Advancing the Scientific Framework for AI Agent Reliability
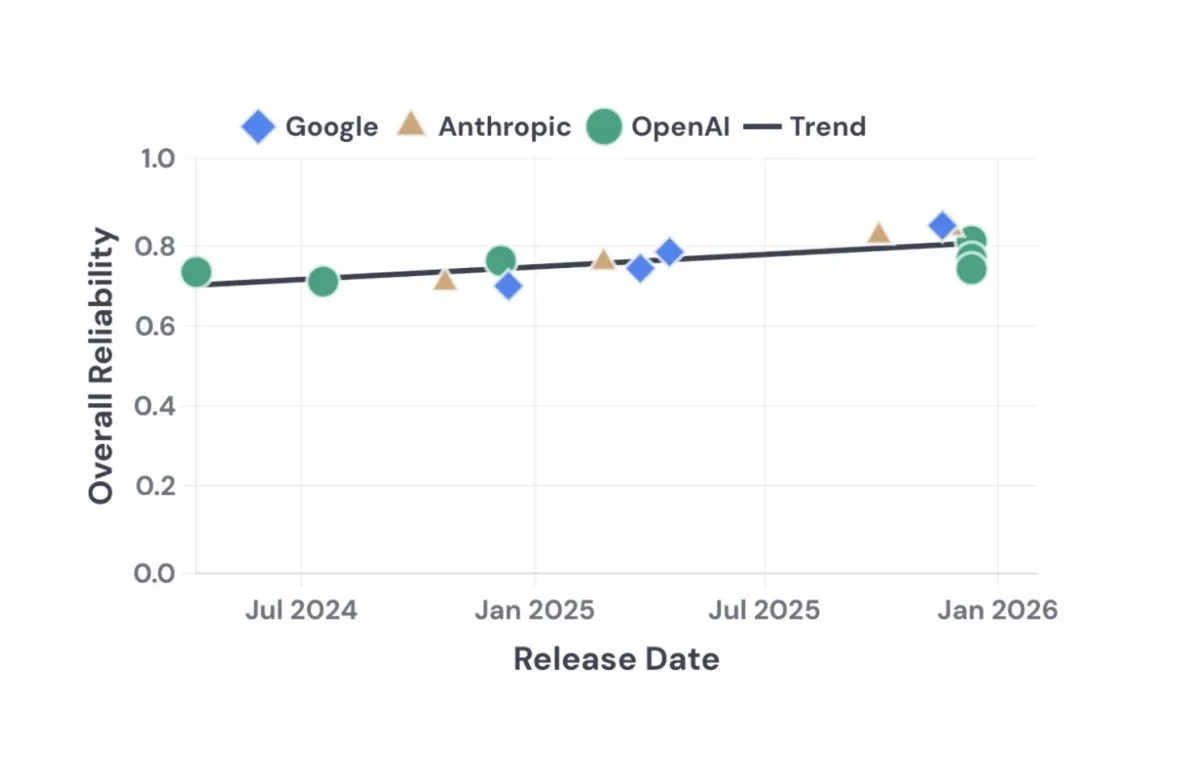
This article examines the foundational requirements for quantifying the capability-reliability gap in autonomous systems. It explores standardized evaluation frameworks, benchmarking methodologies, and the structural shifts necessary to build trustworthy software architectures. The discussion emphasizes conceptual rigor over speculative claims.
The rapid deployment of autonomous software systems has consistently outpaced the development of rigorous evaluation methodologies. Engineers frequently encounter a persistent disconnect between theoretical performance and actual operational stability. This divergence demands a systematic approach to measuring how reliably these tools function under varying conditions. The industry must transition from ad hoc testing to structured scientific inquiry.
What Defines the Capability-Reliability Gap in Autonomous Systems?
The capability-reliability gap represents a fundamental challenge in modern computational architecture. Systems often demonstrate impressive functional proficiency during controlled demonstrations while failing to maintain consistent behavior in dynamic environments. This discrepancy arises because traditional performance metrics prioritize maximum output over operational stability. Engineers must distinguish between peak capability and sustained reliability when designing evaluation protocols.
Historical precedents in software engineering highlight the importance of distinguishing between feature completeness and system robustness. Early computational frameworks frequently prioritized rapid feature deployment at the expense of long-term maintenance. Contemporary autonomous architectures face similar pressures, yet the stakes have escalated significantly. Unpredictable behavior in high-stakes environments requires stricter validation standards. Consequently, developers must adopt more rigorous quality assurance protocols.
Quantifying this gap demands precise definitions of both capability and reliability. Capability measures the breadth and depth of functional outcomes achievable under ideal conditions. Reliability measures the consistency of those outcomes across diverse and unpredictable scenarios. Bridging these definitions requires interdisciplinary collaboration between computational theorists, systems engineers, and domain specialists.
