Incident Postmortem Tools for Small Managed Service Providers
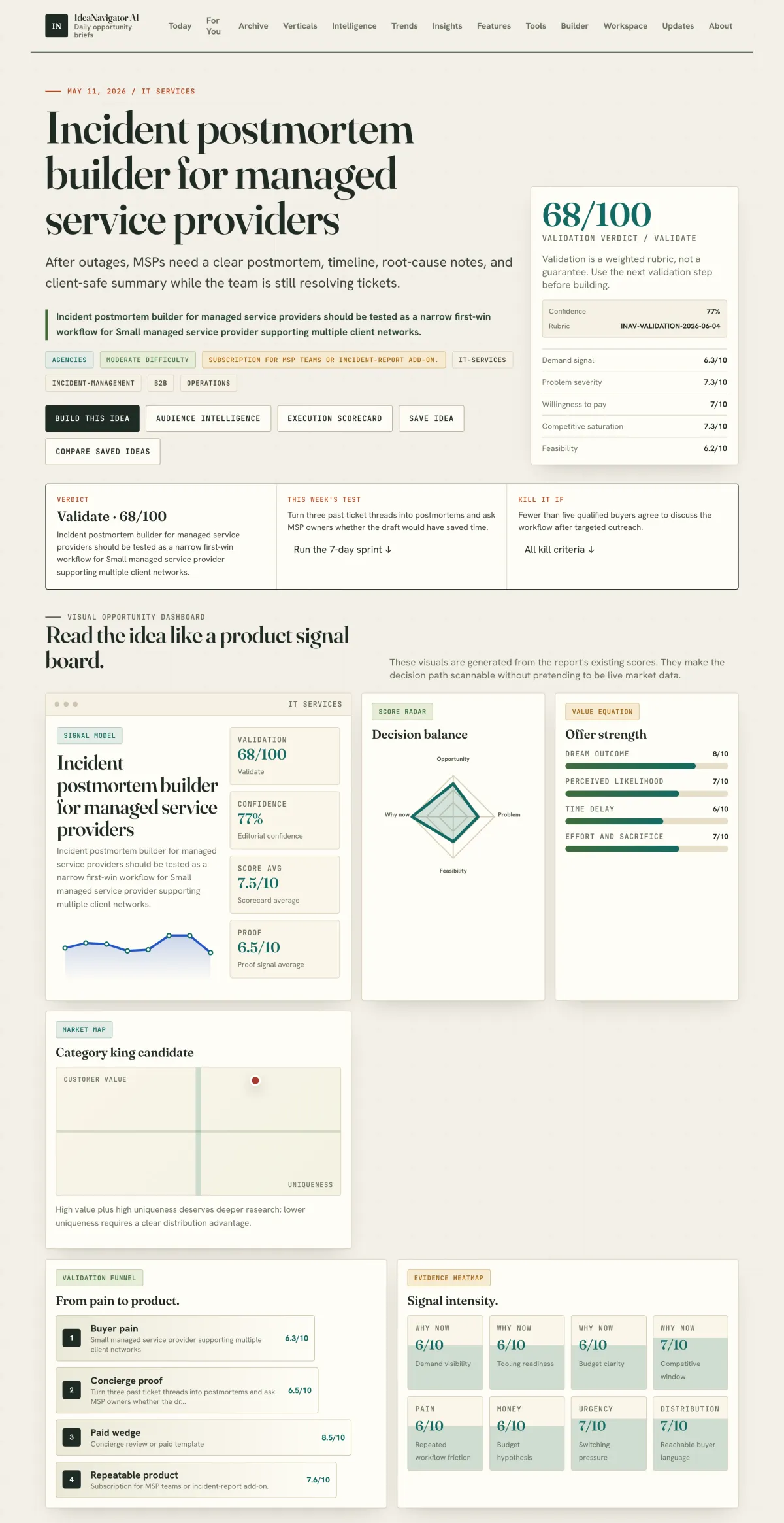
A new incident postmortem builder is being tested to help small managed service providers streamline post-incident communication and documentation workflows. This tool reduces administrative overhead while capturing critical lessons systematically. Standardizing outage analysis improves team coordination and accelerates future response times.
The modern technology landscape demands rapid resolution when systems fail, yet the aftermath of an outage often reveals deeper organizational vulnerabilities. Managed service providers operate under constant pressure to maintain uptime while managing complex client infrastructures. When disruptions occur, the immediate focus naturally shifts to restoring functionality and minimizing downtime. However, the true value of an incident lies not in the swift recovery alone, but in the systematic analysis that follows. Documenting the sequence of events, identifying root causes, and establishing preventive measures require dedicated tools and disciplined processes. Small service providers frequently lack the resources to build these frameworks from scratch, making standardized documentation solutions increasingly valuable for maintaining operational excellence.
