Sesame AI Voice App: Conversational Realism and Ethics
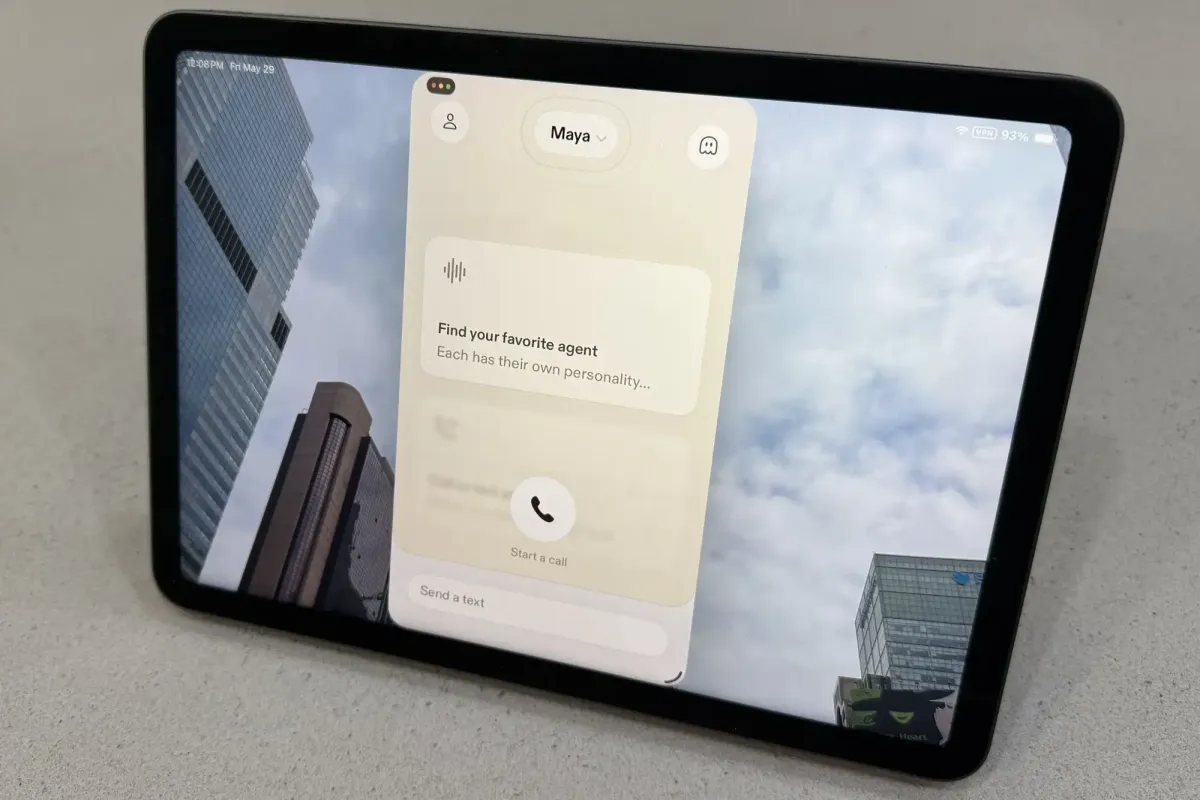
Sesame’s new AI voice app delivers a remarkably human-like conversational experience by leveraging Google’s Gemma 4 model and custom speech synthesis. The system performs real-time background searches while speaking, creating a natural dialogue flow. This capability raises important questions about the ethical boundaries of human-like design and potential user manipulation.
The rapid evolution of artificial intelligence has shifted focus from text-based interfaces to immersive auditory experiences. Developers are now prioritizing voice interaction as the next frontier in human-computer communication. Recent advancements demonstrate a clear trajectory toward systems that can process, synthesize, and respond to spoken language with unprecedented fluidity. This technological leap introduces both significant utility and complex ethical considerations for everyday users.
Sesame’s new AI voice app delivers a remarkably human-like conversational experience by leveraging Google’s Gemma 4 model and custom speech synthesis. The system performs real-time background searches while speaking, creating a natural dialogue flow. This capability raises important questions about the ethical boundaries of human-like design and potential user manipulation.
What is the current state of AI voice interaction?
Voice-enabled artificial intelligence has historically struggled with latency and robotic delivery. Early implementations relied on pre-recorded phrases or rigid text-to-speech engines that lacked emotional nuance. Users frequently reported feeling disconnected from these systems because the responses arrived as complete, unbroken monologues. The experience often resembled receiving a formal briefing rather than engaging in a dynamic exchange.
Modern iterations have attempted to bridge this gap by introducing conversational pauses and filler sounds. Developers recognized that human speech is inherently imperfect, characterized by hesitation, self-correction, and natural rhythm. Incorporating these organic qualities into digital agents requires sophisticated acoustic modeling and real-time processing capabilities. The goal remains creating an interface that feels intuitive rather than mechanical.
Despite these improvements, many current platforms still generate full responses before vocalizing them. This architectural limitation forces the system to commit to a complete narrative before speaking. Consequently, the interaction lacks the flexibility to adapt mid-sentence or incorporate newly discovered information. Users must wait for lengthy processing delays before receiving any audible feedback.
The industry is now testing hybrid approaches that combine large language models with specialized speech synthesis pipelines. These systems aim to generate audio output incrementally while simultaneously processing contextual data. The result is a more responsive dialogue that mirrors the cadence of human conversation. This shift represents a fundamental change in how digital assistants manage information retrieval and vocal delivery.
How does Sesame architecture differ from existing models?
