Google Gemini 3.5 Flash Release and Inference Speed Improvements
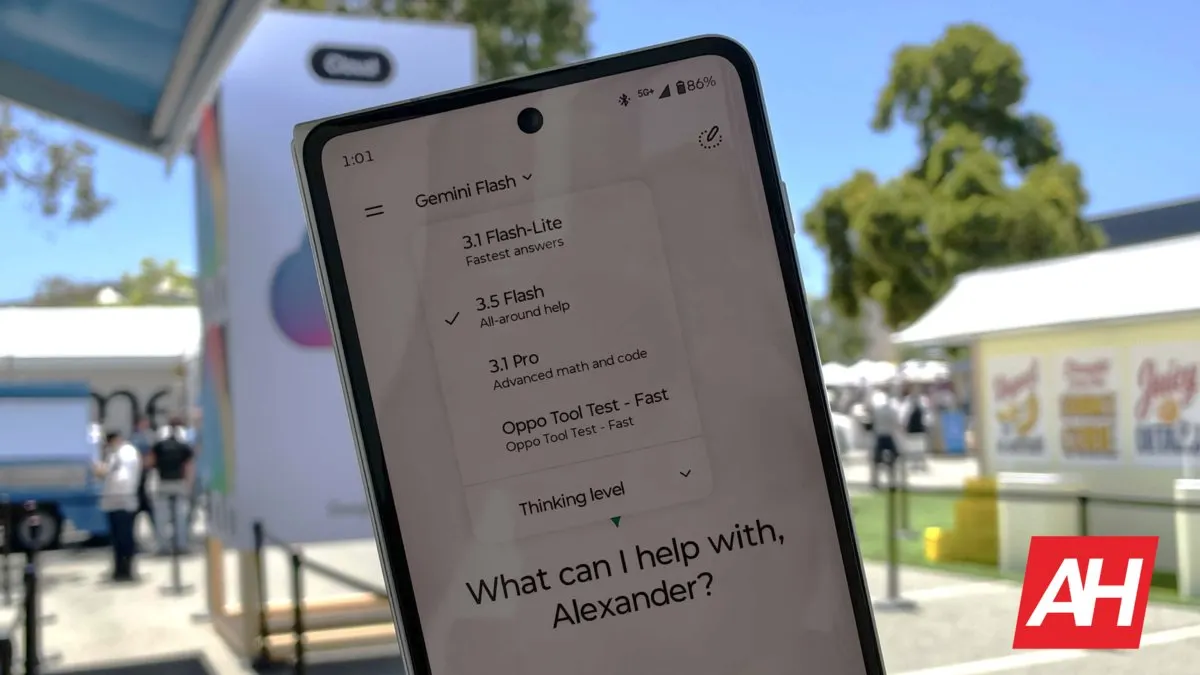
Google Gemini 3.5 Flash is now officially available within the web model selector interface, delivering substantial improvements to processing speed while introducing updated functional capabilities for developers and everyday users who require faster response times during complex computational tasks and routine data synthesis workflows across modern enterprise environments.
The rapid evolution of large language models continues to reshape how digital systems process information across global networks. Google has officially deployed Gemini 3.5 Flash through its web model selector, signaling a deliberate shift toward prioritizing inference velocity alongside contextual accuracy. This deployment marks another milestone in the ongoing refinement of accessible artificial intelligence infrastructure and modern computing workflows.
What is Gemini 3.5 Flash and Why Does Its Release Matter?
The introduction of Gemini 3.5 Flash represents a targeted optimization within Google's broader artificial intelligence ecosystem. Rather than focusing exclusively on expanding parameter counts or theoretical reasoning benchmarks, this iteration emphasizes operational efficiency during active inference cycles. Large language models traditionally balance depth against latency, but flash architectures deliberately compress processing pathways to reduce computational overhead. This release matters because it demonstrates how foundational AI providers can prioritize immediate utility without compromising structural integrity.
Organizations and individual users alike benefit from faster turnaround times when handling routine queries, document analysis, or rapid data synthesis tasks. The availability within the web model selector further underscores a strategic commitment to democratizing access to optimized inference engines. Developers can now route specific workloads toward velocity-focused architectures without requiring extensive infrastructure modifications. This approach aligns with broader industry trends that recognize computational efficiency as a critical component of sustainable AI deployment.
The underlying engineering philosophy behind flash models prioritizes streamlined token routing and optimized memory allocation during active generation phases. By minimizing idle cycles between requests, the system maintains consistent throughput even under heavy concurrent load conditions. Enterprises evaluating this update should consider how reduced latency impacts their existing software stacks and customer-facing applications. Faster response times directly correlate with improved user satisfaction metrics and more predictable resource utilization across distributed computing networks.
How Does the Speed Upgrade Translate to Real-World Performance?
Accelerated processing fundamentally alters how applications interact with generative systems. When latency decreases, developers can construct workflows that rely on continuous feedback loops rather than batched outputs. Users experience more fluid interactions during complex prompts, iterative debugging sessions, or real-time translation scenarios. The underlying architecture likely employs refined attention mechanisms to reduce redundant computational steps while preserving contextual fidelity across extended conversations.
