Qumulo and Cisco Redefine GPU Liquidity Architecture
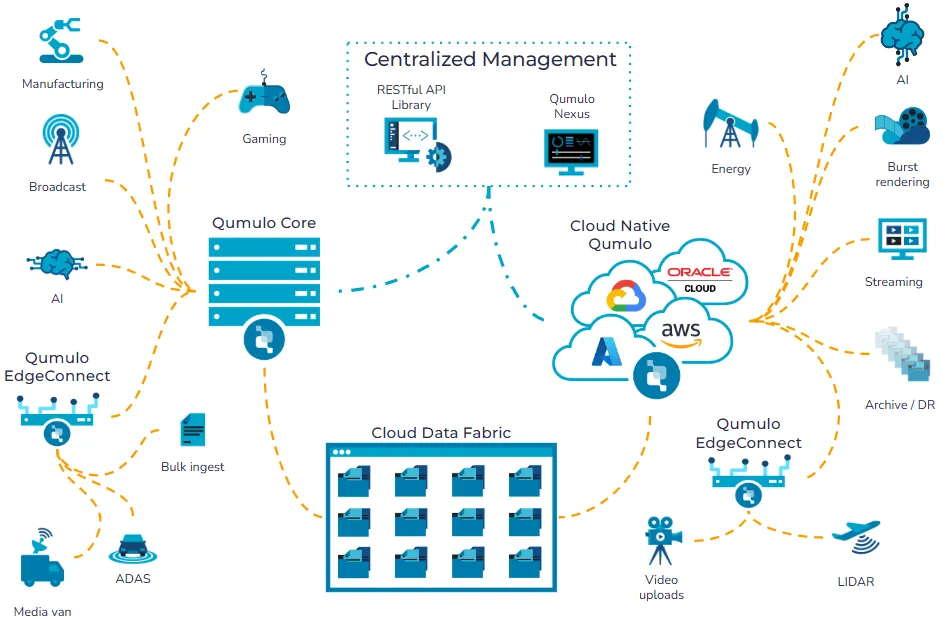
Qumulo and Cisco updated the Cloud AI Accelerator to eliminate data movement bottlenecks in enterprise artificial intelligence infrastructure. The platform decouples storage from compute, enabling real-time dataset access across hybrid environments. By removing staging delays and reducing idle GPU time, the architecture improves utilization rates and streamlines multi-cloud operations for modern data centers.
The rapid expansion of artificial intelligence workloads has exposed a persistent architectural flaw in enterprise computing. Organizations invest heavily in accelerated hardware, yet the financial returns frequently fall short of projections. The disconnect stems from how data moves through modern infrastructure. When storage systems and processing units operate as isolated silos, computational resources spend more time waiting than calculating. This structural inefficiency has prompted vendors to reconsider foundational design principles.
What is the fundamental bottleneck in modern enterprise AI infrastructure?
Historical approaches to artificial intelligence deployment prioritized compute density above all other metrics. Engineering teams focused on stacking processors and maximizing theoretical throughput. This strategy produced powerful training clusters, but it overlooked the physical limitations of data transport. As model complexity increased, the volume of required datasets grew exponentially. Storage systems struggled to keep pace with processing demands.
Industry analysis highlights the severity of this mismatch. Recent optimization reports indicate that average enterprise GPU utilization hovers near five percent. The remaining ninety-five percent of accelerated compute capacity sits idle. These machines remain dormant because data must be staged, replicated, and positioned before workloads can initiate. This phenomenon creates a severe economic drag on capital investments and forces IT leaders to question traditional deployment models.
The underlying driver of this inefficiency is a concept known as data gravity. Large datasets naturally attract compute resources, forcing organizations to co-locate storage directly alongside processing clusters. While this proximity reduces latency during active training phases, it creates fragmentation during idle periods. Enterprises end up maintaining multiple storage silos to keep data close to different compute environments. This replication strategy multiplies infrastructure costs and complicates synchronization.
How does the Cloud AI Accelerator restructure data placement?
The proposed solution shifts the architectural paradigm by separating data location from compute location. Instead of forcing datasets to travel to processing units, the new architecture enables processors to access information in place. This reversal relies on a distributed data fabric that maintains consistent, real-time access across geographically dispersed environments. The system operates independently of physical boundaries, allowing workloads to function seamlessly across regions and cloud boundaries.
The technical implementation integrates multiple storage components into a unified pathway. Data moves at the block level from source sites, including on-premises clusters and cloud regions, into a central CPU DRAM cache. From there, the information routes directly to GPU resources without intermediate staging steps. This continuous flow preserves a single source of truth across hybrid deployments. Organizations no longer need to maintain duplicate copies of datasets to satisfy proximity requirements.