The newly released iOS application utilizes a combination of Google’s Gemma 4 language model and a custom conversational speech architecture. This dual-engine approach allows the system to process complex queries while simultaneously generating natural vocal output. The underlying technology supports multiple voice agents, each designed with distinct tonal characteristics and conversational styles. Users can select from several options to match their preferred interaction mode.
A defining feature of this platform is its ability to conduct background web searches while actively speaking. Traditional voice assistants typically halt vocalization to perform external lookups, creating awkward silences that break conversational immersion. This system circumvents that limitation by processing external data streams in parallel with audio generation. The interface provides visual cues that indicate when background research is occurring, maintaining transparency about system operations.
The architecture enables mid-sentence pivots without disrupting the audio stream. When new information emerges during a query, the agent can adjust its response trajectory almost instantly. This capability requires substantial computational overhead and highly optimized neural networks. The system must balance latency constraints with the need for accurate, context-aware information retrieval.
Visual feedback within the application reinforces the technical process without overwhelming the user. Progress indicators and status notifications inform individuals about active searches and processing stages. This design choice aligns with modern usability principles that prioritize clarity and user control. The interface successfully communicates complex backend operations through simple, intuitive visual language.
Why does conversational realism matter in artificial intelligence?
The pursuit of human-like vocal delivery stems from a desire to reduce cognitive friction during digital interactions. When an interface mimics natural speech patterns, users experience less mental strain while processing information. The brain recognizes familiar auditory cues and responds with greater comfort and engagement. This psychological alignment makes complex tasks feel more manageable and less intimidating.
Realistic voice synthesis also enhances accessibility for individuals who struggle with traditional text-based interfaces. Spoken dialogue provides an alternative pathway for information consumption that accommodates varying literacy levels and visual impairments. The technology effectively lowers the barrier to entry for advanced computational tools. This democratization of access represents a significant societal benefit of modern voice AI development.
However, the pursuit of realism introduces unintended psychological consequences. When a system sounds indistinguishable from a human speaker, users may unconsciously attribute human qualities to the software. This phenomenon, known as anthropomorphism, can lead to misplaced trust or emotional dependency. The boundary between functional tool and simulated companion becomes increasingly blurred.
Developers must carefully calibrate the level of realism to balance usability with ethical responsibility. Excessive human mimicry can create deceptive interactions that exploit cognitive biases. The industry faces the challenge of creating systems that feel natural without crossing into manipulative territory. Transparent design practices remain essential for maintaining user autonomy and informed consent.
What are the ethical boundaries of human-like AI agents?
The emergence of highly realistic voice agents has sparked intense debate regarding digital deception. Critics argue that systems designed to sound human inevitably risk misleading users about their true nature. Even when developers explicitly state that an agent is artificial, the auditory experience often overrides rational acknowledgment. This disconnect between stated identity and perceived reality creates ethical complications.
Proponents of advanced voice synthesis emphasize the importance of frictionless interaction over artificial distinction. They argue that natural dialogue reduces user fatigue and improves task completion rates. The technology serves as a practical tool rather than a psychological experiment. When implemented responsibly, human-like vocal delivery can enhance productivity and streamline complex workflows.
Transparency remains the primary safeguard against potential misuse. Systems that clearly communicate their operational parameters and limitations maintain user trust. Developers must avoid designing interfaces that intentionally obscure the artificial nature of the agent. Clear disclosure of data processing methods and system capabilities protects consumers from unwanted manipulation.
The broader implications extend beyond individual applications to industry-wide standards. Similar to recent explorations of autonomous digital assistants, such as those detailed in coverage of Microsoft’s Project Solara, the industry is testing how much autonomy voice agents should possess. Organizations must establish clear guidelines for vocal authenticity and user consent. The technology will continue to evolve regardless of ethical debates, making proactive governance essential.
How should users approach emerging voice AI technology?
Navigating the landscape of advanced voice assistants requires a balanced perspective on both utility and limitation. Users should recognize that these systems excel at information retrieval and conversational simulation but lack genuine consciousness or emotional understanding. Treating the technology as a sophisticated tool rather than a sentient entity prevents misplaced emotional investment. This mindset preserves critical thinking skills during digital interactions.
Practical usage involves understanding the technical constraints of real-time processing. Background searches and vocal synthesis require substantial computational resources that may introduce latency during complex queries. Users should allow adequate processing time when requesting detailed information. Patience during these intervals ensures more accurate and comprehensive responses.
Privacy considerations remain paramount when utilizing voice-enabled platforms. Continuous audio processing and location data access require careful permission management. Individuals should regularly review application settings to verify data collection practices. Understanding how voice recordings are stored and processed helps maintain personal security boundaries.
The future of voice interaction will likely integrate more deeply with wearable technology and smart environments. Systems will increasingly operate in the background, anticipating needs and providing contextual assistance. This evolution demands ongoing user education about digital literacy and technological awareness. Staying informed about platform capabilities ensures responsible and effective adoption.
What comes next for voice-driven artificial intelligence?
The trajectory of artificial intelligence points toward increasingly seamless auditory interfaces. Developers continue refining speech synthesis and contextual processing to deliver more responsive interactions. This technological progression will undoubtedly reshape how individuals access information and complete daily tasks. The focus must remain on balancing innovation with ethical responsibility.
Users who approach these tools with informed skepticism will benefit most from their capabilities. Recognizing both the practical advantages and inherent limitations of voice AI enables healthier digital habits. The technology serves as a powerful assistant when deployed transparently and responsibly. Continued dialogue between developers, regulators, and consumers will shape the future of this rapidly evolving field.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)