Human-Like AI Voice Interfaces: Technology and Ethics
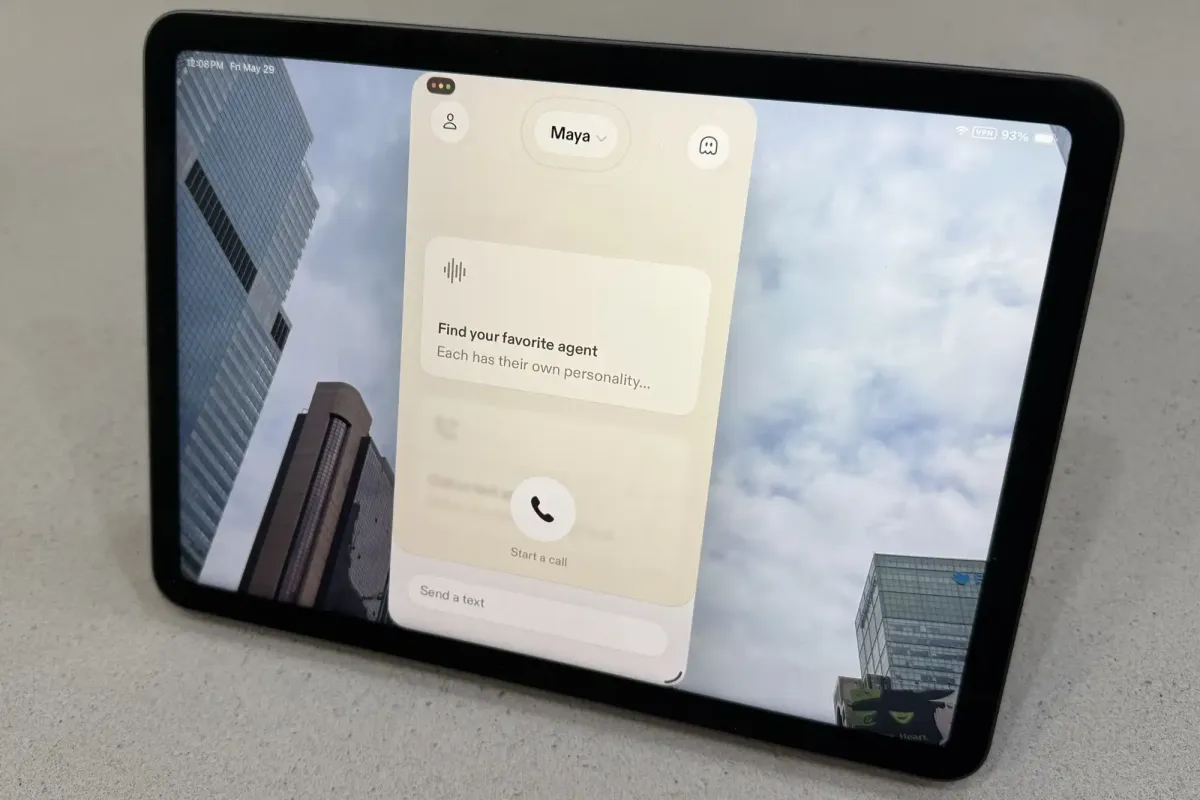
Sesame has released a free iOS application utilizing Google’s Gemma 4 and custom speech models to deliver real-time, human-like voice interactions. The system performs background web searches during dialogue, enabling natural conversational flow. While offering significant utility, the technology raises critical questions regarding transparency and user manipulation.
The rapid evolution of artificial intelligence has shifted focus from mere text generation to immersive, real-time interaction. Recent developments in voice synthesis and large language model integration have produced systems capable of maintaining fluid, dynamic conversations that closely mimic human dialogue. This technological leap introduces both significant utility and complex ethical considerations for developers and users alike. As voice interfaces become more sophisticated, the industry must navigate the delicate balance between functional efficiency and the psychological impact of synthetic companionship.
