Understanding Gemini's Privacy Tradeoffs and Chat Retention Policies
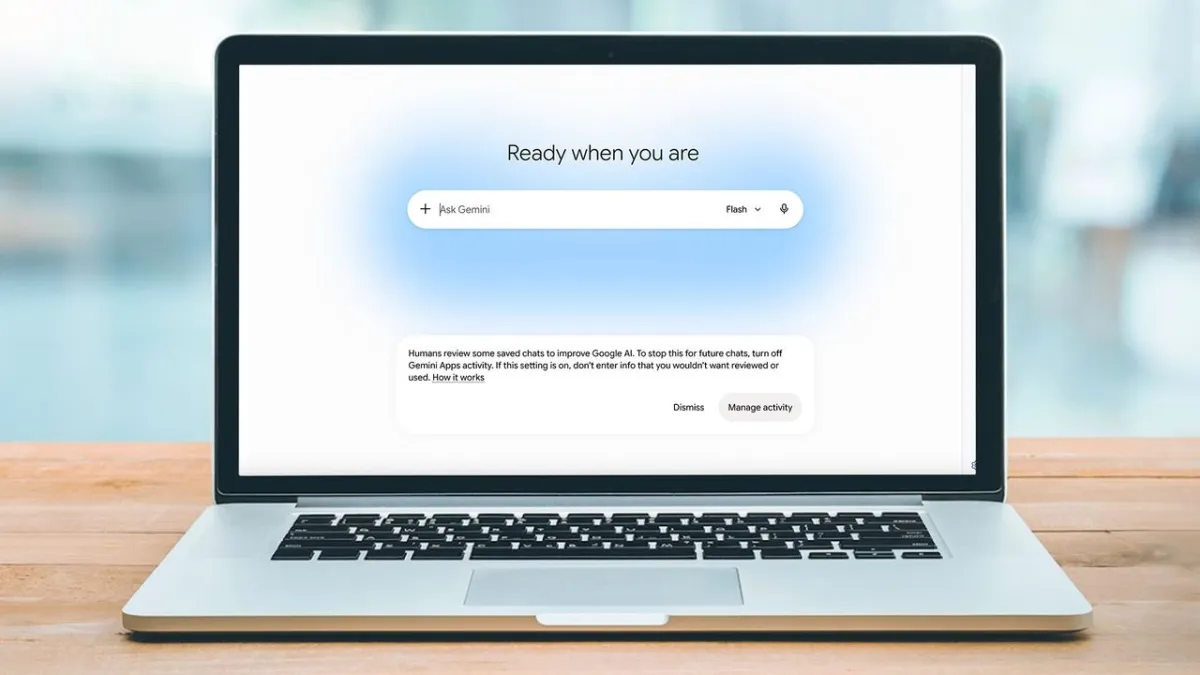
Google Gemini recently warned users that human reviewers examine saved conversations. Disabling this tracking triggers a strict seventy-two hour expiration for chat history. This architectural choice forces a direct tradeoff between long-term memory and complete privacy. The platform design contrasts sharply with competitors that separate training controls from retention. Understanding these mechanics is essential for managing digital privacy.
Modern artificial intelligence systems have rapidly evolved from simple command-line utilities into complex conversational interfaces. Users now rely upon these platforms for daily planning, creative work, and emotional support. This transformation has fundamentally altered how individuals interact with digital technology. The expectation of persistent memory and contextual continuity has become deeply ingrained in consumer behavior. As these platforms integrate deeper into personal workflows, the underlying mechanisms governing data retention have grown increasingly opaque. Users frequently encounter automated warnings regarding data processing, yet the practical consequences of adjusting these settings often remain unclear until after a decision is made.
What is the actual privacy tradeoff behind Gemini Apps Activity?
The notification directs users to disable a setting labeled Gemini Apps Activity to prevent future interactions from being reviewed. Understanding this specific configuration requires examining how Google organizes user data across its ecosystem. The terminology reflects a legacy naming convention that groups interactions with the language model alongside connected services such as email, calendar applications, and cloud storage platforms. Google treats these combined interactions as a unified activity stream rather than isolating them as simple chat logs. This architectural decision means that adjusting privacy controls affects how the system aggregates and processes information across multiple digital environments.
Users who disable this setting effectively sever the connection between their conversational data and the broader training pipeline. The system then operates in a strictly isolated mode where no external personnel examine the generated outputs or input prompts. This isolation fundamentally changes how the platform learns from user behavior and improves its response accuracy over time. Organizations that remove this feedback mechanism often experience a gradual decline in model accuracy over extended periods. The decision to isolate data requires careful consideration of long-term performance versus immediate privacy benefits.
