Apple Intelligence Voice Control Hints at iOS 27 Siri Architecture
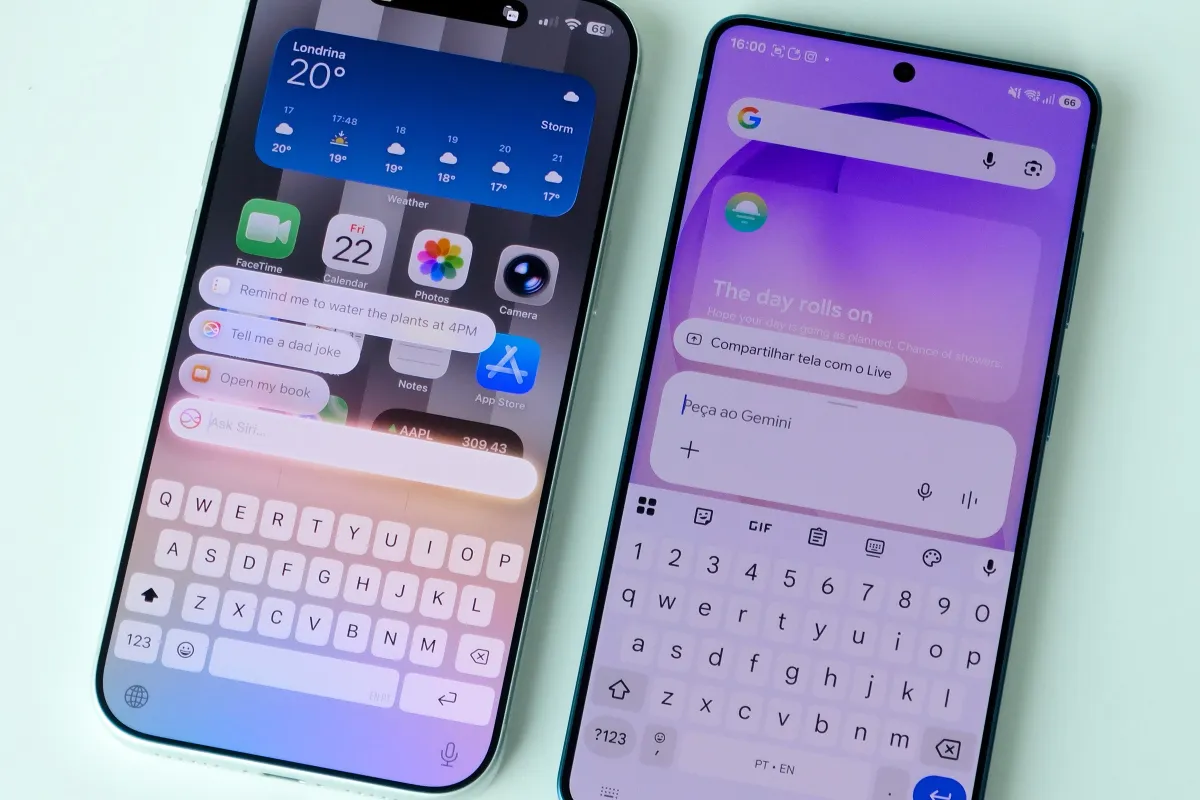
Apple recently unveiled an upgraded Voice Control system powered by Apple Intelligence, enabling natural voice commands and real-time screen context recognition. This accessibility enhancement serves as a preview of iOS 27’s anticipated agentic Siri architecture, signaling a major shift toward conversational device control that mirrors advancements seen in competing mobile platforms.
Apple has consistently treated accessibility as a foundational pillar of its operating system architecture rather than a secondary consideration. Recent developments in voice navigation suggest a deliberate shift toward more intuitive device interaction. A newly announced capability hints at broader systemic changes that could redefine how users communicate with their hardware. This progression demonstrates how specialized interface research frequently informs mainstream software design philosophies across the technology sector.
Apple recently unveiled an upgraded Voice Control system powered by Apple Intelligence, enabling natural voice commands and real-time screen context recognition. This accessibility enhancement serves as a preview of iOS 27’s anticipated agentic Siri architecture, signaling a major shift toward conversational device control that mirrors advancements seen in competing mobile platforms.
What is the new Voice Control feature, and how does it work?
The updated capability represents a significant departure from traditional command-line interfaces built into older operating systems. Instead of requiring users to memorize rigid phrases or exact syntax, the system now processes conversational input through advanced machine learning models. These models analyze the current display layout in real time, identifying visual elements and translating spoken requests into precise touch events. This approach allows individuals to navigate complex menus, open specific applications, or adjust document views using everyday language rather than technical instructions.
The underlying architecture relies on contextual awareness rather than isolated keyword detection. Traditional voice assistants historically struggled with spatial understanding and cross-application execution. By integrating screen-aware processing directly into the accessibility framework, developers can establish a more reliable foundation for conversational interactions. This technical progression aligns with previous announcements regarding system-wide automation capabilities and demonstrates how machine learning models can interpret visual layouts alongside semantic meaning in speech.
Machine learning training for this functionality requires extensive datasets of annotated user interface elements. Engineers must map spatial coordinates to functional descriptions so the system understands that a circular icon represents a play button or a rectangular region functions as a text input field. This mapping process enables the device to execute commands accurately even when applications update their visual designs frequently.
Testing methodologies for these systems involve rigorous validation across diverse application ecosystems. Developers simulate various user scenarios to ensure command recognition remains consistent regardless of screen orientation, font scaling, or dynamic content loading. The goal is to create a robust framework that functions reliably under real-world conditions rather than controlled laboratory environments.
Why does this matter for the future of iOS interaction?