Why Does Standardized Evaluation Matter for Future Deployments?
Standardized evaluation frameworks provide the necessary infrastructure for comparing disparate architectural approaches. Without uniform metrics, progress remains fragmented and difficult to replicate across different research communities. Consistent benchmarking allows developers to identify structural weaknesses before widespread implementation. This methodological consistency accelerates the maturation of the entire field.
The absence of shared evaluation standards often leads to conflicting claims about system performance. Organizations may highlight exceptional results from narrow test cases while overlooking broader operational failures. Transparent reporting mechanisms must become mandatory for credible progress. Independent verification processes help establish baseline trust in emerging technologies. Regulatory bodies increasingly demand these safeguards.
Regulatory and industry bodies increasingly recognize the necessity of unified testing protocols. Collaborative standardization efforts reduce redundancy and prevent the proliferation of incompatible evaluation tools. Shared benchmarks enable cross-organizational learning and foster collective problem-solving. These initiatives lay the groundwork for sustainable technological advancement.
Establishing Baseline Metrics and Control Frameworks
Baseline metrics serve as the foundational reference points for all subsequent reliability assessments. Developers must define clear boundaries for acceptable performance variance across different operational contexts. Control frameworks provide the structural mechanisms for monitoring these boundaries in real time. Continuous oversight ensures that deviations trigger appropriate corrective actions.
Implementing control frameworks requires careful integration of monitoring tools into existing development pipelines. Automated telemetry systems can capture operational anomalies that manual testing might miss. These systems must be designed to distinguish between expected edge cases and genuine reliability failures. Accurate classification prevents unnecessary system shutdowns while maintaining safety standards. Engineering teams must prioritize seamless integration.
The evolution of monitoring capabilities depends heavily on data quality and collection methodologies. High-fidelity telemetry requires standardized data formats and secure transmission protocols. Researchers must prioritize privacy-preserving techniques when gathering operational data. Ethical data handling remains essential for maintaining public trust in autonomous systems.
How Can Researchers Bridge the Divide Between Performance and Trust?
Bridging the performance-trust divide requires a fundamental shift in research priorities. Scholars must move beyond isolated capability demonstrations toward comprehensive reliability studies. Longitudinal testing across extended timeframes reveals patterns that short-term evaluations cannot capture. These extended studies provide valuable insights into degradation patterns and failure modes.
Interdisciplinary collaboration plays a crucial role in developing holistic reliability models. Computer scientists must work alongside behavioral researchers to understand how users interact with autonomous tools. Psychological factors influence perceived reliability just as much as technical metrics. Integrating human factors into evaluation frameworks yields more accurate predictions of real-world performance. Cross-functional teams accelerate this process.
The development of adaptive testing environments allows researchers to simulate complex operational scenarios. These environments can introduce controlled variables that stress-test system boundaries without causing actual harm. Adaptive testing accelerates the identification of reliability bottlenecks. It also enables rapid iteration on proposed architectural solutions.
Integrating Feedback Loops and Continuous Monitoring
Continuous monitoring systems rely on sophisticated feedback loops to maintain operational stability. These loops must process incoming data streams and adjust system parameters accordingly. Effective feedback mechanisms require low-latency processing and precise error correction algorithms. Delays in response can amplify minor anomalies into significant reliability failures. Optimizing these loops requires continuous refinement of both hardware infrastructure and software logic.
The integration of internal links to broader architectural discussions helps contextualize these monitoring strategies. For example, exploring architectural shifts in AI development reveals how hardware advancements influence reliability testing capabilities. Similarly, examining collaborative research initiatives demonstrates how shared knowledge accelerates standardization efforts. These connections highlight the interconnected nature of modern computational progress. Industry leaders recognize these synergies.
Future reliability frameworks must prioritize modularity and scalability. Modular architectures allow engineers to isolate and replace failing components without disrupting entire systems. Scalable monitoring tools can adapt to growing data volumes and increasing system complexity. These design principles ensure long-term sustainability as operational demands evolve.
Conclusion
The transition toward a rigorous science of AI agent reliability requires sustained commitment from researchers, engineers, and industry stakeholders. Standardized evaluation frameworks will gradually replace ad hoc testing methods as the field matures. Quantifying the capability-reliability gap remains a complex but necessary endeavor.
Progress depends on transparent reporting, interdisciplinary collaboration, and adaptive testing methodologies. The industry must prioritize long-term stability over short-term performance gains. Establishing these foundational practices will enable safer and more dependable autonomous systems. The path forward demands methodological discipline and collective effort.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.









Comments (0)