force scaling. This shift aligns closely with modern practices in software delivery, where teams focus on streamlining development workflows to maximize output. Understanding these patterns can inform broader product strategy discussions, much like the methodologies outlined in recent analyses of AI-powered product management.
Independent researchers gain the ability to audit routing mechanisms and attention distributions directly. This scrutiny forces developers to maintain rigorous standards for reproducibility and performance reporting. The resulting ecosystem fosters collaborative innovation rather than isolated experimentation. When multiple laboratories can examine the same architectural blueprints, collective progress accelerates through shared debugging strategies and optimized training schedules that benefit the entire research community.
Commercial entities face distinct challenges when deploying open-weight models at scale. They must balance customization requirements with the operational overhead of hosting massive parameter matrices. Providing dedicated inference infrastructure often requires significant capital investment in specialized accelerator arrays. Organizations that leverage cloud-based routing services can mitigate these costs while maintaining strict data privacy controls.
Regulatory frameworks are beginning to address the transparency requirements of open-weight distributions. Auditors demand clear documentation of training data provenance and safety filtering mechanisms. Compliance teams must verify that generated outputs align with jurisdictional content standards. This regulatory scrutiny pushes developers to implement more robust content governance protocols directly into the model architecture.
What role does multi-stage training play in model convergence?
The training pipeline for modern large language models typically unfolds across distinct developmental phases. Initial pretraining establishes broad linguistic patterns and factual correlations across massive corpora. Subsequent instruction tuning aligns the network with human preferences and task-specific formatting requirements. A final alignment phase refines safety boundaries and reduces hallucination rates in sensitive domains. Each stage requires specialized learning rate schedules and batch size adjustments to prevent catastrophic forgetting.
Gradient accumulation and mixed-precision arithmetic optimize memory usage during these extended optimization runs. Researchers monitor loss curves across validation subsets to detect overfitting before it impacts generalization. The transition between stages often involves freezing lower transformer layers while updating only the upper parameter blocks. This selective update strategy preserves foundational linguistic representations while adapting higher-level reasoning pathways to new objective functions.
Evaluation checkpoints are deployed at regular intervals to track performance across standardized benchmarks. Sudden spikes in validation loss often indicate learning rate mismatches or data contamination issues. Automated monitoring systems flag these anomalies to trigger curriculum adjustments or data filtering updates. This iterative feedback loop ensures that the model retains its core capabilities while gradually acquiring specialized competencies.
How do evaluation metrics guide architectural decisions?
Benchmark performance serves as the primary compass for architectural modifications during development. Researchers track accuracy, latency, and parameter efficiency across diverse task categories to identify structural weaknesses. Standardized coding and mathematical evaluations reveal whether routing mechanisms adequately handle logical reasoning tasks. Discrepancies between training loss and benchmark scores often indicate a need for improved data diversity or modified attention rollout procedures.
Human evaluation protocols complement automated scoring by assessing coherence, factual consistency, and instruction adherence. These qualitative assessments capture nuances that numerical metrics frequently miss. Teams aggregate feedback from specialized annotators to refine reward models used during alignment phases. The resulting feedback loops directly influence how subsequent architecture iterations prioritize reasoning depth over superficial pattern matching.
Cross-lingual benchmarking further exposes biases hidden within predominantly English-trained corpora. Performance drops in lower-resource languages highlight the necessity of balanced multilingual data collection. Developers adjust tokenizer expansions and expert routing weights to compensate for these disparities. Systematic benchmarking ensures that architectural improvements translate into tangible gains across the full spectrum of supported languages.
Conclusion
The progression from the initial flagship release to its refined successor illustrates a mature phase of artificial intelligence development. Rather than pursuing exponential parameter growth, the focus has shifted toward architectural precision, data curation, and computational efficiency. These incremental adjustments compound to produce models that operate more reliably within real-world constraints. The open-weight approach continues to lower barriers to entry while establishing rigorous standards for independent evaluation. As the field matures, technical transparency and systematic iteration will remain the primary drivers of meaningful advancement in large-scale language processing.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.







Comments (0)