This translates directly into higher throughput for concurrent users while maintaining consistent response quality. Systems that previously required careful throttling to manage server load can now operate with greater flexibility during peak usage periods. The practical impact extends beyond simple convenience, influencing how software engineers design responsive interfaces and how enterprises evaluate cost efficiency during high-demand operational windows. Reduced computational expenditure per request often emerges as a secondary benefit of optimized inference pathways.
Testing protocols must include comparative benchmarks against previous model iterations to verify actual throughput improvements under realistic load conditions. Teams should monitor response consistency across varying prompt lengths and complexity levels to ensure the speed upgrade does not introduce unexpected degradation in output accuracy. Establishing clear routing rules within the selector interface ensures that appropriate models handle specific task categories without unnecessary resource allocation or performance bottlenecks.
What Features Define the New Model Selector Integration?
Deploying a specialized inference model through an official selector interface requires careful architectural alignment. The web model selector acts as a centralized routing mechanism that directs incoming requests to the most appropriate processing engine based on workload characteristics. Gemini 3.5 Flash occupies a distinct tier within this hierarchy, optimized for rapid execution rather than exhaustive reasoning chains. This integration ensures that users can explicitly choose velocity-focused architectures when their tasks demand immediate results.
The selector also provides transparent version tracking and compatibility matrices, allowing developers to verify parameter support before implementation. Such transparency reduces trial-and-error cycles during system migration and helps teams maintain stable deployment pipelines across different operational environments. Engineers can configure fallback mechanisms that automatically route incompatible requests toward alternative models while preserving overall service continuity. This structured approach minimizes disruption during gradual adoption phases.
Documentation review remains essential, as updated parameter support or deprecated endpoints may require minor configuration adjustments during migration. Enterprises should also consider cost implications, since faster processing often correlates with lower computational expenditure per request while maintaining consistent output quality. Establishing clear routing rules within the selector interface ensures that appropriate models handle specific task categories without unnecessary resource allocation. Teams benefit from predictable performance metrics when scaling applications across multiple geographic regions.
Why Do Rapid Inference Cycles Shape Modern AI Architecture?
The industry has gradually shifted from pursuing maximum theoretical capability toward balancing performance with practical constraints. High latency remains a persistent bottleneck in distributed computing networks, particularly when handling concurrent requests across global data centers. Optimized flash models address this by streamlining attention mechanisms and reducing redundant computational steps during active generation phases. This architectural approach aligns with broader trends in edge computing and serverless deployment strategies where resource allocation must remain highly dynamic.
Providers that successfully compress processing time while preserving contextual fidelity gain a competitive advantage in both consumer applications and enterprise software stacks. The ongoing refinement of these systems reflects a mature understanding that speed is not merely a convenience metric but a foundational requirement for scalable artificial intelligence infrastructure. Engineering teams now prioritize modular design patterns that allow rapid model swapping without requiring complete system rewrites or extensive testing cycles. This architectural flexibility reduces deployment friction when adapting to evolving computational demands across diverse operational environments.
As computational demands continue to grow, balancing inference velocity with contextual accuracy will remain a central engineering challenge. Organizations that adopt optimized routing strategies and monitor performance metrics closely will likely realize measurable improvements in system responsiveness and resource utilization. The deployment of Gemini 3.5 Flash illustrates how foundational providers can deliver tangible operational benefits through targeted architectural refinements rather than purely theoretical expansion. Engineering teams must also consider long-term maintenance requirements when integrating velocity-focused models into existing production environments.
How Should Developers and Enterprises Approach This Update?
Integrating optimized inference models requires careful evaluation of workload characteristics and existing deployment pipelines. Teams should first audit their current request patterns to identify tasks that benefit most from reduced latency rather than extended reasoning chains. Testing protocols must include comparative benchmarks against previous model iterations to verify actual throughput improvements under realistic load conditions. Documentation review remains essential, as updated parameter support or deprecated endpoints may require minor configuration adjustments during migration.
Enterprises should also consider cost implications, since faster processing often correlates with lower computational expenditure per request while maintaining consistent output quality. Establishing clear routing rules within the selector interface ensures that appropriate models handle specific task categories without unnecessary resource allocation. Teams benefit from predictable performance metrics when scaling applications across multiple geographic regions. Monitoring response consistency across varying prompt lengths helps identify potential degradation in output accuracy during high-demand operational windows.
The deployment of Gemini 3.5 Flash illustrates a deliberate industry pivot toward operational efficiency rather than purely theoretical expansion. As artificial intelligence systems continue to scale, balancing inference velocity with contextual accuracy will remain a central engineering challenge. Organizations that adopt optimized routing strategies and monitor performance metrics closely will likely realize measurable improvements in system responsiveness and resource utilization. The ongoing refinement of accessible model selectors further simplifies the transition toward more dynamic computing environments where speed and reliability operate as complementary priorities rather than competing constraints. Administrators should establish clear governance policies to ensure consistent model usage across all development teams.
Conclusion
The strategic focus on inference velocity demonstrates how modern artificial intelligence development has matured beyond simple parameter scaling. Engineers and administrators must now evaluate computational efficiency alongside contextual accuracy when designing future software architectures. Continued monitoring of routing behaviors and performance metrics will determine how effectively organizations leverage these optimized models during peak operational periods. The industry trajectory points toward increasingly dynamic infrastructure where rapid execution and structural stability function as interdependent requirements rather than isolated objectives. Future updates will likely emphasize seamless interoperability between specialized inference engines and legacy application frameworks.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)