Early 2026 LLM Research Trends and Academic Developments
This article surveys the broader landscape of large language model research from January to May 2026. It explores shifting evaluation methodologies, the ongoing evolution of model architectures, and the practical implications of recent academic publications for developers and researchers navigating the field.
The academic landscape surrounding large language models continues to evolve at a rapid pace. Researchers and practitioners alike are navigating a period of intense scrutiny regarding how these systems are built, measured, and deployed. The first half of 2026 has brought renewed attention to the foundational principles that guide model development. Understanding these developments requires looking beyond individual publications to examine the broader methodological shifts occurring across the field.
This article surveys the broader landscape of large language model research from January to May 2026. It explores shifting evaluation methodologies, the ongoing evolution of model architectures, and the practical implications of recent academic publications for developers and researchers navigating the field.
What is driving the current shift in large language model evaluation?
Traditional benchmarking approaches are facing increasing scrutiny from the academic community. Researchers are recognizing that static test sets often fail to capture the dynamic capabilities required for real-world applications. This realization has prompted a move toward more dynamic and context-aware assessment frameworks. The focus has gradually expanded from simple accuracy metrics to comprehensive evaluations of reasoning, safety, and computational efficiency. Scholars are now prioritizing methodologies that reflect how models interact with complex, evolving information environments. This transition demands rigorous peer review and reproducible experimental designs. The community is actively debating the most effective ways to measure progress without relying on outdated metrics.
Academic institutions are actively developing new protocols to replace static evaluation methods. These newer frameworks emphasize continuous interaction and adaptive testing procedures. Researchers are designing environments where models must navigate unpredictable scenarios rather than memorize fixed answers. This shift requires substantial investment in infrastructure and standardized testing suites. The community is also examining how to measure robustness across diverse linguistic and cultural contexts. Scholars argue that true progress can only be assessed through comprehensive, multi-dimensional analysis. The move away from simple accuracy scores reflects a broader understanding of system complexity.
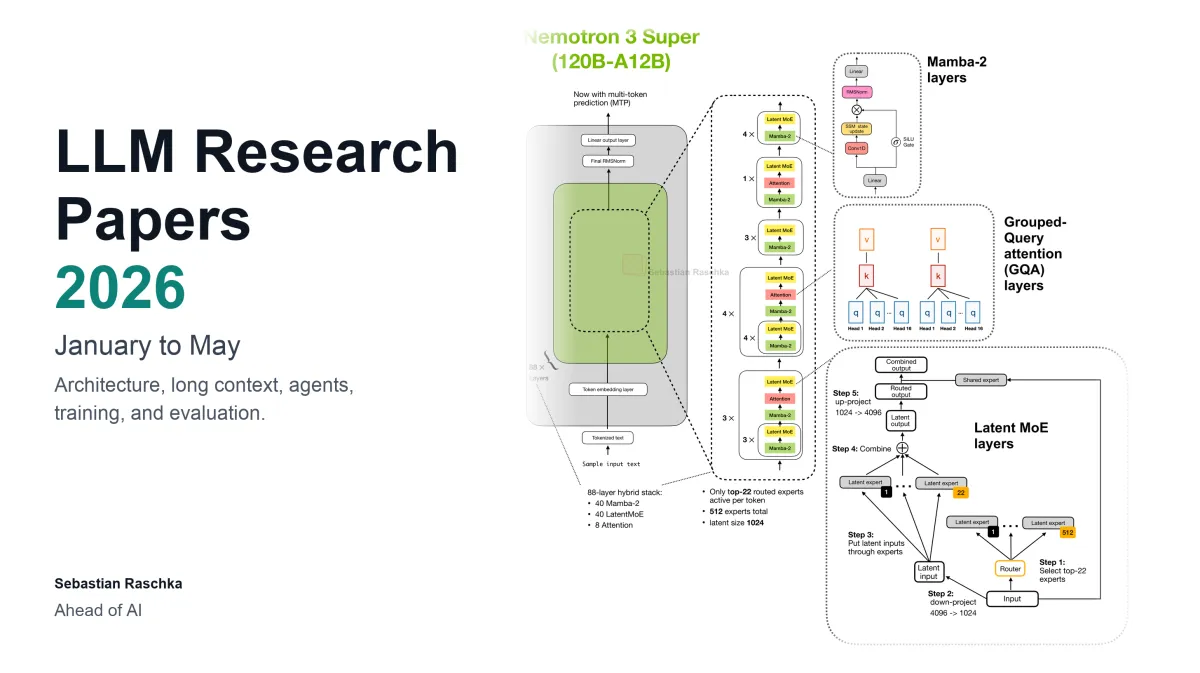
How do architectural innovations influence practical deployment?
