Google Search Deploys Persistent Information Agents
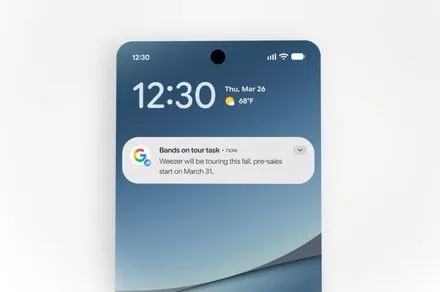
Google has begun deploying information agents within its AI Mode interface, allowing subscribers to track evolving topics and prices across the web. The system processes natural language requests to deliver continuous updates directly to mobile devices, marking a significant shift from static search toward persistent monitoring. Early availability is restricted to premium subscribers.
Search engines have traditionally operated as static retrieval tools, delivering immediate answers to discrete queries before fading into the background. That fundamental interaction model is undergoing a structural shift as technology providers begin integrating persistent monitoring capabilities directly into their core interfaces. The latest development introduces a system designed to track evolving topics across the open web, delivering curated notifications when relevant data changes. Digital ecosystems continue to evolve as technology providers prioritize automated workflows over manual data collection. This represents a deliberate move away from reactive search toward proactive information management, fundamentally altering how users interact with digital knowledge networks.
Google has begun deploying information agents within its AI Mode interface, allowing subscribers to track evolving topics and prices across the web. The system processes natural language requests to deliver continuous updates directly to mobile devices, marking a significant shift from static search toward persistent monitoring. Early availability is restricted to premium subscribers.
What are information agents and how do they function?
Information agents operate as persistent background processes embedded within the AI Mode environment of Google Search. Rather than executing a single lookup and terminating, these agents maintain active surveillance over designated subjects. Users initiate tracking by submitting natural language prompts that specify the desired parameters, such as product launches, financial indicators, sports outcomes, or housing market shifts. The underlying architecture continuously scans diverse data streams, including public web pages, financial databases, athletic scoreboards, and social media feeds. When the system detects meaningful alterations aligned with the original request, it compiles a concise summary and transmits it through the native mobile application. This mechanism eliminates the need for manual repetition, transforming intermittent research into a continuous, automated workflow.
The operational design prioritizes flexibility over rigid keyword matching. Traditional alert systems typically require exact phrasing or highly specific configuration parameters, which often limits their utility for complex or evolving subjects. Information agents bypass this constraint by interpreting conversational intent. A user can describe a scenario in plain language, and the system will parse the semantic meaning to establish tracking parameters. This approach reduces friction for individuals who lack technical expertise in setting up automated notifications. The agents also maintain contextual awareness, allowing them to filter noise and focus exclusively on developments that genuinely impact the tracked subject.
Why does continuous monitoring matter for modern search?
The transition from static queries to dynamic monitoring addresses a fundamental limitation in traditional information retrieval. Most online searches revolve around subjects that do not yield a single definitive answer. Market prices fluctuate, news stories develop incrementally, and employment opportunities appear and disappear rapidly. When users attempt to track these moving targets through conventional search, they must repeatedly execute identical queries, manually review results, and cross-reference timestamps. This repetitive cycle consumes significant time and often leads to information fatigue. Continuous monitoring resolves this inefficiency by delegating the surveillance task to an automated system that operates without human intervention.
This shift aligns with broader industry trends toward agentic computing, where software systems assume responsibility for ongoing tasks rather than isolated requests. The underlying philosophy recognizes that modern users require persistent awareness rather than momentary snapshots. By maintaining a continuous connection to relevant data sources, the system can detect subtle shifts that might otherwise go unnoticed. This capability proves particularly valuable for time-sensitive decisions, such as securing discounted travel arrangements, monitoring breaking developments in financial markets, or tracking policy changes that affect specific industries. The architectural move reflects a recognition that information value often increases over time rather than diminishing after initial retrieval.
How does the rollout differentiate between subscription tiers?
