Gemini Context Loss: Paid Users Report Premature Memory Limits
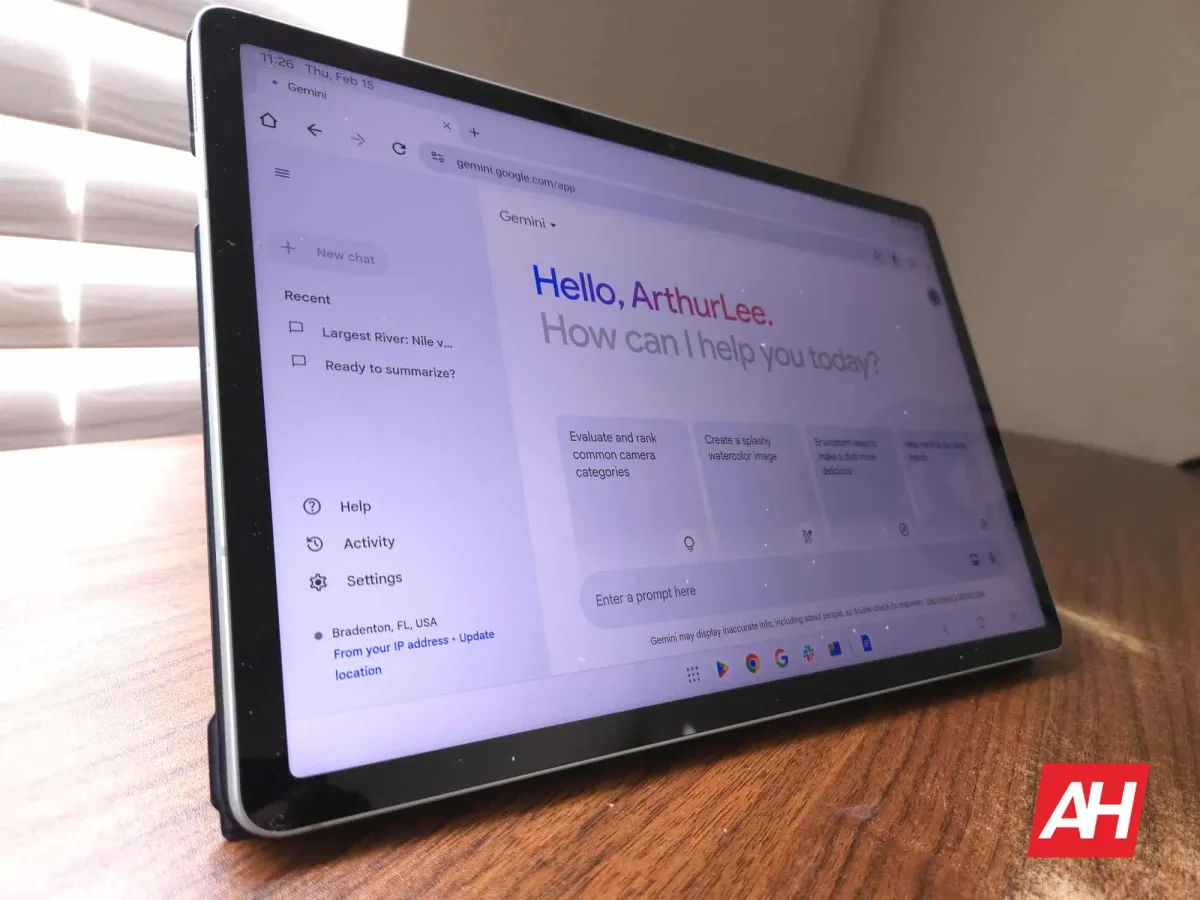
Premium subscribers to Google's Gemini platform are reporting that the service frequently loses conversational context earlier than expected. These complaints highlight ongoing technical challenges surrounding session memory limits and the broader industry struggle to maintain long-form AI interactions without performance degradation or workflow interruptions across multiple devices and platforms globally.
