Intelligent sampling in Microsoft Foundry: the science behind selecting better production traces
TL;DR
Microsoft Foundry's intelligent sampling feature (used when creating an evaluation or fine-tuning dataset from production agent traces) uses a MinHash farthest-first diversity sampler. On WildChat (the primary validation dataset, sampling 100 items from a 5,000-trace pool), diversity sampling produces +29.1% higher lexical diversity and +44.8% larger vocabularies than a uniform-random baseline; across five additional datasets (Dolly, No Robots, OASST2, ShareGPT-GPT4, UltraChat), vocabulary gains range from +5.7% to +86.3%. An LLM judge prefers diversity-sampled data 78% of the time for evaluation and 71% for training (268 paired judgments). By design, the technique prioritizes coverage of agent behavior over mirroring production frequencies — which is exactly what most evaluation and fine-tuning workflows benefit from. This post shares the science behind the approach, how we validated it, and where it shines.
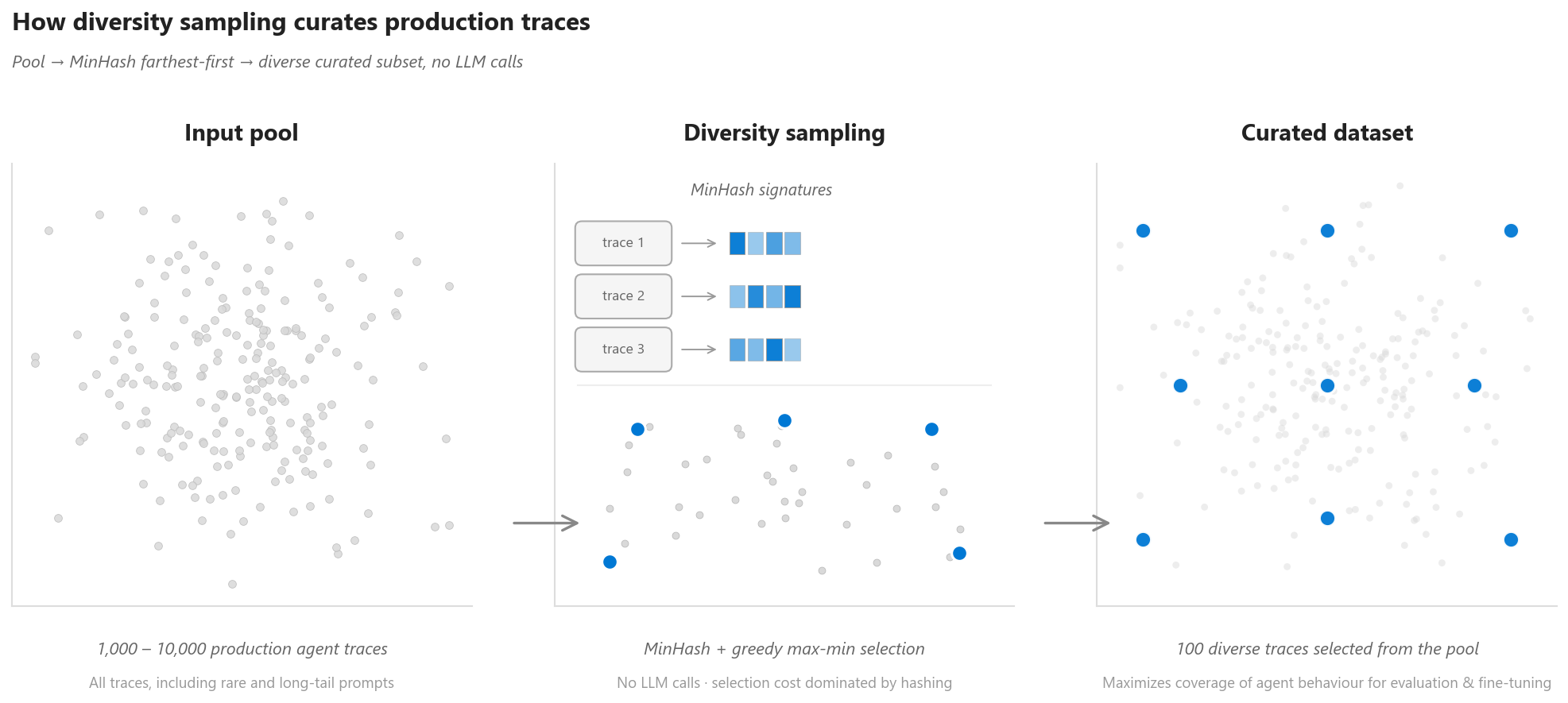
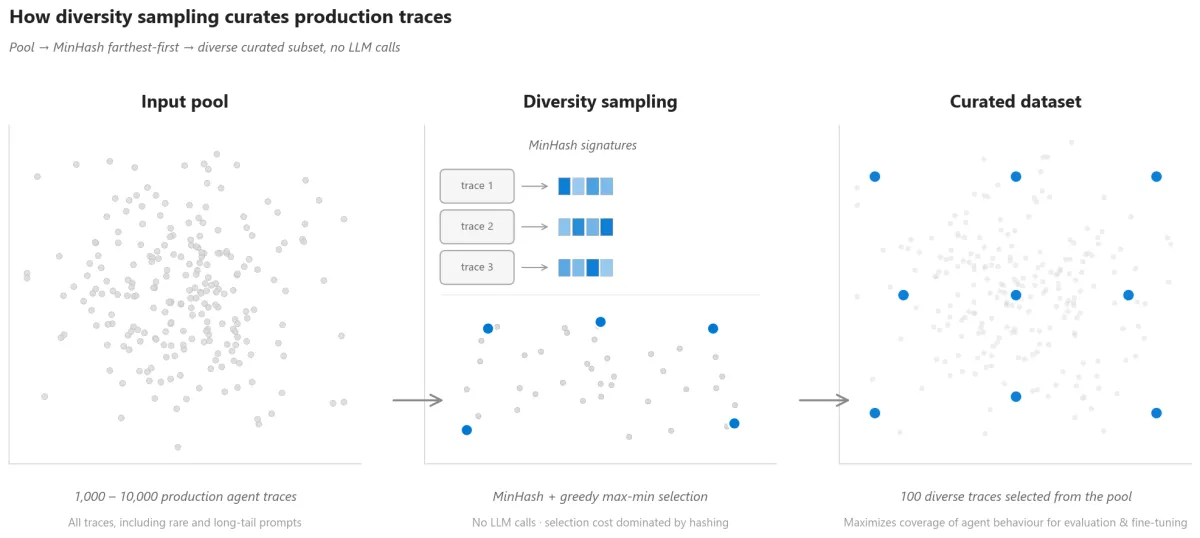
Figure 1. The intelligent-sampling flow at a glance: a pool of agent traces, the MinHash farthest-first selection step, and the resulting curated subset that maximizes coverage of agent behavior.
