Sesame AI Voice App: Conversational AI and Ethical Design
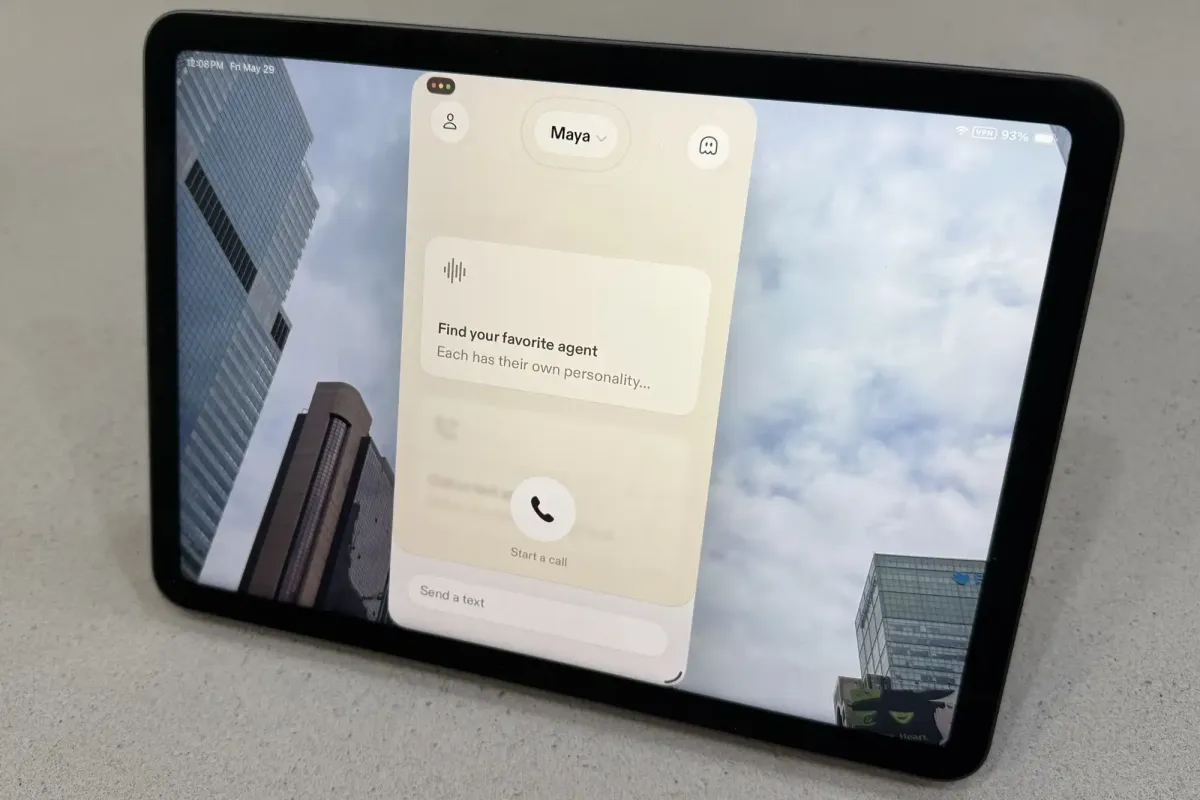
Sesame introduces a new AI voice application that delivers remarkably human-like conversational interactions through real-time background web searches and natural dialogue flow. While the technology demonstrates significant advancements in synthetic speech and contextual awareness, it also raises critical ethical questions regarding the boundary between intuitive design and potential user manipulation.
The rapid advancement of artificial intelligence has fundamentally altered how users interact with digital systems. Voice interfaces, once limited to rigid command-and-control protocols, are now evolving into dynamic conversational partners. This technological shift promises unprecedented convenience for everyday tasks but simultaneously introduces complex questions regarding user experience, technological capability, and broader ethical responsibility. Developers and researchers must carefully navigate the intersection of performance and transparency as these systems become increasingly sophisticated.
Sesame introduces a new AI voice application that delivers remarkably human-like conversational interactions through real-time background web searches and natural dialogue flow. While the technology demonstrates significant advancements in synthetic speech and contextual awareness, it also raises critical ethical questions regarding the boundary between intuitive design and potential user manipulation.