The deployment strategy for this capability follows a structured tiered approach, beginning with premium subscribers before expanding to broader audiences. Initial testing and early access were reserved for Google AI Pro and AI Ultra subscribers, reflecting the computational overhead required to maintain persistent monitoring across multiple concurrent requests. The current phase of deployment prioritizes AI Ultra subscribers, who access the platform through a monthly subscription model priced at approximately ninety-nine dollars. This pricing structure accounts for the substantial infrastructure demands of continuous web scanning, natural language processing, and real-time notification delivery. Premium subscribers gain immediate access to the feature across all supported languages and regional markets, ensuring consistent functionality regardless of geographic location.
The tiered rollout serves multiple strategic purposes. It allows the technology provider to monitor system stability under real-world load conditions while gathering performance metrics from engaged users. It also establishes a clear value proposition for higher subscription tiers, demonstrating tangible benefits that justify the monthly investment. As the system matures and computational efficiency improves, the barrier to entry may gradually decrease. The current restriction to premium subscribers ensures that the underlying infrastructure remains stable during the early deployment phase. Users on lower tiers or free accounts will likely experience phased access as the technology scales and operational costs stabilize across the broader user base.
What are the practical implications for everyday users?
The introduction of persistent monitoring capabilities introduces several practical considerations for individuals who rely on digital search tools. The most immediate benefit involves time savings and reduced cognitive load. Users no longer need to maintain mental checklists of topics requiring periodic review or manually execute repetitive searches. The automated system handles surveillance, filtering, and delivery, allowing individuals to focus on decision-making rather than information gathering. This efficiency gain proves especially valuable for professionals managing multiple concurrent projects, investors tracking market indicators, or consumers navigating complex purchasing decisions.
Management of active tracking requests occurs through the AI Mode history interface, where users can modify parameters, pause surveillance, or terminate monitoring entirely. This control mechanism ensures that users maintain full authority over their data collection activities. The system also provides contextual summaries alongside source links, enabling users to verify information independently before acting on notifications. This transparency helps maintain trust in the automated delivery process. The feature also supports natural language adjustments, allowing users to refine tracking parameters without navigating complex configuration menus. This design choice lowers the technical barrier to entry while maintaining robust functionality for advanced users.
How will performance and reliability be evaluated over time?
The long-term success of persistent monitoring capabilities depends heavily on system accuracy, latency, and resource management. Early deployment phases will inevitably expose limitations in natural language parsing, source prioritization, and notification frequency control. Users will likely encounter scenarios where the system misinterprets tracking parameters, delivers redundant updates, or fails to capture highly specialized developments. These edge cases provide valuable feedback for algorithmic refinement and infrastructure optimization. The technology provider must balance comprehensiveness with precision, ensuring that notifications remain relevant rather than overwhelming users with excessive data.
Evaluation metrics will likely focus on user retention, notification engagement rates, and system stability under concurrent load. The ability to maintain accurate tracking across diverse data types, from financial markets to social media feeds, requires sophisticated filtering mechanisms and continuous model updates. Performance validation will also examine computational efficiency, as persistent monitoring demands significant processing power and network bandwidth. The technology provider must optimize resource allocation to prevent service degradation during peak usage periods. Long-term viability will depend on achieving a sustainable balance between feature richness, system reliability, and operational costs.
Conclusion
The evolution of search interfaces continues to reflect broader shifts in how individuals interact with digital information ecosystems. Persistent monitoring capabilities represent a logical progression from reactive query execution to proactive information management. By delegating surveillance tasks to automated systems, users can maintain awareness of evolving subjects without sacrificing time or cognitive resources. The current deployment phase establishes a foundation for future enhancements, with performance validation and infrastructure scaling determining the trajectory of subsequent updates. As these systems mature, they will likely reshape expectations around digital information retrieval, establishing new standards for responsiveness, accuracy, and user control. The technology provider must navigate computational constraints, privacy considerations, and user experience optimization to ensure sustainable adoption across diverse audiences.
Looking ahead, the technology will likely expand to support more specialized data sources and advanced filtering options. Users can expect improved natural language parsing, reduced latency in notification delivery, and greater customization over alert frequency. The ongoing refinement of these capabilities will determine whether persistent monitoring becomes a standard feature across all subscription tiers or remains a premium differentiator. The industry will closely watch how these systems evolve to balance automation with user autonomy.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)