What we mean by “better.” Throughout this post, we evaluate intelligent sampling against three operational definitions of “better”:
- Lexical variety — unigram diversity (unique tokens / total tokens) and vocabulary size of the selected subset; capturing whether the subset covers more of the input space.
- LLM-judge preference — pairwise GPT-4.1 judgments comparing the diversity-sampled subset to a uniform-random subset, under two framings (“which is the better evaluation dataset?” and “which is the better training dataset?”).
- Human-rated quality — for three datasets with genuine human quality annotations (HelpSteer2, OASST2, OpenAI’s Summarize from Feedback), the mean human-annotator quality score of the items each method selects; confirming diversity sampling doesn’t systematically pick worse items.
Why trace selection matters
The simplest conceptual approach to picking traces is uniform random selection. It's statistically unbiased and preserves the true input distribution of your production traffic — a clear baseline that's the right choice when mirroring production frequencies matters. But uniform sampling has a well-known weakness: when your real traffic is dominated by a small number of common patterns, a uniform sample is dominated by those same patterns. Rare prompts, unusual tool-call sequences, and edge cases are systematically under-represented — exactly the cases evaluation is supposed to stress-test, and exactly the cases fine-tuning needs to learn from.
Diversity sampling explicitly addresses this gap. The goal is to select a subset that covers as much of the input space as possible — including the less-frequent regions a uniform sample would systematically miss. By design, it prioritizes coverage over mirroring production frequencies, which makes it particularly well-suited for evaluation and fine-tuning workflows where breadth of behavior matters.
The technique: MinHash + farthest-first traversal
Intelligent sampling runs server-side in Foundry with no LLM calls and no external embedding-model dependencies — selection is pure hashing-based, so it adds zero per-token cost and completes in seconds-to-minutes. It combines two classic, well-understood components:
MinHash signatures. Each trace's user text is tokenized into shingles and hashed with 128 permutations. The resulting fixed-size signature lets us estimate the Jaccard similarity between any two traces in constant time, without storing or comparing the original text. This is the same trick that powers near-duplicate detection in search engines.
Farthest-first traversal. Starting from a seed trace, repeatedly select the trace whose minimum similarity to any already-selected trace is smallest — in other words, the trace that is most different from everything chosen so far. This greedy algorithm is a standard approximation for the maximum-diversity subset selection problem.
Diversity sampling — the MinHash farthest-first algorithm — is the core selection mechanism used when you create a dataset from traces. It runs after a small set of supporting steps: exact deduplication to remove redundant traces, hard filters to drop malformed or trivial ones, and aggregation across an agent's runs. Our validation work focuses on whether the diversity-sampling step itself drives the quality gains we measure.
Selection cost is independent of trace content (no LLM or embedding-model calls), scales linearly in pool size, and is dominated by hashing — negligible compared with running the evaluation or fine-tuning job that consumes the result.
How we validated the method
A diversity sampler can be evaluated along several axes. We split our work into four complementary studies, designed to assess the technique's value from independent angles.
Intrinsic diversity metrics. Unigram diversity (unique tokens divided by total tokens, a length-normalized measure of lexical variety) and vocabulary size (count of unique tokens across the selected subset). Both are aggregated across 5 random seeds and compared via paired t-tests.
LLM-as-judge preference. A blinded GPT-4.1 judge scored pairwise comparisons (diversity-sampled vs. uniform-random subsets, each containing 10 trace examples) across 268 judgments spanning three dataset sizes (1k / 5k / 10k) and five seeds. The judge is asked which subset would produce a better evaluation dataset, and separately which would produce a better training dataset, with reasoning. A second judge (GPT-5.2) was run on 50 shared comparisons to test directional robustness across judge models.
Downstream supervised fine-tuning. We fine-tuned gpt-4.1 using the standard OpenAI fine-tuning API (supervised fine-tuning on <prompt, response> pairs) on two 80-example WildChat subsets — one diversity-sampled, one randomly selected — held out 20 additional examples for validation, and ran 3 epochs each. We measured training convergence (train loss, validation loss, token accuracy) and held-out pairwise generation quality on 48 unseen prompts judged by a blind GPT-4.1 evaluator.
Golden-dataset quality. We re-ran the sampler against three datasets with genuine human quality annotations — HelpSteer2 (Scale AI professionals), OASST2 (13.5K crowd-sourced volunteers), and OpenAI's Summarize from Feedback (crowd workers) — to ask whether selecting for diversity systematically picks lower-quality items according to human raters.
All experiments use five deterministic seeds for the random baseline, paired t-tests for statistical significance, and the same sampler configuration (num_perm=128, alpha=0.35, target=100). The primary dataset is WildChat — 1k, 5k, and 10k subsets of real user / chatbot conversations — supplemented by five cross-dataset studies on Dolly, No Robots, OASST2, ShareGPT-GPT4, and UltraChat. Golden-dataset quality validation uses HelpSteer2, OASST2, and OpenAI's Summarize from Feedback.
