Sesame AI Voice App: Conversational Tech and Ethical Boundaries
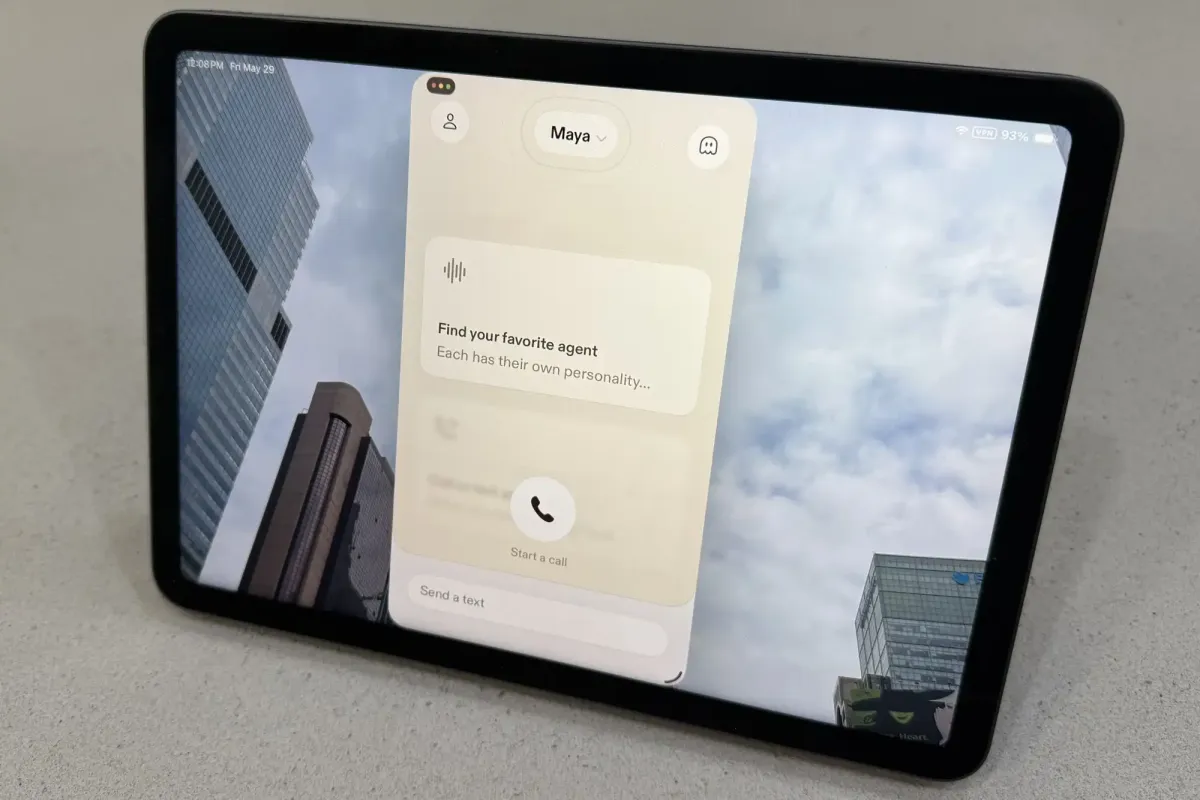
Sesame’s new iOS application delivers the most human-like conversational experience currently available by leveraging Google’s Gemma 4 large language model alongside a custom speech synthesis framework. The system conducts real-time web searches during dialogue, enabling fluid topic shifts and reducing the rigid, lecture-style delivery typical of competing voice assistants. This advanced capability raises significant ethical questions regarding transparency, user manipulation, and the future standards for artificial intelligence safety.
The rapid evolution of artificial intelligence has consistently pushed the boundaries of human-computer interaction, yet voice technology has historically struggled to bridge the gap between functional utility and genuine conversational fluidity. Recent developments in generative speech models are finally addressing this deficit, introducing systems capable of dynamic response generation that closely mirror natural human dialogue. This technological shift demands careful examination, as the line between sophisticated assistance and psychological manipulation grows increasingly narrow.
Sesame’s new iOS application delivers the most human-like conversational experience currently available by leveraging Google’s Gemma 4 large language model alongside a custom speech synthesis framework. The system conducts real-time web searches during dialogue, enabling fluid topic shifts and reducing the rigid, lecture-style delivery typical of competing voice assistants. This advanced capability raises significant ethical questions regarding transparency, user manipulation, and the future standards for artificial intelligence safety.
What is Sesame and how does its voice architecture function?
The application represents a distinct departure from traditional voice assistants that rely on pre-recorded phrases or static text-to-speech engines. Developers have engineered a system that integrates Google’s Gemma 4 large language model with a specialized conversational speech model known as CSM-1B. This combination allows the software to process complex queries while simultaneously generating speech output in real time. Users interact with multiple distinct voice agents, each calibrated to provide specific tonal qualities and conversational pacing.
