OpenAI Introduces Dreaming Memory Architecture to ChatGPT
OpenAI has deployed a revised memory framework called dreaming to automatically synthesize chat history while accounting for temporal changes. The system reduces computational overhead by five times, enabling broader access tiers and offering users direct oversight through a dedicated summary dashboard.
Conversational artificial intelligence has long struggled with a fundamental limitation regarding the retention of personal context across separate interactions. Users consistently expected their digital assistants to function as continuous partners rather than isolated sessions that reset upon every closure. OpenAI recently addressed this persistent architectural gap by introducing a background synthesis mechanism known internally as dreaming. The update fundamentally alters how the platform stores, updates, and applies personal data across millions of daily exchanges without requiring manual configuration.
OpenAI has deployed a revised memory framework called dreaming to automatically synthesize chat history while accounting for temporal changes. The system reduces computational overhead by five times, enabling broader access tiers and offering users direct oversight through a dedicated summary dashboard.
How Does the New Memory Architecture Function?
The original iteration of persistent storage depended heavily on explicit user directives to trigger information retention. This manual approach created significant gaps in contextual continuity because many conversational nuances naturally escaped detection without direct commands. Information that required expiration frequently remained embedded in active profiles long after its relevance had passed. The updated framework eliminates this dependency by continuously processing dialogue history through a background synthesis pipeline that identifies relevant patterns autonomously.
Automatic Context Synthesis
Background processing operates by evaluating conversational threads against established relevance thresholds before committing data to long-term storage. The algorithm distinguishes between fleeting remarks and enduring preferences through pattern recognition rather than simple keyword matching. Temporary statements receive lower priority scores during the synthesis phase, ensuring that transient information does not permanently alter behavioral outputs. When a user mentions an upcoming event, the system tags it with a temporal marker that automatically expires once the predicted timeframe concludes.
Preference Application Across Sessions
Personal preferences now integrate seamlessly into subsequent interactions without requiring repetitive instructions or constant reconfiguration. Dietary restrictions, communication styles, and professional requirements are extracted during synthesis and mapped directly to behavioral guidelines. The model applies these parameters automatically when generating replies, which significantly reduces friction in everyday usage scenarios. Users no longer need to restate foundational information before receiving accurate outputs that align with their established habits.
What Changes in Context Retention and Temporal Awareness?
Traditional memory systems treated all stored information as equally permanent, which frequently led to inaccurate assumptions about current status or location. The updated architecture introduces explicit time-based decay functions that evaluate the freshness of each recorded detail against current date calculations. When a user previously mentioned visiting a specific region, the system now cross-references temporal markers with ongoing calendar data to verify relevance. Information that exceeds its expected duration receives automatic flagging for review rather than blind retention.
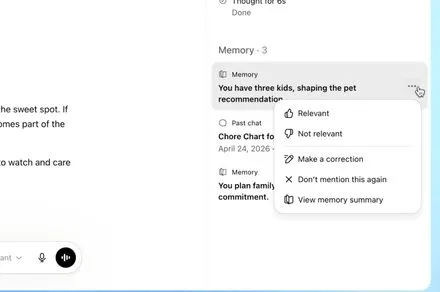
The Memory Summary Dashboard
Direct oversight remains a critical component of modern data management frameworks and user trust protocols. OpenAI has introduced a centralized interface that displays all retained information in a structured format accessible through standard navigation menus. Users can examine each entry, modify existing details, or permanently remove outdated records at any time without technical barriers. This transparency requirement aligns with broader industry standards for explainable artificial intelligence and individual agency over personal data profiles.
Balancing Automation with Verification
Automatic processing introduces efficiency gains but requires robust verification mechanisms to prevent hallucination or misattribution during synthesis phases. The system cross-references multiple conversation turns before committing information to long-term storage, reducing the risk of capturing isolated remarks as permanent facts. Users retain final authority through the summary interface, creating a collaborative model where automation handles routine updates while humans manage exceptions. This hybrid approach ensures that personalization scales effectively without compromising accuracy or user trust.
Why Does This Shift Matter for User Privacy and Control?
Persistent memory systems inherently raise questions regarding data ownership, retention duration, and algorithmic transparency across digital platforms. When artificial intelligence continuously learns from individual interactions, the boundary between helpful personalization and intrusive profiling becomes increasingly narrow. The introduction of temporal decay functions directly addresses one of the most common privacy concerns by ensuring that temporary information does not accumulate indefinitely. Users no longer need to manually purge outdated records because the system automatically evaluates relevance over time.
Computational Efficiency and Accessibility
The deployment strategy relies heavily on recent infrastructure optimizations that dramatically reduced processing requirements across global server networks. OpenAI reports a fivefold decrease in computational overhead, which directly enabled broader tier availability without compromising service quality or response latency. Lower resource consumption allows the company to extend advanced memory capabilities to free and Go subscribers while simultaneously doubling capacity for paid users. This efficiency breakthrough removes previous financial barriers that restricted sophisticated personalization features exclusively to premium accounts.
Transparency and User Agency
Modern consumers expect clear visibility into how their data shapes automated responses before committing to new platform ecosystems. The centralized summary interface provides exactly this level of transparency by listing every retained detail in an accessible format that supports quick navigation. Individuals can verify accuracy, correct errors, or delete records that no longer serve their needs without navigating complex settings menus. This explicit control mechanism fosters trust by acknowledging that personalization should enhance rather than override user autonomy during daily interactions.
How Will the Rollout Strategy Impact Different Subscriber Tiers?
Feature distribution follows a phased approach designed to monitor system stability while gathering diverse usage patterns across global markets. Initial deployment targets ChatGPT Plus and Pro subscribers in the United States, allowing engineers to track performance metrics under real-world conditions before expanding internationally. This staged release strategy is standard practice for complex infrastructure updates that require extensive validation across varying computational loads. Early adopters will provide valuable feedback regarding accuracy thresholds, latency impacts, and interface usability before broader availability begins.
Expansion Timeline and Infrastructure Scaling
Additional regions and subscription tiers will receive access over the coming weeks as monitoring teams verify system reliability under heavy usage conditions. The gradual rollout ensures that any unexpected behavioral patterns or integration conflicts can be addressed before widespread distribution occurs across different demographics. Engineers are closely tracking how various user groups interact with the synthesis pipeline to refine relevance scoring algorithms for maximum accuracy. This methodical approach prioritizes stability over speed, ensuring that memory consistency remains uniform across all subscriber levels during peak demand periods.
Practical Implications for Everyday Usage
The transition from manual configuration to automatic context management fundamentally changes how individuals interact with conversational platforms on a daily basis. Users can expect more coherent dialogue continuity without repeatedly restating foundational information or correcting outdated assumptions that previously disrupted workflow efficiency. Professional workflows benefit significantly when historical preferences and project requirements persist accurately across weeks of intermittent usage without requiring manual re-entry. The reduction in repetitive prompts allows conversations to progress faster while maintaining personalized relevance throughout extended engagement sessions.
The introduction of background synthesis marks a structural evolution in how conversational platforms handle persistent data storage and retrieval. By replacing manual triggers with temporal awareness and computational efficiency, the update addresses longstanding limitations that previously undermined user trust across digital assistants. Continuous monitoring across subscriber tiers will determine whether automated context management consistently delivers accurate personalization without compromising transparency or data security. As infrastructure optimizations continue to lower resource requirements, broader accessibility will likely accelerate adoption across diverse usage scenarios worldwide.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.









Comments (0)