What the data says
Before the aggregate numbers, here is what diversity sampling actually does on real production traces. We embedded all 5,000 WildChat user prompts with a sentence-transformer model and projected them into 2D — every grey dot is one trace, and the colored markers are the 100 traces each method selected:
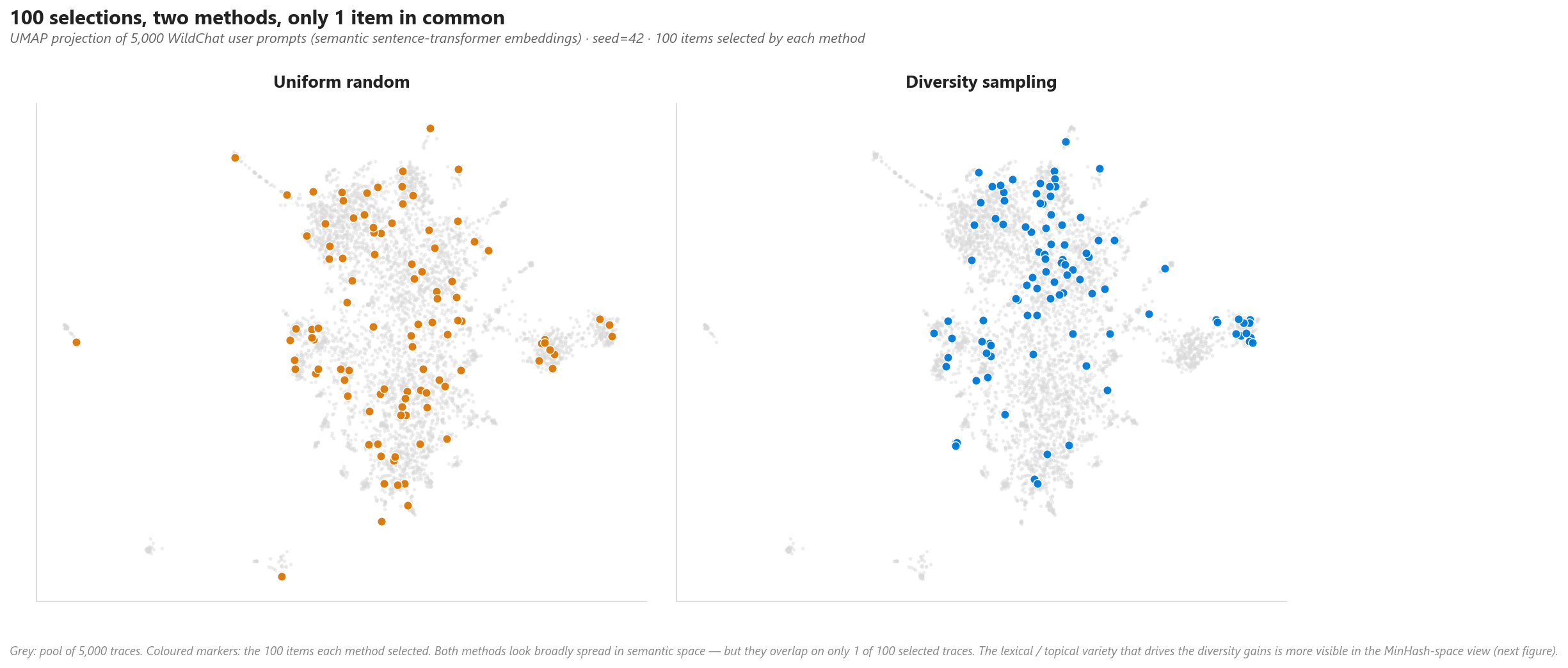
Figure 2. Semantic view — UMAP of sentence-transformer embeddings. Each grey dot is one trace; colored markers are the 100 traces each method picked. Both methods look broadly spread in semantic space, yet they share only 1 of 100 selected traces — the methods reach genuinely different content, even where the spatial coverage looks similar.
Second, the MinHash–Jaccard space the algorithm actually optimizes on. Instead of a 2D projection (which loses the fine-scale distance information the algorithm cares about), we plot the distance distributions directly:
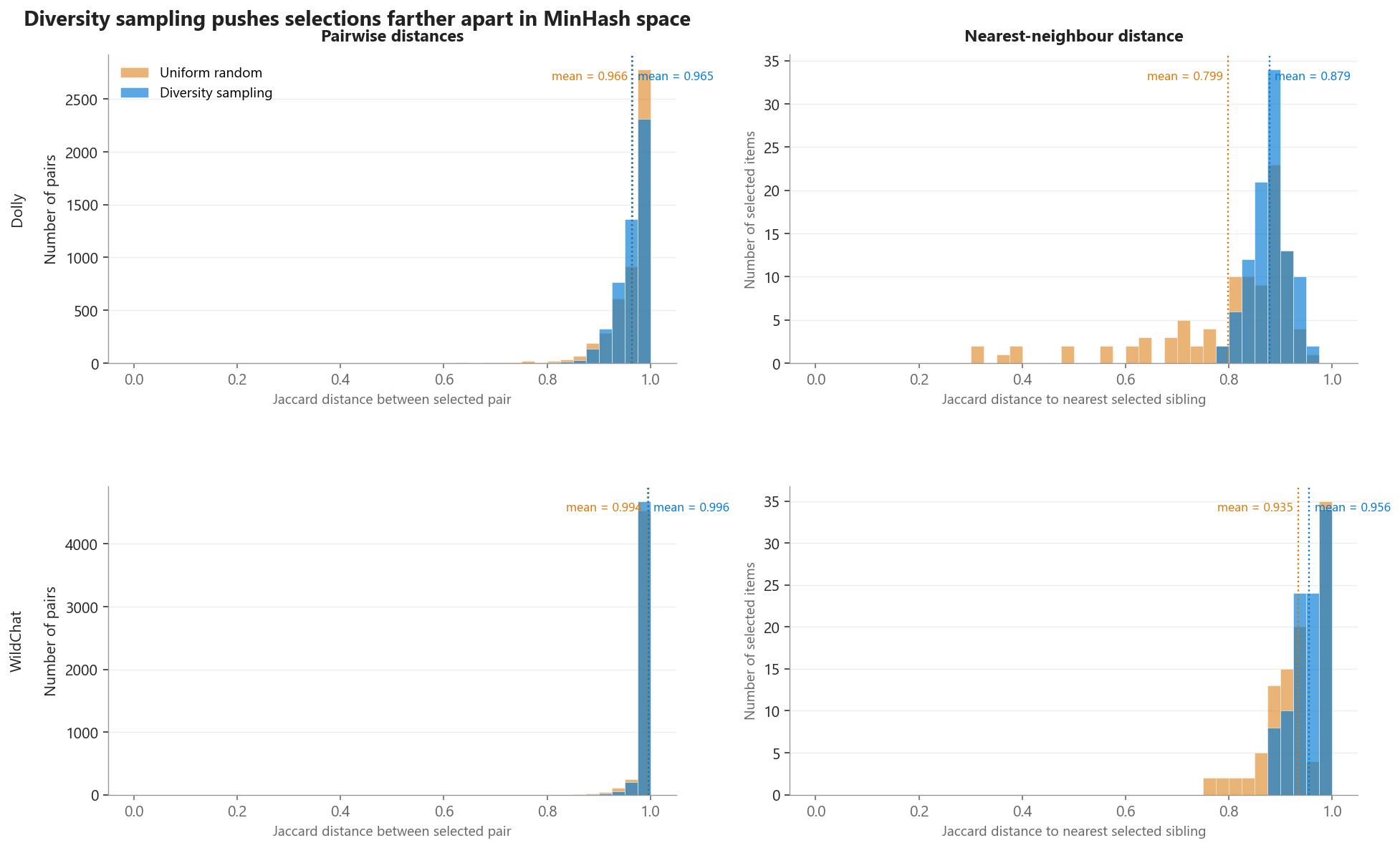
Figure 3. Pairwise (left) and nearest-neighbour (right) Jaccard-distance distributions between the 100 selected items, on Dolly and WildChat. Random sampling produces a long left tail in nearest-neighbour distance — some random picks have near-duplicate siblings in the selected set. Diversity sampling explicitly maximises every selection’s min-distance, lifting the entire distribution to the right. On Dolly the gap is dramatic (mean +0.08, with random’s left tail reaching down to 0.3). On WildChat the gap is smaller because the pool already has high baseline diversity — there are simply fewer near-duplicates to avoid.