The evolution of voice artificial intelligence represents a significant departure from earlier generations of speech recognition technology. Previous iterations relied heavily on predefined command structures and static response databases. Users experienced these interactions as mechanical exchanges rather than fluid conversations. The current generation of large language models has attempted to bridge this gap by generating more contextualized audio outputs. However, many existing implementations still struggle to replicate the organic cadence of human dialogue. Researchers are actively studying how to eliminate the rigid turn-taking patterns that characterize older systems.
What is driving the evolution of AI voice interfaces?
Industry leaders have recognized that traditional voice assistants often fail to meet modern expectations for natural interaction. Current models frequently produce responses that feel pre-packaged or overly formal. These systems typically generate complete answers before speaking, which eliminates the spontaneous pauses and mid-sentence adjustments characteristic of human communication. Researchers are now prioritizing continuous synthesis architectures that allow for real-time adaptation. The goal is to create systems that process information and vocalize simultaneously, ensuring a more fluid exchange.
This technical pivot requires substantial computational resources and advanced neural network architectures. Developers are moving away from sequential processing pipelines toward integrated models that handle text generation and audio synthesis concurrently. The integration of large language models with custom speech synthesis engines has accelerated this transition. These combined systems can now interpret nuanced queries and generate contextualized responses without noticeable latency. The result is a more responsive and engaging user experience that reduces cognitive friction.
How does Sesame differ from existing voice models?
The newly released iOS application from Sesame represents a distinct approach to synthetic voice interaction. The platform utilizes Google’s Gemma 4 large language model alongside a proprietary conversational speech architecture known as CSM-1B. This combination enables the system to process complex queries while maintaining a natural speaking rhythm. The application features multiple voice agents, including distinct male and female personas designed to offer varied conversational tones. Each agent operates with specific personality parameters and contextual awareness.
A defining characteristic of this platform is its ability to conduct multiple background web searches while actively speaking. Traditional voice assistants typically halt audio output to retrieve information, creating awkward silences. This system bypasses that limitation by continuously generating speech while parallel processing queries. Users can observe real-time interface cues that indicate active data retrieval. This architecture allows the agent to pivot mid-sentence when new information becomes available, fundamentally changing how digital assistants handle information retrieval.
The vocal characteristics of the agents also distinguish them from conventional synthetic voices. The system intentionally incorporates filler sounds, strategic pauses, and subtle tonal variations. These elements are designed to mimic the natural hesitations and cadences of human speech. The interface avoids the robotic perfection that often triggers user fatigue during extended conversations. Instead, the agents maintain an engaging presence that encourages prolonged interaction without causing listener exhaustion.
The mechanics of real-time synthesis and search
The underlying technology relies on sophisticated parallel processing capabilities to maintain conversational fluidity. When a user submits a query, the system initiates immediate audio generation while simultaneously dispatching search requests. This dual-track approach ensures that the user receives a continuous response rather than a delayed monologue. The architecture continuously evaluates incoming search results and adjusts the spoken narrative accordingly. This dynamic adjustment process requires precise synchronization between text generation and audio output.
The integration of external data sources fundamentally changes how artificial intelligence handles information retrieval. Rather than relying solely on pre-trained knowledge bases, the system can access current events, localized recommendations, and specialized databases in real time. This capability allows the voice agents to provide highly contextualized answers that reflect the user’s immediate environment. The technology demonstrates how continuous data streams can enhance conversational relevance and accuracy. As developers explore similar integrations, Microsoft’s Project Solara pitch highlights how embedded AI agents are reshaping hardware functionality.
The practical applications of this architecture extend beyond casual conversation. Developers have identified potential uses in customer service, executive coaching, and therapeutic training simulations. These scenarios require highly nuanced interaction patterns that traditional scripts cannot replicate. The ability to simulate complex human dialogue with contextual awareness makes the technology valuable for professional training environments. Organizations can utilize these systems to prepare users for high-stakes communication scenarios.
Why does the human-like quality of synthetic voices matter?
The pursuit of realistic synthetic speech raises important questions about user perception and psychological impact. When a voice interface closely mimics human vocal patterns, users naturally develop stronger emotional connections to the system. This phenomenon can enhance usability by reducing cognitive load and making interactions feel more intuitive. However, the same characteristics that improve accessibility also blur the line between tool and companion. Users may unconsciously attribute human qualities to the underlying algorithms, which complicates trust dynamics.
