Microsoft Unveils Surface RTX Spark Dev Box for AI Developers
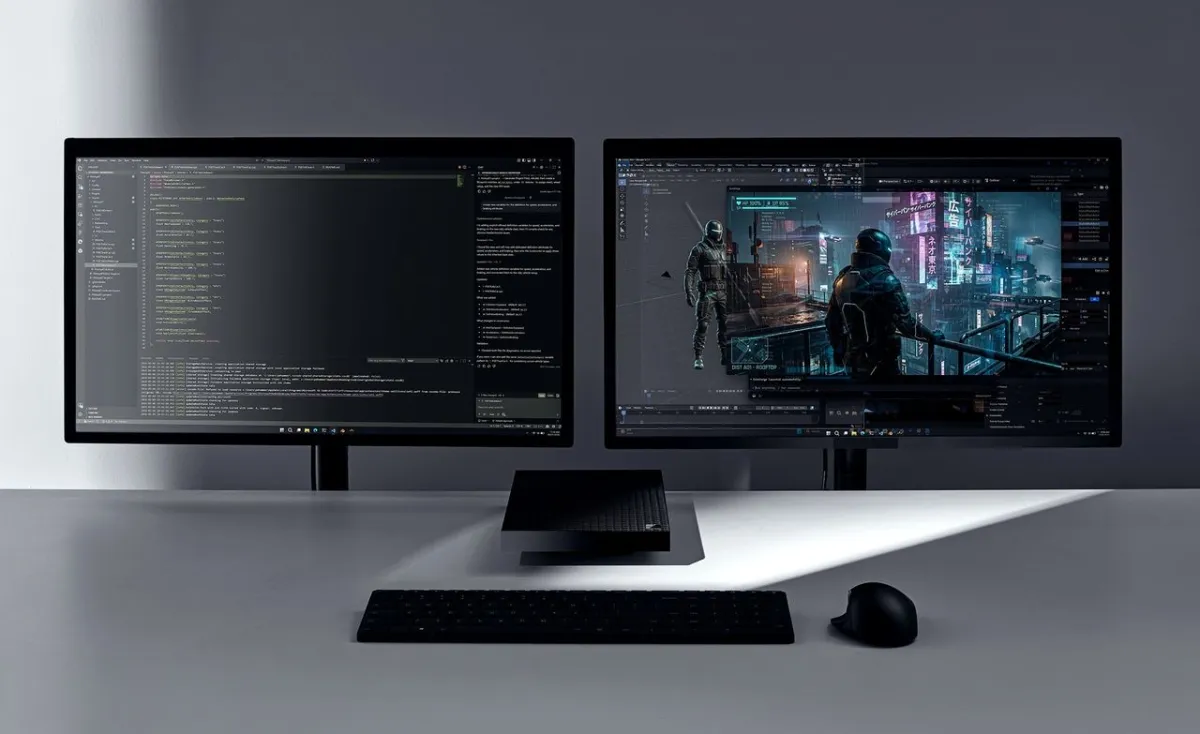
Microsoft has unveiled the Surface RTX Spark Dev Box, a compact mini-PC powered by Nvidia silicon. Designed specifically for developers, it delivers one petaflop of AI compute with 128GB of unified memory to support local model fine-tuning and agentic AI pipelines. The system features a specialized thermal design and comes preloaded with essential developer tools, with availability expected later this year in the United States.
The landscape of artificial intelligence development is shifting rapidly from cloud-dependent frameworks to localized, on-premise computing architectures. Developers now require hardware capable of handling complex computational tasks without relying on external data centers. Microsoft has introduced a new specialized machine designed specifically for this transition, aiming to bridge the gap between consumer-grade desktops and professional AI workstations.
What is the Surface RTX Spark Dev Box and how does it function?
The Surface RTX Spark Dev Box represents a dedicated hardware platform engineered specifically for artificial intelligence research and software development. Microsoft positioned this machine as a compact alternative to traditional rack-mounted servers or bulky workstations. The chassis utilizes an aluminum construction featuring a grid of one thousand air vents across the top surface. This ventilation layout draws direct visual inspiration from modern gaming consoles while serving a critical engineering purpose. Sustained computational loads generate significant heat, and the thermal envelope is strictly capped at one hundred watts. The ventilation system ensures that continuous processing does not trigger thermal throttling during extended operations.
The underlying architecture relies on Nvidia's RTX Spark system on a chip. This integrated processor combines central processing units, graphics processing units, and specialized tensor cores into a single silicon die. Unified memory architecture plays a crucial role in this design. The device ships with one hundred twenty-eight gigabytes of shared memory accessible by all processing components. This eliminates the traditional bottleneck where data must travel between separate memory pools. Models containing up to one hundred twenty billion parameters can reside entirely within the local memory space. Developers can execute inference and training routines without constant data swapping. The hardware delivers up to one petaflop of artificial intelligence compute throughput. This metric indicates the number of floating-point operations the system can perform per second. Such capacity enables rapid iteration cycles for software engineers testing new algorithms.
Connectivity options include two USB Type-C ports, an HDMI output, a standard USB-A port, an Ethernet jack, and a dedicated headphone socket. This configuration allows developers to connect multiple peripherals without relying on external docking stations. The physical layout prioritizes direct access to essential interfaces while maintaining a compact footprint. Engineers can attach storage drives, network equipment, and display monitors directly to the chassis. This streamlined approach reduces dependency on additional hardware accessories. The design reflects a careful balance between computational density and practical workspace integration.