The two methods select almost entirely different traces (99 unique each, 1 in common) — and the visual difference foreshadows what the aggregate metrics will show. The rest of this section quantifies the gap on four independent axes.
Diversity gains are large and consistent
On the primary WildChat dataset (5k pool, 100 selected, 5 seeds), diversity sampling produces measurably and significantly more diverse subsets than a uniform-random baseline:
|
Metric |
Diversity sampling |
Random |
Δ% |
p-value |
|
Unigram diversity |
0.307 |
0.238 |
+29.1% |
0.010 |
|
Vocabulary size |
7,019 |
4,849 |
+44.8% |
0.003 |
Vocabulary gains generalize to five additional datasets (Dolly +5.7%, No Robots +44.5%, OASST2 +55.7%, ShareGPT-GPT4 +86.3%, UltraChat +49.3%), with the strongest effects on human-authored data.
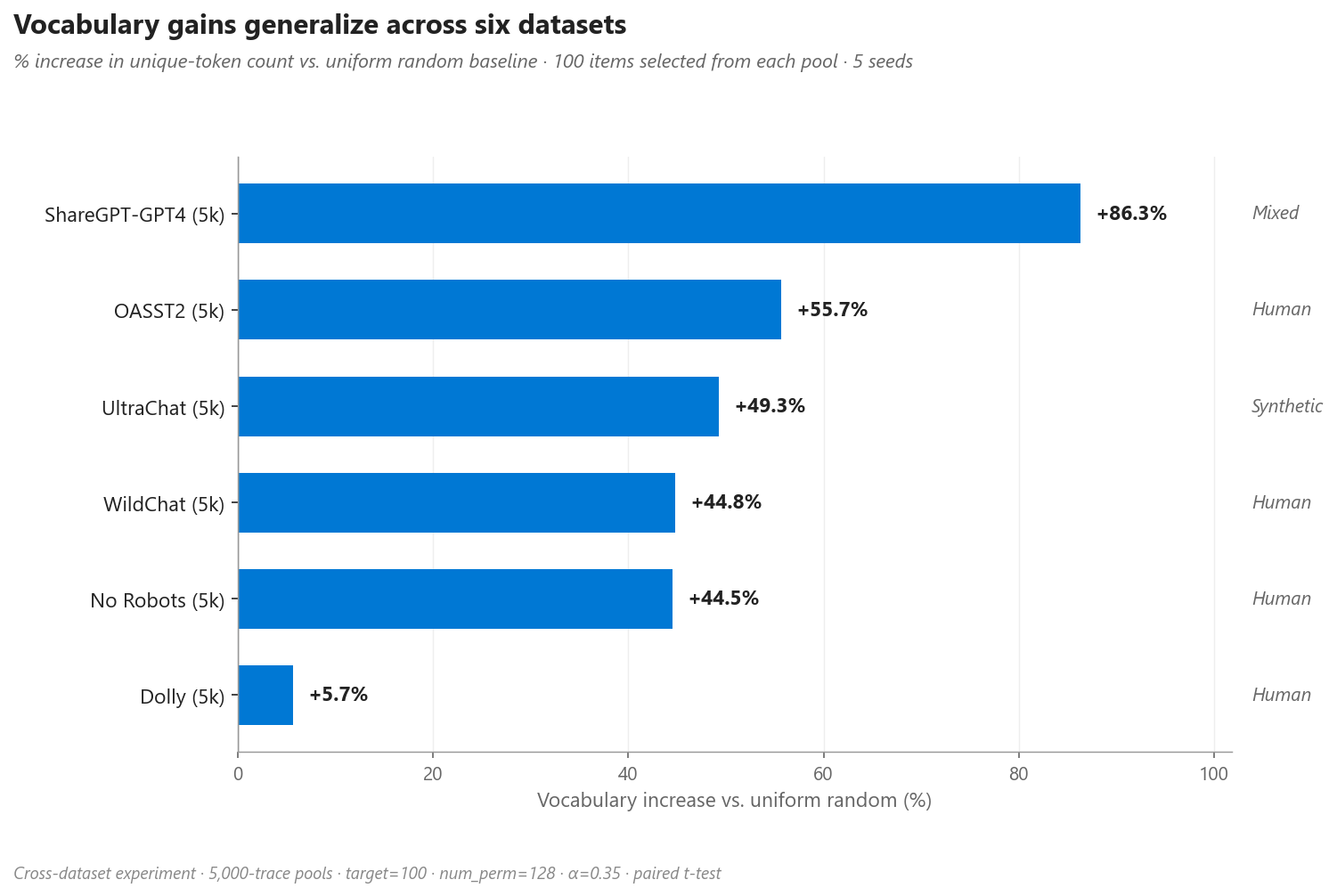
Figure 4. Vocabulary increase relative to a uniform-random baseline, across six datasets. Vocabulary gains are positive on every dataset but vary widely with how lexically rich the underlying pool is — ShareGPT-GPT4 (long, varied conversational turns) has the most room for the sampler to spread out, while Dolly (short, formulaically-written instructions) leaves the sampler with the least lexical variety to surface.