Traditional voice assistants have historically struggled with contextual awareness and cross-application execution. The introduction of screen-aware processing addresses a fundamental limitation that has constrained mobile productivity for years. When devices can interpret visual layouts alongside spoken commands, they bridge the gap between human intent and digital execution. This evolution transforms passive listening tools into active operational interfaces capable of managing complex workflows without manual intervention.
The integration of advanced reasoning models into mobile operating systems requires careful attention to interface design and labeling conventions. Developers must ensure that visual elements contain accurate metadata so machine learning models can interpret them correctly. Users who rely on voice navigation will benefit from more reliable command recognition and smoother application transitions. This technical foundation also establishes new expectations for how digital assistants should operate within modern software environments.
Historical analysis of interface evolution reveals that breakthrough technologies often emerge from highly specialized research initiatives. When engineers solve complex problems for users with specific needs, they frequently discover elegant solutions that benefit the general population. The transition from physical buttons to gesture-based navigation followed a similar developmental path. Modern accessibility frameworks now prioritize semantic labeling and spatial mapping to enable more sophisticated interaction models.
Legacy code structures often complicate the implementation of new recognition algorithms. Older applications may lack proper accessibility attributes, forcing machine learning models to rely on heuristic analysis rather than explicit metadata. This limitation highlights the importance of ongoing developer education regarding interface standards and the necessity of backward compatibility strategies during major operating system updates.
The historical precedent of accessibility-driven innovation
Apple has consistently utilized specialized interface tools as testing grounds for mainstream technological adoption. Features originally designed to assist users with motor impairments or visual disabilities frequently evolve into standard operating system capabilities over time. AssistiveTouch, Live Captions, and external pointer support all followed this exact trajectory. Each began as a niche accessibility solution before becoming integral components of the broader user experience. This pattern suggests that current voice navigation developments may eventually influence how all consumers interact with mobile hardware.
How does Apple Intelligence bridge the gap to agentic Siri?
The underlying technology powering this accessibility update shares architectural similarities with rumored enhancements to the company’s digital assistant platform. Industry analysis indicates that future updates will prioritize contextual understanding and autonomous task execution across multiple applications. By refining machine learning models through real-time visual processing, developers can establish a more reliable foundation for conversational interactions. This technical progression aligns with previous announcements regarding system-wide automation capabilities.
The integration of artificial intelligence into core operating systems requires substantial computational optimization and strict privacy safeguards. Running complex reasoning models locally demands efficient memory management while preserving user data confidentiality. Developers must balance performance requirements with security protocols to ensure widespread adoption across diverse device generations. As processing capabilities continue improving, the boundary between specialized accessibility tools and standard interfaces will gradually disappear.
Agentic workflows represent a significant leap beyond simple command execution. Instead of performing isolated actions, future assistants will need to chain multiple operations together while maintaining contextual awareness throughout extended sequences. This capability requires sophisticated state management and error recovery mechanisms that can handle unexpected application responses or network interruptions gracefully.
Evaluating cross-platform implementations reveals distinct approaches to handling visual recognition and command execution. Some manufacturers prioritize cloud-based processing to maximize model accuracy, while others emphasize on-device computation to minimize latency and protect privacy. Each strategy presents unique trade-offs regarding speed, reliability, and data security. The industry continues refining these methodologies as consumer expectations for seamless interaction grow increasingly sophisticated.
Comparing cross-platform voice navigation systems
Competing mobile ecosystems have already implemented comparable solutions that demonstrate the viability of natural language device control. Recent iterations of third-party voice access tools utilize artificial intelligence to interpret spoken requests and execute precise screen interactions. Users can navigate menus, scroll through documents, and trigger application functions entirely through speech. These systems highlight how conversational interfaces reduce friction during hands-free scenarios. The technical parallels between current accessibility updates and competitor implementations suggest a broader industry shift toward context-aware voice navigation.
What are the practical implications for everyday users and developers?
The integration of screen-aware processing into standard operating systems will require careful attention to interface design and labeling conventions. Developers must ensure that visual elements contain accurate metadata so machine learning models can interpret them correctly. Users who rely on voice navigation will benefit from more reliable command recognition and smoother application transitions. This technical foundation also establishes new expectations for how digital assistants should operate within modern software environments.
Expanding the scope of current AI capabilities
Current artificial intelligence implementations on mobile devices often focus on content generation or information summarization rather than direct system control. While notification processing and text assistance provide incremental improvements, they rarely alter fundamental interaction patterns. True operational capability requires models that understand spatial relationships on a display alongside semantic meaning in speech. Bridging this technical divide will determine whether future updates deliver transformative utility or merely incremental convenience for daily workflows.
Generative models assist with dynamic content adaptation by predicting user intent based on historical usage patterns and current screen context. This predictive capability allows the system to suggest appropriate commands before users articulate them explicitly. Such proactive assistance reduces cognitive load and accelerates task completion times across various application categories.
Evaluating the path forward for system integration
The successful deployment of conversational voice navigation depends heavily on backend processing efficiency and privacy safeguards. Running complex machine learning models locally requires substantial computational resources while maintaining strict data protection standards. Developers must balance performance optimization with user trust to ensure widespread adoption. As operating systems continue integrating advanced reasoning capabilities, the distinction between accessibility tools and standard interfaces will gradually disappear. This convergence represents a logical progression in mobile computing design.
The trajectory of mobile interface development points toward increasingly intuitive communication methods that reduce reliance on traditional touch inputs. Recent announcements regarding voice navigation demonstrate how specialized accessibility research can inform broader system architecture decisions. As machine learning models become more sophisticated, the boundary between human intent and digital execution will continue to narrow. This evolution establishes a clearer framework for future software updates and hardware design philosophies.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)