Why does localized AI compute matter for modern development workflows?
The transition toward agentic artificial intelligence requires hardware that can operate continuously without network dependency. Cloud-based solutions have traditionally handled these workloads, but they introduce latency, subscription costs, and data privacy concerns. Local execution allows developers to iterate faster while maintaining complete control over sensitive information. Agentic systems must process complex decision trees and execute multi-step tasks autonomously. These operations demand consistent computational power that fluctuating cloud allocations cannot guarantee. A dedicated mini-PC provides a stable environment for running persistent background processes. Engineers can monitor resource utilization directly and adjust parameters in real time. This approach reduces infrastructure overhead and simplifies testing environments for distributed applications.
Software ecosystems have also evolved to support this hardware shift. Windows Subsystem for Linux version two now provides native compatibility with Nvidia's CUDA technology. This integration allows developers to leverage GPU acceleration within a familiar Windows environment. PowerShell seven offers advanced scripting capabilities for automating deployment pipelines. The machine arrives with Visual Studio Code and GitHub Copilot preinstalled, streamlining the initial setup process. Developers can immediately begin writing, debugging, and deploying code without configuring foundational software layers. This out-of-the-box readiness accelerates the transition from concept to functional prototype. The reduced friction encourages broader experimentation with machine learning frameworks.
The emphasis on local model fine-tuning reflects a broader industry trend toward personalized artificial intelligence applications. Organizations increasingly require customized models that understand specific operational contexts. Training these models on-premise ensures that proprietary data never leaves the secure environment. Developers can experiment with different architectures and hyperparameters without incurring external processing fees. The unified memory configuration supports large context windows necessary for advanced language processing tasks. This capability allows engineers to test complex reasoning patterns directly on their workstations. The hardware design ultimately supports a more autonomous and efficient development lifecycle.
How does the thermal and physical design address sustained workloads?
Miniature form factors typically struggle with heat dissipation during intensive computational tasks. The Surface RTX Spark Dev Box addresses this limitation through deliberate engineering choices. A one hundred watt thermal envelope restricts power consumption to manageable levels while still delivering substantial performance. The aluminum chassis acts as a passive heat spreader, drawing thermal energy away from the silicon components. One thousand precisely calculated air vents facilitate continuous airflow across the internal circuitry. This design prevents hot spots from forming near critical processing units. Sustained workloads, such as long-running training jobs, generate consistent heat output. The ventilation grid ensures that warm air escapes efficiently while cooler air enters the system.
Traditional desktop workstations often rely on large fans and complex liquid cooling loops to manage heat. These solutions require more space and generate higher acoustic noise levels. The compact design of this dev box prioritizes quiet operation and desktop integration. Developers can place the machine directly on their workstations without disrupting their existing setup. The Ethernet port ensures stable network connectivity for version control and package management. HDMI and USB interfaces allow direct monitor and peripheral connections. This self-contained approach reduces cable clutter and simplifies workspace organization. The physical layout reflects a balance between computational density and environmental acoustics.
The thermal management strategy also extends to component longevity and reliability. Continuous high-temperature operation degrades electronic components over time. By maintaining a controlled thermal environment, the system preserves hardware integrity during extended development cycles. Engineers can run continuous integration tests or batch processing tasks without worrying about sudden shutdowns. The aluminum construction also provides structural rigidity, protecting internal circuitry from physical stress. This durability ensures consistent performance throughout the product lifecycle. The design philosophy prioritizes long-term stability over short-term performance spikes.
What are the practical implications for the developer ecosystem?
Microsoft's announcement underscores a strategic push to position Windows as a primary platform for artificial intelligence development. Historically, Linux distributions have dominated the machine learning landscape due to mature toolchains and open-source frameworks. The integration of CUDA support within WSL two bridges this gap significantly. Developers no longer need to dual-boot or maintain separate virtual machines to access GPU acceleration. This convergence simplifies the development lifecycle and reduces operational complexity. The preconfigured software stack aligns with industry standards used in enterprise environments.
The availability timeline indicates that the device will ship later this year through the official Microsoft website in the United States. Pricing details remain undisclosed, which suggests a premium positioning targeting professional researchers and specialized engineering teams. The absence of pre-order options allows Microsoft to manage production scaling carefully. Developers can register interest through the official product page to receive updates. This rollout strategy emphasizes controlled distribution rather than mass market penetration. The focus remains on providing a reliable foundation for agentic AI experimentation.
The hardware release coincides with broader industry movements toward specialized artificial intelligence processors. Manufacturers are increasingly designing silicon optimized for specific computational patterns rather than general-purpose tasks. This shift enables more efficient resource allocation and reduced energy consumption per operation. Software teams will likely adopt these compact machines as standard nodes in their research infrastructure. The ability to run large language models locally will accelerate prototyping phases significantly. Organizations can evaluate new algorithms without waiting for cloud queue approvals. The ecosystem will continue to mature as hardware and software optimizations align.
How will this platform influence future AI research infrastructure?
Specialized dev boxes signal a departure from generalized computing toward purpose-built environments. Research teams benefit from predictable performance metrics and reduced configuration overhead. The compact footprint allows laboratories to deploy multiple units without requiring specialized cooling infrastructure. Engineers can replicate identical hardware configurations across distributed teams, ensuring consistent testing results. This standardization reduces debugging time spent on environment discrepancies. The focus on unified memory also encourages developers to write code that maximizes data locality. These architectural choices will likely influence how future AI workstations are designed. The industry will observe whether this approach becomes the standard for independent researchers and small teams.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)