LLM judges prefer diversity-sampled data
We ran 268 pairwise judgments using GPT-4.1 across two framings (which sample produces a better evaluation dataset, and which produces a better training dataset). Aggregated win rates:
|
Framing |
Diversity sampling wins |
Random wins |
|
Evaluation dataset |
78.0% (209/268) |
22.0% (59/268) |
|
Training dataset |
71.3% (191/268) |
28.7% (77/268) |
Diversity-sampled subsets win across all three dataset sizes (1k, 5k, 10k). A secondary GPT-5.2 judge run on 50 shared comparisons reproduced the same directional result, with 76% raw agreement on the evaluation framing and 68% on training — supporting the conclusion that the gap is not specific to a single judge model.
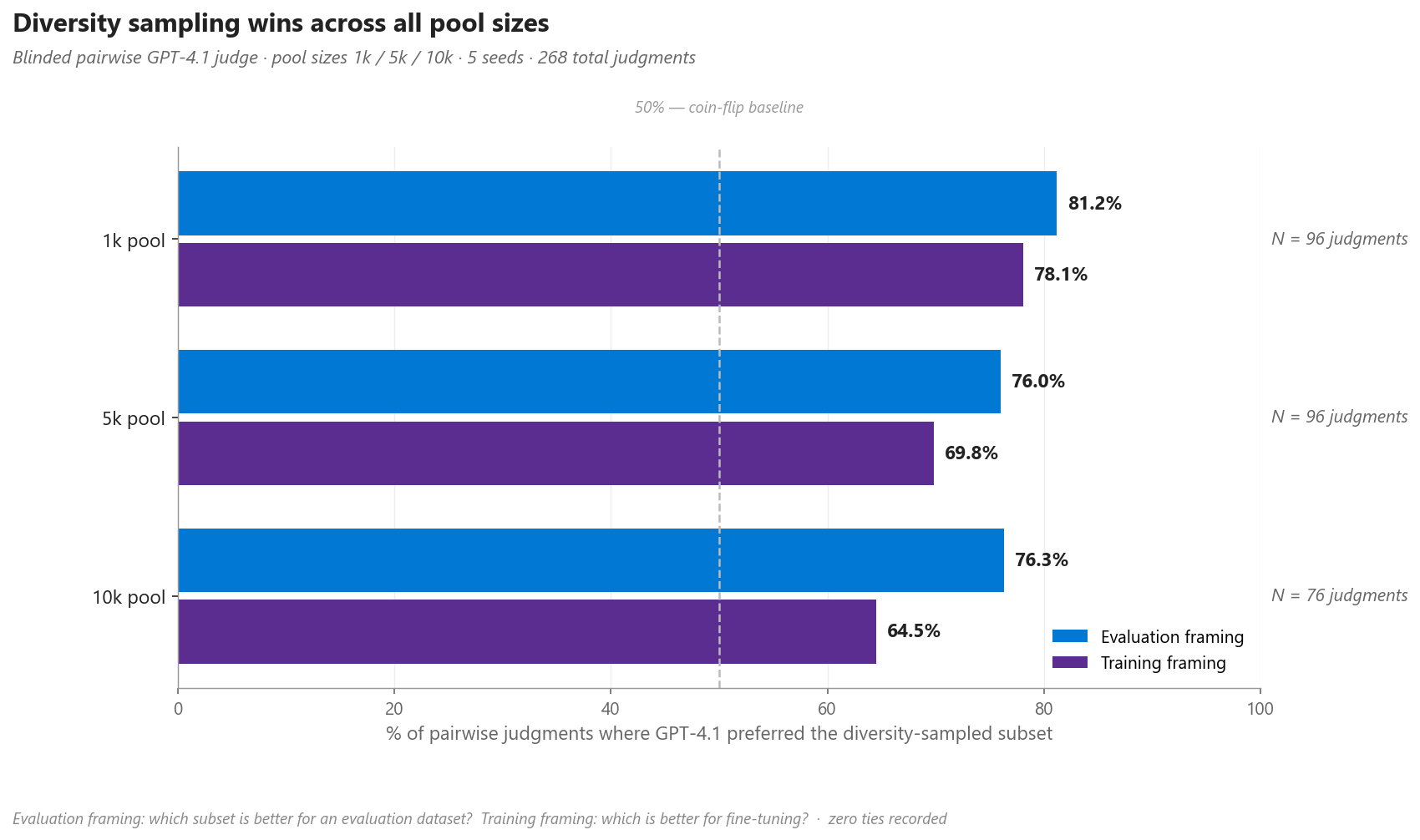
Figure 5. Per-pool-size pairwise win rates for the diversity-sampled subset, across both evaluation and training framings. The 50% dashed line is the coin-flip baseline; every bar is well above it.