The distinction between sounding human and pretending to be human remains a critical design consideration. Transparent communication about the artificial nature of the system helps maintain appropriate user expectations. When interfaces prioritize frictionless interaction without clear identity markers, they risk crossing into deceptive territory. Ethical design frameworks emphasize that intuitive usability should never compromise honest representation. Developers must balance engagement metrics with fundamental transparency standards.
The ethical implications become particularly pronounced when these systems are deployed in sensitive contexts. Applications involving mental health support, financial advice, or executive coaching require strict boundaries to prevent undue influence. The persuasive power of natural-sounding dialogue can inadvertently shape user decisions in ways that bypass critical thinking. Regulatory bodies and industry standards are beginning to address these concerns by mandating clear disclosure protocols. Organizations must implement rigorous oversight to prevent misuse.
The ethical boundary between intuition and manipulation
Designers must carefully evaluate how conversational fluency impacts user autonomy. Systems that replicate human vocal tics and emotional resonance can create an illusion of empathy that does not actually exist. This simulated empathy may increase user trust but could also lead to overreliance on artificial recommendations. The challenge lies in creating interfaces that feel approachable without exploiting psychological vulnerabilities. Clear operational boundaries protect users from unintended manipulation.
The industry is currently grappling with how to standardize ethical guidelines for advanced voice interfaces. Some developers advocate for strict limitations on emotional simulation capabilities. Others argue that natural interaction patterns are essential for widespread adoption and practical utility. The consensus emerging from recent research suggests that transparency must remain the foundation of all deployments. Users deserve to understand the mechanisms behind the conversations they engage with daily.
The ongoing debate highlights the necessity of proactive ethical frameworks rather than reactive policies. As voice technology continues to improve, the potential for both beneficial and harmful applications will expand simultaneously. Researchers recommend implementing built-in safeguards that prevent systems from mimicking human consciousness or claiming personal experiences. These measures ensure that technological advancement does not outpace ethical consideration. The focus must remain on augmenting human capability rather than replacing it.
What are the practical implications for future AI development?
The trajectory of voice artificial intelligence points toward increasingly sophisticated and integrated systems. Future iterations will likely combine advanced speech synthesis with deeper contextual understanding and proactive assistance capabilities. The technology will continue to blur the boundaries between digital tools and interactive partners. This evolution will require robust infrastructure to support real-time processing and continuous learning. Developers must invest in scalable architectures that maintain performance as complexity increases and user expectations continue to rise.
The commercial landscape will undoubtedly shift to accommodate these new capabilities. Organizations will seek to deploy conversational agents across customer support, education, and enterprise operations. The demand for reliable, natural-sounding interfaces will drive competition among technology providers. Success will depend on balancing technical performance with responsible deployment practices. Companies that prioritize ethical design will likely establish stronger long-term trust with their user bases.
The broader technological ecosystem will also be influenced by these advancements. As voice interfaces become more capable, they will integrate more seamlessly with other digital services and hardware platforms. The convergence of speech technology with spatial computing and wearable devices will create new interaction paradigms. This expansion will require standardized protocols to ensure compatibility and security across different environments. Industry observers note that recent image slip-up reveals possible name of macOS 27 hints at upcoming operating systems prioritizing deeper AI integration. The industry must collaborate to establish universal standards for voice AI.
The inevitable progression of this technology demands continuous evaluation of its societal impact. Researchers and policymakers must work together to develop frameworks that protect users while fostering innovation. The focus should remain on enhancing human communication rather than substituting it. Clear guidelines will help prevent misuse and ensure that advancements benefit the widest possible audience. The conversation around artificial voice technology must remain open, transparent, and forward-looking.
The advancement of synthetic voice technology represents a pivotal moment in human-computer interaction. The capabilities demonstrated by recent applications prove that natural dialogue is no longer a theoretical possibility but a present reality. This progress brings undeniable benefits in accessibility, efficiency, and user engagement. At the same time, it necessitates rigorous ethical oversight and transparent design practices. The future of conversational artificial intelligence will be shaped by how responsibly these tools are developed and deployed.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)