Recent discussions within the artificial intelligence community have highlighted a persistent technical challenge affecting large language model interactions. Users of premium subscription tiers have reported that conversational continuity frequently breaks down before reaching advertised limits. This phenomenon, often described as premature context loss, raises important questions about how modern AI systems manage information retention and session state.
Premium subscribers to Google's Gemini platform are reporting that the service frequently loses conversational context earlier than expected. These complaints highlight ongoing technical challenges surrounding session memory limits and the broader industry struggle to maintain long-form AI interactions without performance degradation or workflow interruptions across multiple devices and platforms globally.
What Causes Premature Context Loss in Modern AI Models?
Large language models process information through a mechanism known as a context window. This window represents the maximum amount of text the system can analyze simultaneously during a single interaction. When a conversation exceeds this boundary, the model must either truncate older messages or discard them entirely to make room for new input. Paid subscribers generally expect these boundaries to align closely with published specifications, yet real-world performance often diverges due to backend optimization strategies.
The architecture behind conversational AI requires significant computational resources to track every token in a session. Developers frequently implement dynamic pruning techniques to maintain response speed and stability. These techniques automatically prioritize recent exchanges while gradually reducing the weight of earlier prompts. While this approach prevents system crashes, it can create the perception that the application is forgetting earlier instructions. The gap between theoretical limits and practical implementation remains a central point of friction for enterprise users.
Tokenization processes further complicate memory retention across extended dialogues. Each word or character fragment consumes a portion of the available allocation. As sessions grow longer, the cumulative token count rapidly approaches the maximum threshold. Systems must then evaluate which historical data holds the highest relevance. This evaluation process is not always transparent to the end user, leading to unexpected shifts in conversational behavior and reduced accuracy.
Memory management algorithms also account for server load and network latency. During peak usage periods, providers may temporarily adjust allocation parameters to maintain overall service stability. These adjustments can inadvertently shorten the effective context window for individual users. The resulting inconsistency frustrates professionals who depend on predictable session lengths. Understanding these backend mechanics helps clarify why published limits rarely match actual experience.
Why Do Session Memory Limits Matter for Professional Workflows?
Professional environments rely heavily on consistent AI assistance for complex tasks. Developers, researchers, and creative professionals often submit lengthy prompts that require the system to reference details provided hours earlier. When conversational memory degrades prematurely, users must repeatedly restate foundational information. This repetition disrupts workflow continuity and increases the time required to complete sophisticated projects. The reliability of long-term memory directly impacts the practical utility of premium AI subscriptions.
Enterprise teams evaluate artificial intelligence tools based on their ability to maintain state across extended interactions. A system that consistently drops earlier context forces users to fragment their work into smaller, isolated sessions. This fragmentation complicates version control, reduces analytical depth, and increases the likelihood of contradictory outputs. Organizations investing in premium tiers anticipate seamless continuity, making premature context loss a significant operational concern.
The financial implications of inconsistent memory management extend beyond mere inconvenience. Companies purchasing enterprise licenses expect dedicated infrastructure that supports uninterrupted operation. When sessions terminate or reset unexpectedly, teams must restart complex analytical pipelines. These interruptions accumulate into substantial productivity losses over time. The discrepancy between marketing promises and actual performance becomes a critical metric for procurement decisions.
Regulatory compliance also influences how organizations handle conversational data. Certain industries require strict retention policies for audit trails and decision logs. If an AI platform discards earlier exchanges without warning, it may inadvertently violate documentation standards. Users must therefore implement external logging mechanisms to preserve critical information. This workaround adds administrative overhead and reduces the inherent value of the subscription for enterprise clients.
Training data quality also influences how well models retain historical context. Systems trained on diverse, high-quality dialogues demonstrate superior recall capabilities. Providers continuously refine their datasets to improve conversational coherence. This ongoing refinement process directly impacts how accurately the AI references earlier instructions. Users benefit from these incremental improvements over time.
How Does Google Approach Conversation Management in Gemini?