Vocabulary gain and judge preference measure different things — lexical variety in the selection vs. a holistic quality signal. They mostly agree, but not always:
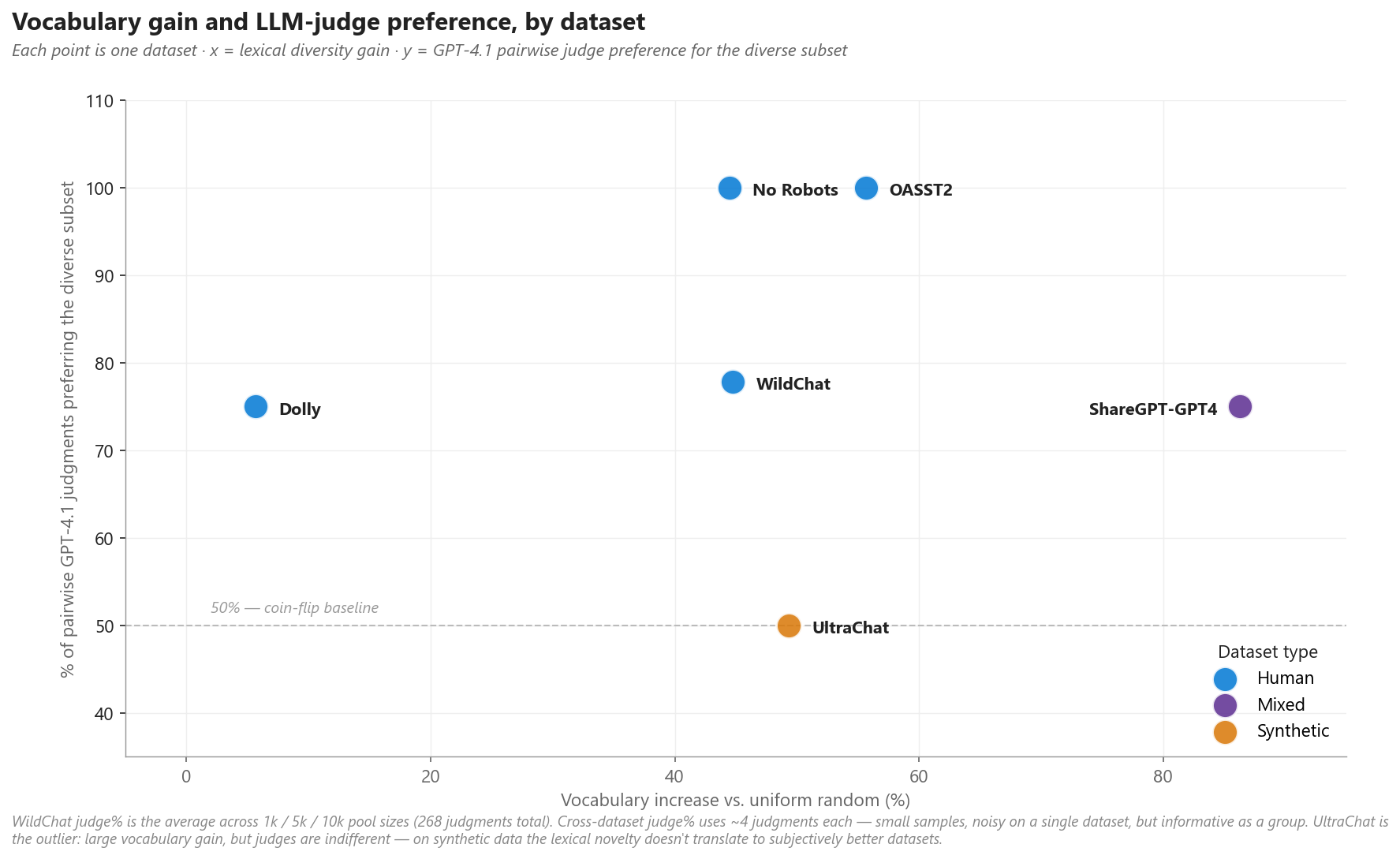
Figure 6. Vocabulary gain vs. LLM-judge preference, one point per dataset. Four datasets (No Robots, OASST2, WildChat, Dolly) sit in the win-win region — diversity sampling delivers measurable lexical gains and judges prefer the curated subset. ShareGPT-GPT4 produces the largest vocabulary lift but a more modest judge preference. UltraChat is the clear outlier: a +49% vocabulary gain that doesn’t translate to any judge preference — on this fully-synthetic dataset the lexical novelty is real but judges don’t see the resulting subset as meaningfully better. Cross-dataset judge percentages come from a small (~4 judgments each) experiment, so individual-dataset values are noisy; WildChat’s 78% is the high-confidence anchor from 268 judgments.
The UltraChat result is informative on its own: on fully-synthetic datasets — where both sides of the conversation are model-generated — diversity sampling still surfaces lexical variety, but judges don’t see the resulting subset as meaningfully better, likely because the underlying conversations are already homogeneously phrased and there is less long-tail variation left to surface.
Fine-tuning: faster convergence, similar final quality
We ran a supervised fine-tuning experiment on gpt-4.1 using the standard OpenAI fine-tuning API: two 80-example WildChat subsets (diversity-sampled vs. randomly selected), 20 held-out validation examples, 3 epochs each.
|
Metric |
Diversity sampling |
Random |
Δ |
|
Final train loss |
0.547 |
0.908 |
−40% |
|
Train token accuracy |
85.3% |
76.7% |
+8.6pp |
|
Validation loss |
0.869 |
0.873 |
comparable |
|
Holdout pairwise (N=48) |
37.5% wins |
33.3% wins |
not significant |
Training dynamics differ sharply: the diversity-sampled model converges by epoch 2 and reaches 40% lower training loss. On held-out generation quality, both models perform comparably (37.5% vs. 33.3% pairwise wins, not statistically significant at N=48) — confirming that the diversity advantage does not hurt downstream model quality.