The architecture prioritizes latency reduction, ensuring that responses do not suffer from the awkward silences that previously characterized automated dialogue systems. By processing information continuously rather than in discrete blocks, the application maintains a steady flow of communication that feels remarkably organic. The underlying technology actively manages computational resources to balance linguistic comprehension with vocal synthesis, creating an environment where users can engage in extended discussions without experiencing the cognitive fatigue associated with older voice interfaces.
Early testing indicated that the system successfully avoids the overly inquisitive behavior that sometimes plagued previous iterations of conversational AI. The voice agents demonstrate a refined ability to ask clarifying questions without crossing into uncomfortable territory. This measured approach to dialogue management suggests that developers have prioritized user comfort alongside technical performance. The result is a functional tool that respects conversational boundaries while still delivering comprehensive information retrieval capabilities.
The integration of multiple voice profiles allows users to select personas that align with their specific tasks or preferences. This customization extends beyond simple tonal adjustments to encompass pacing speed and response length. The system dynamically adapts its communication style based on contextual cues, ensuring that interactions remain appropriate for the subject matter. Such flexibility demonstrates a sophisticated understanding of how different users process information and prefer to receive guidance.
Testing revealed that the application handles complex multi-part queries with remarkable consistency. When users request detailed comparisons or historical overviews, the system maintains structural coherence throughout the response. The underlying language model successfully navigates nuanced topics without devolving into repetitive phrasing or logical contradictions. This reliability establishes a foundation for trust, which remains essential for any tool intended for regular professional or personal use.
Why does real-time conversational AI matter for user experience?
Historical voice assistants operated on a rigid command-and-response paradigm that required users to adapt their speech patterns to machine limitations. Modern generative models have inverted this dynamic by prioritizing natural language processing that accommodates human speech patterns, including interruptions, pauses, and contextual pivots. This shift fundamentally alters how individuals interact with digital tools, transforming them from transactional utilities into collaborative partners.
The ability to conduct background web searches while actively speaking represents a critical advancement in this domain. Users no longer need to wait for a complete response before receiving supplementary information. The system continuously evaluates incoming data, allowing it to adjust its trajectory mid-conversation. This capability mirrors how human experts process information during complex discussions, where new facts immediately influence subsequent statements.
The resulting interaction reduces cognitive load and creates a more intuitive digital environment. When information retrieval and vocal synthesis occur simultaneously, the friction between thought and expression diminishes significantly. This seamless integration allows users to maintain focus on the subject matter rather than the mechanics of the interface. The technology effectively removes the traditional barriers that previously hindered productive dialogue with automated systems.
The elimination of rigid turn-taking structures fundamentally changes how individuals approach problem-solving with digital assistants. Users can now interrupt, clarify, or redirect conversations without triggering system errors or requiring explicit reset commands. This fluidity mirrors natural human dialogue, where participants continuously adjust their statements based on real-time feedback. The resulting experience feels less like operating machinery and more like collaborating with a knowledgeable colleague.
Background search capabilities further enhance this collaborative dynamic by providing immediate access to external knowledge bases. The system does not rely solely on its training data, which may contain outdated or incomplete information. Instead, it actively verifies claims and supplements responses with current web data. This hybrid approach combines the speed of pre-trained models with the accuracy of live research, delivering results that are both timely and reliable.
The mechanics of background processing and speech synthesis
The technical foundation of this experience relies on parallel processing pipelines that handle linguistic analysis, information retrieval, and vocal generation simultaneously. When a user poses a question, the system initiates multiple concurrent search operations while simultaneously formulating an initial response. Visual indicators within the interface provide transparency regarding these background operations, allowing users to observe the research process in real time.
This architectural choice eliminates the traditional waiting period that previously disrupted conversational momentum. The speech synthesis component incorporates carefully calibrated vocal tics, including strategic pauses and filler sounds, to prevent the robotic cadence that often signals artificial origin. These micro-adjustments in pacing and tone significantly enhance perceived authenticity without compromising the underlying accuracy of the information provided. The system continuously monitors user input to detect shifts in intent, enabling seamless topic transitions that feel natural rather than forced.
The synchronization of these parallel processes requires significant computational optimization to prevent audio glitches or timing discrepancies. Engineers have implemented adaptive buffering techniques that adjust processing speed based on network conditions and device capabilities. This ensures that vocal output remains smooth even during periods of high data retrieval activity. The technical achievement lies not only in the accuracy of the information but also in the seamless delivery mechanism.
How does human-like vocalization impact ethical boundaries?
The pursuit of conversational realism introduces complex philosophical and practical considerations that extend far beyond technical performance metrics. When artificial systems successfully replicate human vocal patterns and conversational pacing, they trigger psychological responses that were previously reserved for genuine human interaction. Users may unconsciously attribute empathy, intentionality, or subjective experience to a system that operates purely through algorithmic processing. This phenomenon creates a delicate balance between designing frictionless interfaces and maintaining clear boundaries regarding artificial nature.