A new incident postmortem builder is being tested to help small managed service providers streamline post-incident communication and documentation workflows. This tool reduces administrative overhead while capturing critical lessons systematically. Standardizing outage analysis improves team coordination and accelerates future response times.
Why does standardized incident documentation matter for technology service providers?
Incident management has evolved from a reactive technical exercise into a structured discipline that directly impacts client trust and operational continuity. When a service disruption occurs, multiple teams often collaborate under high stress to restore normal operations. Without a consistent framework for recording what happened, the knowledge gained during the crisis dissipates quickly. Standardized documentation ensures that every detail, from initial alert triggers to resolution steps, is captured accurately. This creates a reliable knowledge base that can be referenced during future emergencies. Service providers who prioritize thorough documentation reduce the likelihood of repeating past mistakes. They also demonstrate professionalism to clients by showing a commitment to continuous improvement.
The administrative burden of manual reporting often falls on technical staff who should be focusing on system stability. Streamlining this process allows engineers to maintain their focus on core technical responsibilities while ensuring compliance with internal quality standards. Teams that adopt structured reporting methods consistently experience fewer communication gaps during high-pressure situations. Clear documentation protocols eliminate ambiguity regarding roles and responsibilities during active crises. This clarity prevents duplicated efforts and ensures that critical information reaches decision-makers without delay. Organizations that invest in reliable documentation infrastructure ultimately save significant time and resources. The long-term benefits of systematic record-keeping far outweigh the initial implementation costs.
Regulatory requirements and industry best practices increasingly demand transparent incident reporting across all technology sectors. Providers must demonstrate that they have thoroughly investigated service failures before returning to normal operations. Standardized templates ensure that every required component is addressed consistently across all reported events. This uniformity simplifies audit processes and facilitates easier comparison of incident severity over time. Management teams gain actionable insights when data is collected through a unified system. The ability to track trends and measure improvement metrics becomes straightforward when documentation follows a predictable structure. Consistent reporting practices also support smoother transitions during staff changes and knowledge handoffs.
How do small managed service providers typically handle post-incident analysis?
Small technology firms frequently rely on informal communication channels to manage outage reporting. Engineers might document findings in scattered email threads, shared spreadsheets, or personal notes. This fragmented approach creates significant challenges when trying to reconstruct the timeline of a complex failure. Critical details can be lost when team members move to different projects or leave the organization. Manual compilation of incident reports also consumes valuable time that could be allocated to proactive system maintenance. Many small providers recognize the need for better processes but struggle to implement them due to limited budgets and staffing constraints.
The absence of a unified platform often results in inconsistent reporting quality across different teams. Some organizations attempt to adapt generic templates designed for large enterprises, but these often prove too rigid for smaller operational models. Finding a balance between thorough documentation and practical usability remains a persistent challenge. Providers must navigate the tension between comprehensive data collection and the need for rapid system recovery. Overly complex forms can discourage engineers from completing reports promptly. Conversely, overly simplistic templates may miss crucial technical details needed for meaningful analysis. The industry continues to explore lightweight solutions that fit the specific workflows of smaller service organizations without requiring extensive training or complex configuration.
Cultural factors also play a significant role in how post-incident work is approached within smaller teams. Engineers may view documentation as an administrative burden rather than a valuable professional development tool. Leadership must actively promote a blameless culture that encourages open sharing of technical findings. When staff members feel safe discussing failures without fear of punitive consequences, documentation quality improves dramatically. Transparent reporting fosters collective learning and strengthens team cohesion during difficult periods. Organizations that prioritize psychological safety alongside technical rigor consistently outperform competitors in service reliability metrics. Building this cultural foundation requires consistent leadership support and clear communication of organizational values.
What features define an effective postmortem builder for service providers?
An effective documentation tool must align closely with the daily realities of technical support teams. The interface should guide users through a logical sequence of questions without overwhelming them with unnecessary fields. Key components typically include sections for timeline reconstruction, impact assessment, root cause identification, and action item assignment. Automated data collection capabilities can pull relevant system logs and monitoring metrics directly into the report, reducing manual entry errors. Collaboration features allow multiple team members to contribute simultaneously while maintaining version control. The tool should also support template customization so providers can adapt reporting structures to different types of incidents.
Integration with existing ticketing systems ensures that postmortems remain connected to the broader service management workflow. When documentation lives within the same ecosystem as incident tracking, teams avoid context switching and data silos. This connectivity enables automatic population of baseline information such as affected services, customer impact levels, and initial response times. Providers benefit from a single source of truth that eliminates redundant data entry and minimizes transcription mistakes. Security considerations are paramount when handling sensitive client infrastructure details. Providers require granular access controls that protect confidential information while enabling necessary team visibility.