Predictive caching mechanisms further refine this data path. Machine learning algorithms analyze access patterns to anticipate read and write demands. By preloading frequently requested information into high-speed memory, the system reduces data load times significantly. This optimization ensures that processing units receive the exact information they require the moment a workload begins. The result is a streamlined pipeline that minimizes waiting periods and maximizes computational efficiency across diverse workloads.
Why does GPU liquidity matter for hybrid cloud deployments?
Traditional infrastructure models tie workloads to specific physical locations. Engineers must pre-position data before scheduling a job, which limits flexibility and increases operational friction. The concept of GPU liquidity removes these constraints by treating compute capacity as a dynamic resource pool. Workloads can now schedule based on available processing power rather than data locality. This flexibility allows organizations to route jobs to the most efficient hardware regardless of geographic location.
Multi-cloud environments benefit substantially from this approach. Enterprises frequently distribute artificial intelligence workloads across public cloud providers to balance costs and performance. Legacy architectures require complex data synchronization protocols to keep datasets consistent across different hyperscalers. The updated accelerator eliminates the need for bulk replication. Organizations can connect existing datasets directly to managed AI platforms without copying information into those environments, thereby preserving data integrity.
This architectural shift also addresses the economic reality of accelerated hardware. High-performance processors represent a significant capital expenditure. When machines spend extended periods idle, the return on investment deteriorates rapidly. By enabling immediate access to distributed datasets, organizations can start workloads the instant compute becomes available. This continuous utilization pattern transforms fixed hardware costs into highly productive operational assets.
What operational shifts occur when storage decouples from compute?
The transition from coupled to decoupled infrastructure requires changes in daily operations. Storage administrators previously managed separate environments for each processing cluster. This fragmented approach generated significant overhead and increased the risk of configuration errors. A unified data fabric simplifies management by presenting a single logical dataset to all compute resources. Teams can monitor performance, enforce security policies, and track usage from a centralized interface.
Infrastructure sprawl diminishes as organizations consolidate their storage footprint. Instead of provisioning dedicated flash arrays for every new GPU cluster, engineers can rely on a scalable fabric that grows alongside processing demands. This consolidation reduces both capital expenditure and ongoing maintenance requirements. Data governance becomes more straightforward when information resides in a consistent location rather than scattering across multiple silos, which simplifies compliance auditing.
The operational benefits extend to disaster recovery and business continuity. Traditional replication strategies create lag and increase the likelihood of data inconsistency during failover events. A distributed fabric maintains coherence across on-premises, edge, and cloud locations. When a processing node fails, workloads can redirect to alternative hardware without interrupting data access. This resilience ensures that artificial intelligence pipelines remain stable during hardware fluctuations or network disruptions.
How does the Cisco partnership enable enterprise-scale adoption?
Enterprise adoption requires validated pathways that integrate seamlessly with existing hardware ecosystems. The collaboration between Qumulo and Cisco provides a structured approach to hybrid artificial intelligence infrastructure. Cisco UCS servers supply the on-premises compute footprint, while Cisco networking and security frameworks wrap the data fabric. This integration creates a cohesive environment where storage and processing operate as a unified system.
High-throughput networking serves as the load-bearing element of this architecture. Data access in place depends entirely on consistent transport between distributed sites. Network latency directly impacts processing efficiency, making reliable connectivity essential. The partnership ensures that data moves rapidly and securely between on-premises clusters and public cloud regions. Organizations gain a validated deployment model that addresses both performance and compliance requirements, reducing implementation friction.
The joint offering targets enterprises that require data to remain on-premises while compute scales across hyperscalers. This hybrid approach satisfies regulatory constraints that mandate local data residency. At the same time, it allows organizations to tap into external processing capacity during peak demand periods. The flexibility to adapt infrastructure in minutes addresses the dynamic nature of modern artificial intelligence workloads. This adaptability proves critical as model training cycles accelerate and inference demands fluctuate.
Conclusion
The evolution of artificial intelligence infrastructure continues to prioritize data accessibility over raw processing power. Early deployment strategies focused exclusively on hardware density, overlooking the physical limitations of data transport. Modern architectures recognize that computational efficiency depends on how quickly information reaches processing units. Decoupling storage from compute represents a durable solution to persistent utilization challenges. Organizations that adopt this approach can reduce infrastructure sprawl, eliminate staging delays, and improve the return on accelerated hardware investments across global data centers.
The industry is gradually shifting toward data-centric designs that treat information as a universally accessible resource rather than a mobile commodity. This structural realignment will likely define the next phase of enterprise artificial intelligence deployment. Vendors that successfully bridge the gap between distributed storage and dynamic compute will capture significant market share. The focus will remain on maximizing utilization through architectural innovation rather than hardware proliferation.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)