The ongoing refinement of model architectures continues to shape how these systems are integrated into professional workflows. Developers are increasingly interested in designs that balance computational cost with performance gains. The industry has observed a clear trend toward more efficient parameter utilization and improved training stability. These technical adjustments directly impact the feasibility of running advanced models on standard hardware. Researchers are exploring novel attention mechanisms and optimization techniques that reduce memory overhead. The practical implications extend to energy consumption and infrastructure requirements. Organizations must carefully weigh the benefits of cutting-edge designs against their existing technical constraints.
The complexity of modern artificial intelligence research exceeds the capacity of any single institution. Collaborative efforts allow researchers to pool computational resources, share datasets, and cross-validate results across different environments. This cooperative model accelerates the pace of discovery while reducing redundant experimentation. Open repositories and shared benchmarks enable independent verification of reported performance gains. The academic ecosystem thrives when knowledge is distributed rather than concentrated. This approach fosters a more resilient research community capable of addressing complex challenges. The long-term viability of the field depends on sustained cooperation across institutional boundaries.
What role does academic publishing play in shaping industry standards?
Scholarly publications serve as the primary mechanism for validating new research findings and establishing consensus. The peer review process ensures that experimental results meet rigorous scientific standards before entering the broader discourse. This validation step is crucial for distinguishing genuine advancements from incremental improvements. The academic community relies on transparent methodology and open data sharing to verify claims. When researchers publish their findings, they provide a reference point for subsequent studies and engineering efforts. This continuous cycle of publication and replication drives the field forward. The relationship between academic inquiry and industrial application remains deeply interconnected.
Engineering teams are adapting their development pipelines to align with these new academic standards. The emphasis on reproducibility has led to stricter requirements for code sharing and documentation. Practitioners are learning to prioritize transparency over rapid deployment cycles. This cultural shift encourages more deliberate experimentation and thorough validation phases. The industry is also seeing increased investment in independent auditing and third-party verification services. These changes aim to build greater trust in published results and reduce the risk of overclaiming capabilities. The long-term goal is to establish a more reliable foundation for future innovation.
Why does open collaboration matter for long-term research sustainability?
The rapid expansion of computational requirements has made isolated research increasingly difficult to sustain. Large-scale training runs demand specialized hardware that few organizations can maintain independently. This reality has pushed the academic community toward shared infrastructure and distributed computing networks. Researchers are increasingly relying on cloud platforms and public computing grants to run experiments. These shared resources allow smaller teams to participate in high-level research without prohibitive costs. The democratization of computational access has broadened the diversity of voices in the field. It also encourages cross-institutional partnerships that accelerate knowledge transfer.
Open collaboration extends beyond hardware to include data curation and benchmark development. Standardized datasets reduce the friction of comparing new models against established baselines. When researchers contribute to shared repositories, they help maintain a common language for progress. This collective effort prevents the fragmentation of evaluation standards across different labs. It also ensures that methodological improvements are widely accessible rather than confined to proprietary systems. The sustainability of the field relies on this continuous exchange of tools and techniques. Closed ecosystems ultimately slow the pace of scientific discovery.
How are researchers addressing the limitations of traditional benchmarking?
Academic institutions are actively developing new protocols to replace static evaluation methods. These newer frameworks emphasize continuous interaction and adaptive testing procedures. Researchers are designing environments where models must navigate unpredictable scenarios rather than memorize fixed answers. This shift requires substantial investment in infrastructure and standardized testing suites. The community is also examining how to measure robustness across diverse linguistic and cultural contexts. Scholars argue that true progress can only be assessed through comprehensive, multi-dimensional analysis. The move away from simple accuracy scores reflects a broader understanding of system complexity.
Practical implications emerge as organizations adapt their development pipelines to align with these new academic standards. The emphasis on reproducibility has led to stricter requirements for code sharing and documentation. Practitioners are learning to prioritize transparency over rapid deployment cycles. This cultural shift encourages more deliberate experimentation and thorough validation phases. The industry is also seeing increased investment in independent auditing and third-party verification services. These changes aim to build greater trust in published results and reduce the risk of overclaiming capabilities. The long-term goal is to establish a more reliable foundation for future innovation.
What practical implications emerge from recent methodological changes?
The trajectory of large language model research reflects a maturing discipline. As the field moves past its initial experimental phase, the emphasis has naturally shifted toward rigor, reproducibility, and practical utility. Scholars are building frameworks that prioritize sustainable development over rapid iteration. Practitioners are adapting their strategies to align with these evolving academic standards. The coming years will likely see continued refinement of evaluation protocols and architectural designs. The focus remains on establishing reliable foundations for future innovation.
Researchers are increasingly focusing on the long-term stability of deployed systems rather than short-term performance spikes. This perspective encourages more conservative release schedules and thorough stress testing. It also promotes the development of modular components that can be updated independently. The industry is learning to value consistency and safety alongside raw capability. These shifts will likely influence how funding is allocated and how research milestones are defined. The academic community continues to advocate for methods that prioritize transparency and verifiable progress.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.









Comments (0)