Quality holds up across human-annotated datasets
A natural concern with diversity sampling is that it might over-select hard, weird, or low-quality items. We tested this on three datasets with genuine human quality annotations:
|
Dataset |
Annotators |
Quality dimension |
Diversity |
Random |
Δ% |
|
HelpSteer2 |
Scale AI pros |
Helpfulness (0–4) |
2.66 |
2.94 |
−9.7% |
|
OASST2 |
13.5K volunteers |
Quality (0–1) |
0.72 |
0.67 |
+8.1% |
|
Summarize FB |
Crowd workers |
Overall (1–7) |
5.16 |
4.77 |
+8.3% |
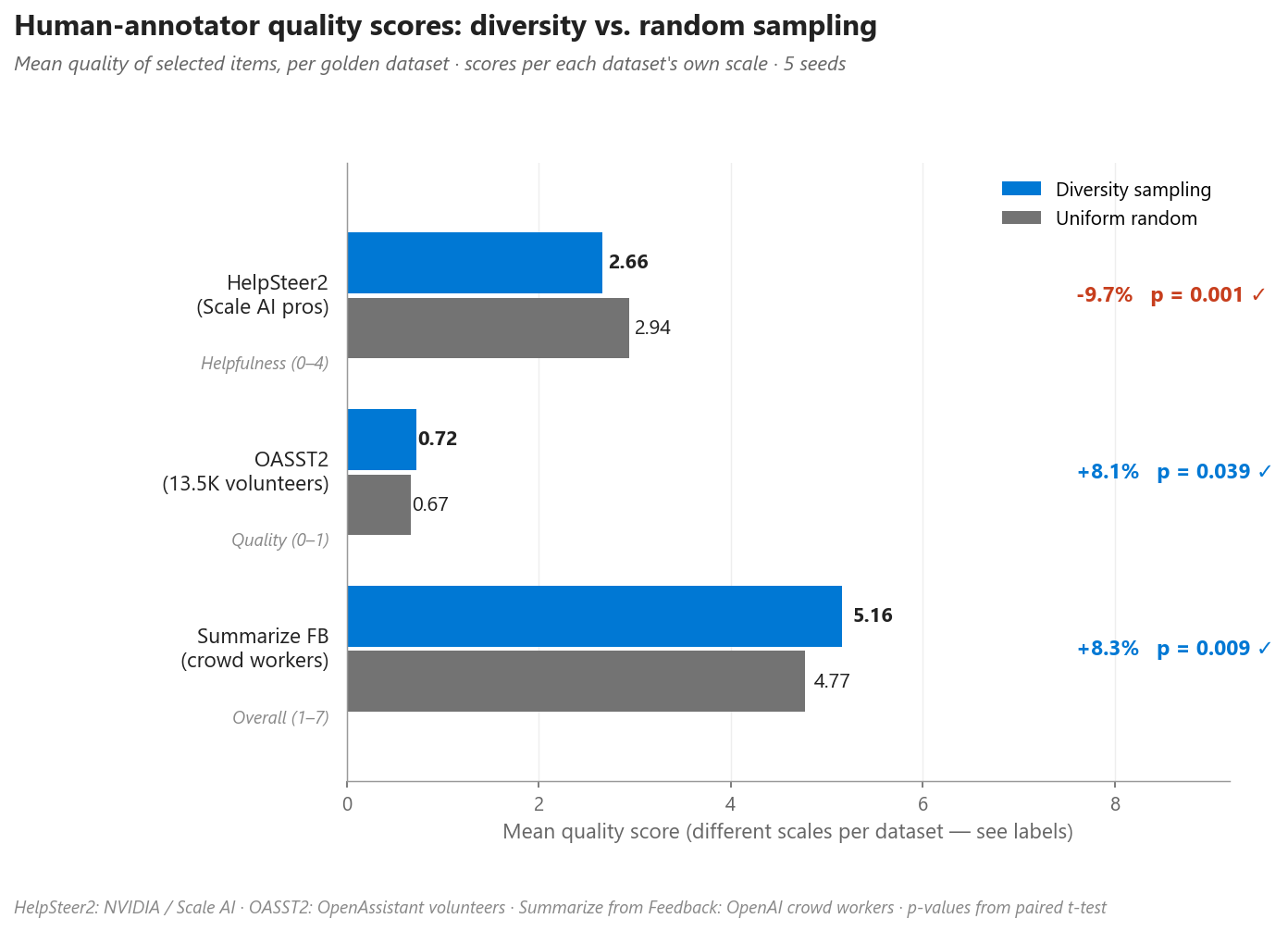
Figure 7. Human quality scores for diversity-sampled vs. uniform-random subsets, on each dataset’s own annotation scale. Diversity sampling produces statistically-significant quality gains on OASST2 and Summarize from Feedback, and a statistically-significant quality drop on HelpSteer2 — see the qualitative examples in the next section for why.
On two of three datasets, diversity sampling selects items rated as higher-quality by human annotators (OASST2 +8.1%, Summarize from Feedback +8.3%). On HelpSteer2 the trend reverses: diversity sampling picks more creative-writing, roleplay, and niche-topic prompts which human annotators systematically rate as harder, and therefore lower in helpfulness. Both methods select a similar number of score-zero items; the gap is in the mid-to-high range of the scale.
To see where the HelpSteer2 quality gap actually lives, here is the full distribution of helpfulness scores for items selected by each method:
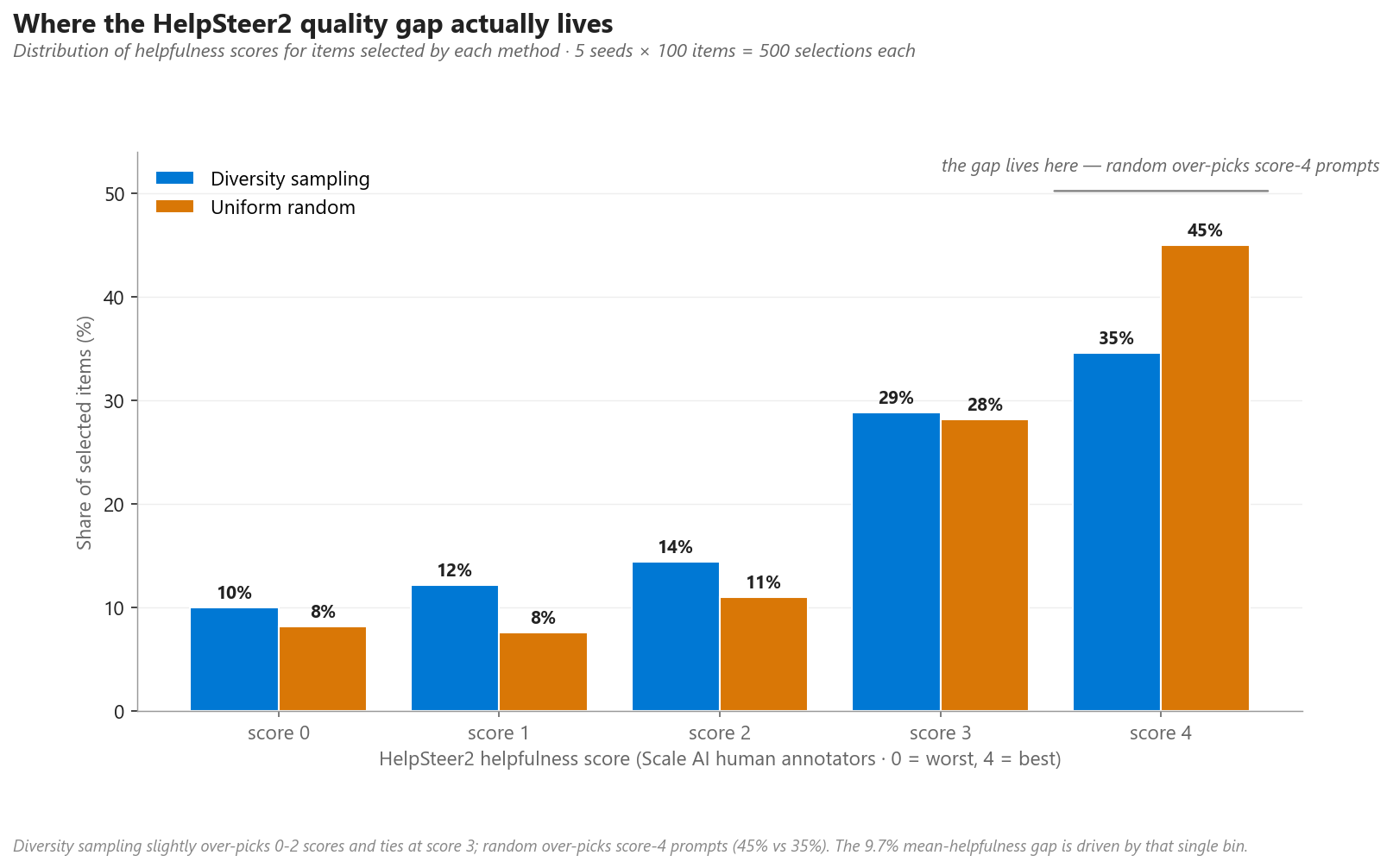
Figure 8. Distribution of HelpSteer2 helpfulness scores for the 500 items each method selected across 5 seeds. Diversity sampling slightly over-picks low- and mid-scoring items (scores 0–2) and ties random at score 3, while random over-picks the highest-scoring score-4 prompts (45% vs. 35%) — the common, well-trodden requests where models already produce reliable answers. The 9.7% mean-helpfulness gap is driven almost entirely by that single score-4 bin.