Transparency remains the primary safeguard against unintended psychological manipulation. Developers must ensure that the pursuit of natural dialogue does not obscure the fundamental reality that these systems lack consciousness or personal experience. The ethical framework surrounding this technology requires continuous evaluation as capabilities advance. Organizations implementing such systems bear a responsibility to design interactions that prioritize user awareness over mere engagement optimization.
The industry must also consider how these tools integrate into broader digital ecosystems. As artificial agents become more sophisticated, their role in professional and personal environments will expand significantly. The development of standards for agent behavior will likely draw inspiration from adjacent fields, such as the conceptual frameworks explored in Microsoft’s Project Solara pitch. Establishing clear operational guidelines will help prevent the normalization of deceptive interfaces.
Regulatory bodies are beginning to examine how synthetic media and voice cloning intersect with consumer protection laws. The ability to generate convincing human speech raises questions about consent, attribution, and potential fraud. Developers must anticipate these regulatory shifts and incorporate compliance measures directly into their architecture. Proactive governance will prevent the industry from facing sudden restrictions that could hinder legitimate innovation.
User education plays an equally important role in navigating these ethical complexities. Clear onboarding processes should explain how the system operates, what data it accesses, and how responses are generated. Empowering users with technical knowledge reduces the likelihood of psychological manipulation and fosters healthier human-technology relationships. Transparency should be treated as a core feature rather than an afterthought.
The tension between intuitive design and user manipulation
The design philosophy driving modern voice assistants often emphasizes minimizing user effort and maximizing conversational flow. While this approach successfully reduces friction, it simultaneously increases the risk of psychological dependency or misplaced trust. When an artificial agent consistently responds with appropriate pacing, contextual awareness, and vocal warmth, users may lower their critical defenses. This dynamic becomes particularly relevant when discussing sensitive topics or complex decision-making processes.
The system can simulate active listening and thoughtful consideration, creating an illusion of shared understanding that does not actually exist. Maintaining ethical integrity requires implementing deliberate design choices that preserve user autonomy. Clear disclosure of artificial origin, combined with interfaces that highlight computational processes, helps users maintain appropriate perspective. The technology should enhance human decision-making rather than subtly steering it through engineered familiarity.
Design teams must constantly evaluate whether their pursuit of realism crosses into deceptive territory. Features that simulate emotional states or personal memories should be clearly labeled as algorithmic approximations rather than genuine experiences. The goal should be to create tools that assist without pretending to possess human qualities. Maintaining this distinction protects users from developing inappropriate attachments to non-sentient systems.
What are the practical limitations and future trajectories?
Despite significant advancements in conversational fluidity, current implementations still face notable constraints that prevent widespread professional adoption. The application currently lacks support for document attachment and does not provide verbatim transcript generation, which limits its utility in contexts requiring precise reference or archival purposes. These functional gaps highlight the ongoing challenge of balancing real-time speech generation with comprehensive data management.
Developers have indicated that future iterations will expand beyond conversational capabilities to include task execution and environmental integration. The roadmap suggests a transition toward agents capable of performing complex workflows rather than merely discussing them. This evolution will likely require deeper system integration and enhanced security protocols to protect user data during automated operations. The industry must simultaneously address these technical hurdles while establishing robust governance frameworks for increasingly sophisticated artificial agents.
The trajectory of artificial voice technology points toward an inevitable integration into daily workflows and personal assistance routines. As systems continue to refine their conversational capabilities, the focus must shift from mere technical achievement to responsible implementation. Users will increasingly encounter interfaces that demand critical engagement rather than passive acceptance. The development of standardized transparency protocols and ethical design guidelines will determine whether these tools enhance human capability or inadvertently compromise user autonomy.
The transition from conversational simulation to task execution will require robust authentication and permission management. As agents gain the ability to interact with external applications and services, security protocols must prevent unauthorized actions or data exposure. Developers will need to implement granular control panels that allow users to dictate exactly what the system can access and modify. This level of oversight will be essential for building public trust in autonomous digital assistants.
Industry collaboration will be necessary to establish universal standards for agent behavior and data handling. Fragmented development approaches could lead to inconsistent safety measures and conflicting user expectations. Shared frameworks for testing and validation will help identify potential risks before widespread deployment. Collective responsibility will ensure that the next generation of voice technology serves as a reliable foundation for future digital ecosystems.
Looking Ahead: Balancing Innovation with Responsibility
The conversation surrounding artificial intelligence must remain grounded in practical utility while acknowledging the profound psychological implications of human-like interaction. Future progress depends on balancing innovation with deliberate safeguards that preserve the distinction between sophisticated simulation and genuine understanding. The industry must prioritize long-term societal impact over short-term engagement metrics. Responsible development will ensure that technological advancement serves human interests without eroding fundamental boundaries between machine and mind.
As voice interfaces continue to mature, users will need to approach them with informed skepticism and active participation. The tools themselves will not dictate the outcome of this technological transition; rather, the frameworks established by developers, regulators, and consumers will shape the final result. Maintaining clear distinctions between algorithmic output and human experience will remain the cornerstone of ethical AI deployment. Only through continuous dialogue and transparent design can society harness these capabilities without compromising individual autonomy.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)