How does the seventy-two hour window reshape user experience?
Disabling the activity tracking feature introduces a strict temporal limitation on conversation persistence. The platform enforces a seventy-two hour expiration policy for any active dialogue threads. Users who initiate a discussion must return to the interface within that specific timeframe to maintain continuity. If the individual does not interact with the chat during that window, the entire conversation disappears from the system. This mechanism operates independently of traditional cloud backup procedures or manual archive functions. The design prioritizes immediate data deletion over long-term storage, effectively preventing the accumulation of historical records.
Individuals who rely on artificial intelligence for extended planning sessions or iterative problem-solving will notice a significant disruption in their workflow. Complex projects that require referencing earlier prompts or maintaining contextual thread continuity become difficult to manage. The system forces users to either accept human review of their data or abandon persistent memory capabilities. This constraint transforms the assistant from a continuous knowledge partner into a strictly ephemeral tool. The psychological impact of this limitation extends beyond mere inconvenience, as it challenges the fundamental promise of AI as a reliable memory extension.
Why does the industry approach to human review matter?
Human-in-the-loop quality assurance remains a standard practice across the artificial intelligence sector. Companies employ trained reviewers to evaluate model outputs for accuracy, safety, and alignment with ethical guidelines. This manual oversight process helps identify hallucinations, reduce biased responses, and improve overall system reliability. The recent disclosure highlights how transparent these internal operations have become, moving away from vague terms of service toward explicit user notifications. When platforms openly acknowledge that personnel examine user data, it forces a necessary conversation about digital privacy expectations.
Users must recognize that free or subscription-based services often rely on this feedback loop to maintain competitive performance standards. The tradeoff involves exchanging personal conversational data for continuous improvement in response quality and contextual understanding. Organizations that remove this feedback mechanism often experience a gradual decline in model accuracy over extended periods. The industry faces a difficult balancing act between preserving user confidentiality and maintaining high-quality outputs. As regulatory frameworks evolve, companies must navigate complex compliance requirements while preserving the data pipelines necessary for model refinement.
What distinguishes Google's architecture from competing platforms?
The implementation of privacy controls varies significantly across different artificial intelligence providers. Competing services frequently separate model training preferences from conversation retention settings. Users on those platforms can disable data collection for training purposes while preserving their complete chat history without interruption. This architectural separation allows individuals to maintain long-term memory capabilities while opting out of human review processes. Google's current design ties these two functions together, creating a unified toggle that affects both privacy and persistence.
The decision to link activity tracking with conversation expiration reflects a specific engineering philosophy regarding data lifecycle management. By enforcing a strict deletion window, the system ensures that no residual data remains accessible after the specified period. This approach minimizes the risk of unauthorized data retention but simultaneously limits user convenience. Competing providers have chosen to decouple these functions, allowing users to exercise precise control over each aspect of their digital footprint. Recent hardware advancements, such as the Acer Predator Atlas 8, demonstrate how local processing capabilities can reduce reliance on cloud-based data collection. The divergence in design philosophy highlights ongoing debates about how best to balance privacy, performance, and usability in consumer-facing artificial intelligence tools.
How should users navigate long-term AI memory and privacy?
Individuals must carefully evaluate their personal requirements before adjusting privacy configurations. Those who prioritize absolute data confidentiality should disable activity tracking and accept the seventy-two hour limitation. Users who require persistent memory for complex projects should maintain the current settings and acknowledge the human review process. The decision ultimately depends on how heavily individuals rely on artificial intelligence for daily tasks. Some may choose to alternate between privacy-focused modes and memory-focused modes depending on the sensitivity of their current projects.
Regularly reviewing platform settings and understanding the technical implications of each toggle is essential for maintaining control over digital interactions. The broader technology sector continues to grapple with similar challenges as digital privacy campaigns and security incidents highlight the importance of data protection. Recent industry developments, such as the DriveSurge campaign compromising thousands of websites, demonstrate how vulnerable digital ecosystems remain when security measures are neglected. Users should approach AI privacy settings with the same diligence they apply to traditional cybersecurity practices. Understanding the technical architecture behind these tools empowers individuals to make informed decisions that align with their personal values and professional requirements.
The intersection of artificial intelligence and personal data management continues to evolve at a rapid pace. Platforms must balance the technical necessity of training data with the growing demand for user privacy and transparency. The recent changes to conversation retention policies illustrate how engineering decisions directly impact daily user experiences. Individuals who engage with these tools regularly should familiarize themselves with the underlying data handling mechanisms. Clear communication regarding privacy controls and their practical consequences will remain essential as the technology matures. The ongoing dialogue between developers and users will shape how future systems manage information, memory, and confidentiality.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)