Google has historically emphasized scalability and integration within its broader technology ecosystem. The company frequently updates its AI infrastructure to handle larger data volumes and more complex queries. Recent developments in the sector, such as the testing of a floating AI search interface for Chrome desktop, demonstrate a continued push toward seamless information retrieval. These parallel initiatives reflect a broader strategy to reduce friction between user input and system response.
Managing conversation history requires balancing memory allocation with computational throughput. Google's engineering teams typically deploy rolling window mechanisms that retain the most recent exchanges while compressing older data. This compression preserves essential instructions while reducing the overall token load. Users who notice earlier-than-expected truncation are likely experiencing these background optimization processes in action. The company continues to refine these mechanisms to align more closely with published subscription limits.
The integration of AI capabilities across multiple platforms also influences memory handling. As seen with preparations for Gboard voice typing upgrades, the company is systematically optimizing how audio and text data interact with backend models. These cross-platform optimizations aim to standardize performance metrics across different user interfaces. When one component improves, the entire ecosystem benefits from more consistent behavior.
Subscription tiers often dictate the specific memory parameters assigned to each user. Higher plans typically grant access to extended context windows and priority processing queues. However, these benefits are not always guaranteed during system maintenance or global updates. Temporary infrastructure adjustments can temporarily override standard allocation rules. Users should monitor official documentation for any changes to session management policies and update their workflows accordingly.
What Are the Broader Industry Implications for AI Memory?
The challenge of maintaining long-form context extends far beyond a single platform. Competing providers like OpenAI and Anthropic face identical architectural constraints when scaling their models to handle enterprise workloads. Recent advancements in input processing illustrate how the industry is gradually shifting toward more efficient data handling. These improvements aim to reduce the cognitive load placed on conversation management systems.
Researchers are actively exploring external memory architectures that store historical data outside the active processing window. By offloading older exchanges to dedicated storage layers, developers can retrieve specific details on demand without flooding the primary context. This approach promises more predictable behavior for premium users who require consistent reference points. The transition from purely reactive models to hybrid memory systems represents a fundamental shift in how artificial intelligence manages information over time.
Standardization efforts within the technology sector are beginning to address these inconsistencies. Industry consortia are developing shared benchmarks for context retention and session durability. These benchmarks will help users compare platform capabilities with greater accuracy. Transparent reporting standards will also reduce the gap between advertised features and actual performance.
The economic model of artificial intelligence services depends heavily on predictable resource allocation. Providers must balance the cost of storing massive conversation histories against the demand for extended memory. As computational expenses rise, companies will likely introduce more granular pricing tiers for memory-intensive workflows. This evolution will encourage users to adopt more efficient prompting strategies.
Data privacy regulations further complicate memory management strategies. Storing extended conversation histories requires robust encryption and strict access controls. Providers must ensure that historical data remains secure while remaining accessible for retrieval. These security requirements add another layer of complexity to memory architecture design. Compliance teams must regularly audit how long information persists before automatic deletion occurs.
Looking Ahead at Conversational Continuity
The ongoing discussions regarding session limits highlight a critical phase in AI development. As models grow more capable, the demand for reliable long-term memory increases proportionally. Users expect premium subscriptions to deliver uninterrupted assistance across complex, multi-stage projects. Providers must address these expectations through transparent documentation and consistent performance benchmarks to maintain trust.
Future iterations of conversational AI will likely prioritize memory preservation as a core feature rather than an afterthought. Improved compression algorithms, external storage integration, and clearer user controls will help bridge the gap between theoretical limits and daily usage. Until those advancements become standard, professionals will continue to adapt their workflows to accommodate current technical constraints. The industry remains focused on delivering more stable and predictable AI experiences for all users.
User feedback mechanisms will play a crucial role in shaping future updates. Platforms that actively monitor context loss reports can prioritize architectural improvements accordingly. This collaborative approach ensures that development efforts align with actual user needs. The industry will continue to evolve as developers and consumers refine their expectations together.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.









Comments (0)