Sesame has released a free iOS application utilizing Google’s Gemma 4 and custom speech models to deliver real-time, human-like voice interactions. The system performs background web searches during dialogue, enabling natural conversational flow. While offering significant utility, the technology raises critical questions regarding transparency and user manipulation.
What is Sesame and how does its voice architecture function?
The application in question represents a distinct departure from traditional conversational interfaces. Rather than relying on static text-to-speech pipelines, the system integrates Google’s Gemma 4 large language model with a specialized conversational speech architecture known as CSM-1B. This combination allows the software to generate responses that are not only semantically accurate but also vocally nuanced. The interface offers multiple distinct voice agents, each calibrated to provide different conversational tones. Users can engage in extended dialogues without experiencing the typical latency that plagues earlier voice assistants. The architecture continuously processes input and generates output simultaneously. This creates a feedback loop that closely resembles natural human speech patterns. This technical foundation enables the system to maintain coherence across complex queries. It adapts to shifting contextual cues in real time.
The evolution of digital assistants has progressed from simple command-based interfaces to complex conversational platforms. Early systems relied heavily on rigid scripting and keyword matching, which limited their usefulness in open-ended discussions. The shift toward large language models has enabled machines to understand context and generate coherent responses. This technological progression has required engineers to rethink how audio output is synchronized with semantic processing. The current generation of voice applications represents a significant milestone in this ongoing development.
Why does real-time conversational latency matter in AI design?
Traditional voice assistants often suffer from a noticeable delay between user input and system response. This pause disrupts the illusion of dialogue and forces users into a rigid format. The newer architecture addresses this by conducting multiple web searches in the background while the system continues to speak. This parallel processing capability allows the model to gather additional context without halting the conversation. Users can observe visual indicators of these background operations. These indicators provide transparency regarding how the system formulates its answers. The ability to pivot mid-sentence based on newly acquired information fundamentally changes how users interact with digital tools. Instead of receiving a monolithic response, users experience a dynamic exchange. This exchange adapts to emerging data. This reduction in latency transforms the interface into an active partner.
Measuring conversational latency involves tracking the time elapsed between user utterance completion and system audio initiation. Industry standards typically aim for delays under two hundred milliseconds to maintain the illusion of natural dialogue. Achieving this target requires substantial computational resources and optimized neural network architectures. Background search operations must be executed efficiently to avoid interrupting the primary audio stream. Engineers continuously refine these processes to ensure that real-time data retrieval does not compromise conversational fluidity.
The mechanics of background processing
The underlying mechanism relies on sophisticated stream processing techniques that separate semantic generation from audio synthesis. Earlier voice modes for platforms like ChatGPT and Gemini typically generated complete responses before initiating audio playback. This approach resulted in lengthy monologues that felt like academic lectures. The current system breaks this pattern by interleaving thought and speech. As the model processes a query, it simultaneously constructs a response and generates corresponding audio. This dual-track processing allows for natural vocal tics, such as strategic pauses and filler sounds. These vocal cues signal active listening rather than mechanical recitation. The integration of these elements creates a cohesive auditory experience that reduces cognitive load. Developers have prioritized frictionless interaction over raw computational speed. They recognize that usability depends on perceived naturalness rather than technical efficiency alone.
Acoustic modeling plays a crucial role in determining how synthetic speech is perceived by human listeners. Researchers utilize extensive datasets of natural human speech to train models that capture subtle variations in pitch, tempo, and emphasis. These models are designed to avoid the monotone delivery that characterized earlier text-to-speech systems. The integration of prosody control allows the system to adjust its tone based on contextual cues. This attention to acoustic detail significantly enhances the overall listening experience.
How does human-like vocalization influence user trust?
The deliberate inclusion of human speech patterns serves a specific psychological function. When a system utilizes measured pauses, tonal variations, and conversational fillers, it triggers subconscious associations with human communication. This design choice lowers barriers for complex queries and encourages longer dialogues. However, the effectiveness of this approach introduces a significant ethical dilemma. When synthetic voices replicate the subtle cues of human empathy and attention, users may inadvertently project genuine understanding onto a non-sentient program. The distinction between intuitive design and psychological manipulation becomes increasingly blurred. Systems that successfully mimic emotional resonance can foster deep engagement. They also risk creating false expectations about the nature of the interaction. Transparency regarding the artificial origin of these responses remains a critical safeguard against unintended emotional dependency.