The ultimate goal is to transform incident documentation from a compliance chore into a strategic asset that drives operational maturity. Tools that emphasize usability and automation reduce friction in the reporting process and encourage consistent adoption. Regular review cycles allow management to identify systemic issues and allocate resources where they are needed most. Action items generated during postmortems can be automatically converted into follow-up tasks for engineering and operations teams. This seamless transition from analysis to implementation ensures that lessons learned translate into tangible improvements. Organizations that master this workflow continuously elevate their service delivery standards and strengthen client confidence.
How does streamlined post-incident reporting improve long-term service quality?
Systematic analysis of service disruptions creates a feedback loop that continuously strengthens technical operations. When providers consistently document failures and track the implementation of corrective measures, they build a comprehensive history of system vulnerabilities. This historical data enables teams to identify recurring patterns before they escalate into major outages. Management gains visibility into resource allocation needs and training requirements based on actual incident data rather than assumptions. Client relationships benefit from transparent communication about service reliability and the steps taken to prevent future disruptions. The ability to demonstrate a structured approach to problem resolution often becomes a competitive advantage when acquiring new business.
Teams experience reduced stress during emergencies when they know that documentation will be handled efficiently. This psychological safety allows engineers to focus entirely on technical resolution rather than administrative tracking. Over time, the cumulative effect of disciplined post-incident analysis transforms reactive troubleshooting into proactive infrastructure management. Historical reports serve as training materials for new hires and reference guides for experienced staff. They provide concrete examples of how similar challenges were successfully navigated in the past. This institutional knowledge prevents valuable expertise from leaving the organization when personnel changes occur. Consistent documentation practices ensure that operational wisdom remains accessible to everyone who needs it.
Continuous improvement methodologies rely heavily on accurate data collection and structured reflection periods. Providers that embrace systematic post-incident workflows position themselves for sustainable growth and stronger client partnerships. The development of specialized tools designed specifically for smaller organizations addresses a critical gap in the current market landscape. As service delivery becomes increasingly complex, the ability to capture and apply lessons from every disruption will separate industry leaders from the rest. Organizations that invest in systematic post-incident workflows today will build more resilient foundations for tomorrow. The focus must remain on practical usability, consistent data collection, and continuous process refinement.
What challenges remain in adopting standardized incident documentation tools?
Despite the clear benefits, several obstacles can hinder the successful implementation of postmortem builders within service organizations. Resistance to change often stems from engineers who prefer maintaining their existing informal workflows. Training requirements can consume valuable time that smaller teams cannot easily spare during busy periods. Integration with legacy systems may prove technically difficult or financially prohibitive for budget-conscious providers. Data migration from previous documentation methods requires careful planning to avoid losing historical context. Organizations must weigh these implementation hurdles against the long-term operational advantages of standardized reporting.
Measuring the return on investment for documentation tools can be challenging without clear baseline metrics. Providers need to establish performance indicators that track improvements in incident resolution times and recurrence rates. Leadership support is essential to ensure that documentation practices are consistently enforced across all departments. Without executive backing, technical teams may revert to familiar but inefficient methods when under pressure. Change management strategies should emphasize the practical benefits of streamlined reporting rather than focusing solely on compliance requirements. Demonstrating quick wins through pilot programs can help build momentum and secure broader organizational adoption.
The technology landscape continues to evolve rapidly, requiring documentation tools to adapt to new service architectures and deployment models. Cloud-native environments, automated scaling, and distributed systems introduce unique challenges for traditional incident tracking methods. Providers must select solutions that offer flexibility to accommodate changing technical requirements without constant reconfiguration. Vendor support and regular feature updates play a crucial role in maintaining long-term tool viability. Organizations should prioritize platforms that demonstrate a clear commitment to addressing the specific needs of managed service providers. Continuous evaluation of tool performance ensures that documentation practices remain aligned with operational goals.
Conclusion
The evolution of incident management reflects a broader shift toward operational maturity in the technology services sector. Providers that embrace structured documentation practices position themselves for sustainable growth and stronger client partnerships. The development of specialized tools designed specifically for smaller organizations addresses a critical gap in the current market landscape. As service delivery becomes increasingly complex, the ability to capture and apply lessons from every disruption will separate industry leaders from the rest. Organizations that invest in systematic post-incident workflows today will build more resilient foundations for tomorrow. The focus must remain on practical usability, consistent data collection, and continuous process refinement. Technical excellence depends not only on rapid recovery but on the disciplined application of knowledge gained during challenging moments.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)