Note: OpenAI's Summarize from Feedback is a summarization task (Reddit / CNN articles), not general instruction-following. We include it for annotation methodology breadth.
What the sampler actually picks
To make the diversity-vs-coverage trade-off concrete, here are real examples of items selected by each method on HelpSteer2 (seed=42). Of 100 items selected by each method, only 3 overlapped — the two methods choose almost entirely different subsets.
Diversity-sampled examples (selected by diversity sampling, skipped by random):
|
# |
User prompt (truncated) |
Helpfulness |
Correctness |
Coherence |
|
1 |
I have a vacation rental website and I am looking for alliterative and descriptive headlines that are 4–5 words in length. Examples: "Get Away to Galveston", "Sleep Soundly in Seattle". Each headline should have at least 50% alliteration… |
2 |
2 |
4 |
|
2 |
You are a branding consultant with a creative mind. Give me 30 naming ideas for a baby’s website for parents in a table format. |
1 |
1 |
2 |
|
3 |
my table has dates and USD values. give me historical exchange rates for each date for USD to Euro. also the converted USD to EU value: 01/02/2021 84.62 / 01/03/2021 79.48 / 01/04/2021 79.69 / 01/05/2021 38.06 / 01/06/2021 58.46… |
0 |
0 |
2 |
Randomly-selected examples (selected by random, skipped by diversity sampling):
|
# |
User prompt (truncated) |
Helpfulness |
Correctness |
Coherence |
|
1 |
How to cook t-bone in the oven |
4 |
4 |
4 |
|
2 |
Create a 4-day dumbbell and EZ-bar workout program to build over 10lbs of muscle in 3 months |
3 |
3 |
4 |
|
3 |
How did life originate? |
3 |
3 |
4 |
The diversity-sampled prompts are unusual, creative, and underspecified — writing tasks with unusual constraints, open-ended branding requests, and ill-formed data tasks the model can’t reliably answer — exactly the kinds of inputs an evaluation suite or fine-tuning corpus should stress-test. The randomly-selected prompts are common, well-trodden requests where models already produce reliable, high-scoring responses. The quality-score gap (3–10%) is a direct consequence of this content shift, not a sign that diversity sampling is picking lower-quality work.
Considerations
Diversity sampling is a powerful default for evaluation and fine-tuning workloads, but a few honest considerations are worth flagging for practitioners:
- Coverage, not representativeness. By design, diversity sampling emphasizes breadth of behavior over mirroring production frequencies. For use cases that need a faithful population estimate (latency, error rates), a uniform sample is the better fit.
- Synthetic data sees smaller gains. On fully-synthetic datasets (e.g. UltraChat), the underlying conversations are already pre-diversified by the generation process, so the technique has less signal to work with.
- Fine-tuned model quality is comparable, not dramatically better. Diversity sampling accelerates training convergence and produces richer datasets, but at the scales we tested, held-out generation quality is on par with a uniform-random baseline.
- The diversity-vs-quality trade-off is dataset-specific. Two of three human-annotated datasets show higher quality scores with diversity sampling; one (HelpSteer2) shows lower scores, driven by selection of harder, more creative prompts.
Where diversity sampling shines
Across our evaluation, the technique consistently helps for workloads where broad input coverage drives downstream quality, and adds less value for workloads that depend on faithful production frequencies:
|
Workload |
Diversity sampling fit |
|
Fine-tuning data selection |
Strong — faster convergence, broader coverage |
|
Rubric & evaluator generation |
Strong — surfaces clearer evaluation themes |
|
Long-tail evaluation suites |
Strong — maximizes input-space coverage |
|
Quality-critical training |
Strong — pair diversity coverage with manual review of selected items |
|
Production-distribution benchmarking |
Weaker — uniform sample mirrors true frequencies |
|
Pre-curated or synthetic data |
Weaker — data is already diverse |
Closing thoughts
Intelligent sampling — MinHash diversity sampling — gives Foundry developers a fast, zero-extra-cost way to curate higher-coverage datasets from their production traces. In our evaluation, the technique consistently delivered measurable diversity gains, was strongly preferred by LLM judges for both evaluation and training framings, and accelerated fine-tuning convergence — while running in under a minute on typical trace pools.
It’s worth keeping the scope clear: the technique is designed for breadth of behavior, not faithful production-frequency representation. For most evaluation and fine-tuning workloads, broader coverage is exactly what you want — and that’s where this feature shines.
Try it out. If you’re building agents on Microsoft Foundry, enable Application Insights on your project, head to the Traces tab, and try creating your first dataset from traces. See the official documentation for step-by-step instructions: Convert agent traces into evaluation datasets (preview). Two Python samples — one for evaluation, one for fine-tuning — are available in the azure-ai-projects SDK: azure-sdk-for-python / datasets samples. We’d love to hear how it works for your workloads.
Get Started
Start building in Microsoft Foundry: ai.azure.com
Check out Observability BRK252 session: aka.ms/build26-BRK252
Read the docs: Foundry observability documentation
Join the community: aka.ms/ai/discord
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)