Psychological studies on human-computer interaction reveal that users naturally respond to vocal cues in ways that mirror social behavior. When a system employs conversational fillers or strategic pauses, listeners often perceive the interface as more attentive and responsive. This phenomenon stems from deeply ingrained social conditioning that associates vocal rhythm with cognitive processing. Designers leverage these psychological responses to create more engaging digital experiences. However, the deliberate exploitation of these responses warrants careful ethical consideration.
What ethical boundaries define the future of synthetic dialogue?
The rapid advancement of conversational AI forces a reevaluation of existing safety frameworks. Developers must establish clear guidelines that prevent systems from overstating their capabilities or implying consciousness. The primary objective should be frictionless utility rather than deceptive realism. When voice agents successfully simulate personality traits, they can become highly effective tools for training, coaching, and customer service applications. Yet, the same technology could be repurposed to exploit psychological vulnerabilities if left unregulated. The industry operates in a period of rapid experimentation where technical capabilities outpace ethical consensus. Establishing standardized protocols for synthetic voice disclosure is essential as these systems become pervasive. Users deserve to know when they are interacting with a sophisticated algorithm rather than a human counterpart.
Regulatory bodies worldwide are beginning to examine the implications of synthetic voice technology. Policymakers are drafting guidelines that require clear disclosure when users interact with artificial agents. These frameworks aim to prevent deceptive practices while encouraging responsible innovation. Companies must navigate a complex landscape of regional privacy laws and consumer protection standards. Proactive compliance and transparent design practices will likely become industry standards as public awareness grows.
Where does this technology lead next?
The trajectory of voice AI points toward integrated and context-aware systems. Future iterations will likely expand beyond mobile applications to include wearable technology and ambient computing environments. The roadmap for these platforms includes multimodal capabilities that combine auditory input with visual recognition. Similar to Microsoft’s Project Solara, which explores AI integration within physical hardware, voice agents are moving toward ambient deployment. As these systems evolve, they will require more robust privacy controls and more precise intent recognition. The current generation of voice agents serves as a proof of concept for fully autonomous digital assistants capable of executing complex, multi-step tasks. The challenge for engineers and policymakers will be ensuring that these tools remain transparent, secure, and aligned with human values. The conversation around artificial intelligence must continue to prioritize user autonomy alongside technological innovation.
Hardware manufacturers are actively exploring ways to embed voice AI directly into everyday devices. Smart speakers, automotive infotainment systems, and wearable computers are all potential platforms for next-generation voice interfaces. This hardware integration will enable more seamless interactions across different environments. Users will expect consistent performance regardless of the device they are using. Cross-platform compatibility and standardized voice protocols will be essential for widespread adoption.
Conclusion
The emergence of highly realistic voice interfaces marks a definitive shift in how humans interact with digital infrastructure. The technical achievements behind these systems demonstrate remarkable progress in natural language processing and audio synthesis. However, the societal implications require careful navigation. Developers must resist the temptation to prioritize immersion over honesty, ensuring that synthetic voices remain clearly identifiable as artificial constructs. Users should approach these tools with a balanced perspective, recognizing their utility while maintaining awareness of their limitations. The future of conversational AI depends on establishing clear boundaries between functional assistance and simulated companionship. As the technology matures, the industry must remain committed to ethical transparency and user empowerment.
Public education regarding artificial intelligence capabilities remains a critical component of responsible technology deployment. Users must understand the fundamental differences between algorithmic processing and genuine human cognition. Media literacy programs can help individuals recognize the limitations of synthetic voices and avoid overreliance on automated systems. Educational initiatives should emphasize the importance of maintaining critical thinking skills when interacting with digital assistants. This proactive approach ensures that technology serves as a tool rather than a substitute for human judgment.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)