How Real-Time AI Voice Is Reshaping Digital Interaction
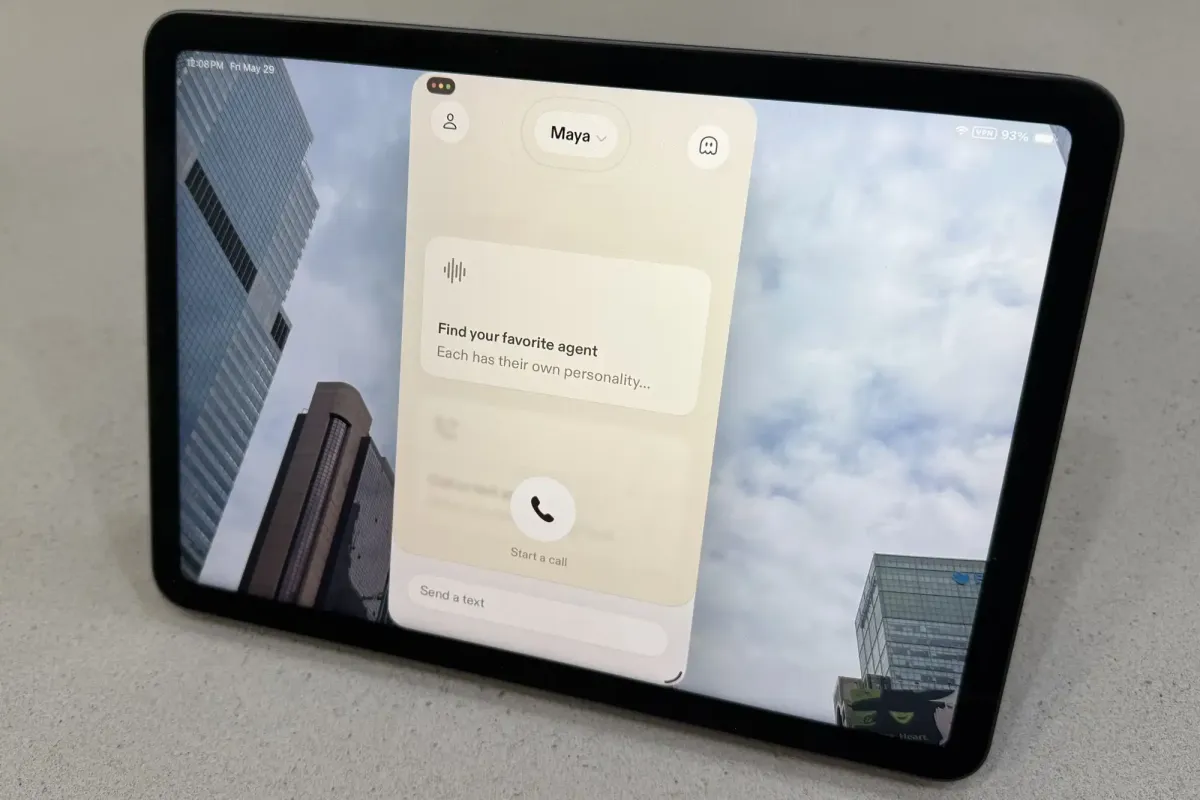
Sesame’s new iOS app combines Google’s Gemma 4 model with custom speech synthesis to deliver highly realistic dialogue. By performing background web searches while speaking, it avoids the rigid structure of traditional AI voice modes. This advancement raises critical questions about transparency, user manipulation, and the future of synthetic media.
The rapid evolution of artificial intelligence has shifted focus from text-based queries to fluid, spoken dialogue. Recent developments in voice synthesis and large language model integration have produced systems that respond with unprecedented speed and natural cadence. This technological leap introduces both remarkable utility and complex questions regarding how users perceive synthetic interactions. The industry now faces the challenge of balancing performance with psychological impact.
Sesame’s new iOS app combines Google’s Gemma 4 model with custom speech synthesis to deliver highly realistic dialogue. By performing background web searches while speaking, it avoids the rigid structure of traditional AI voice modes. This advancement raises critical questions about transparency, user manipulation, and the future of synthetic media.
What is the current state of AI voice interaction?
For years, digital assistants have relied on voice output that reads pre-generated text aloud. This approach creates a noticeable disconnect between information retrieval and delivery speed. Users frequently encounter responses that sound rehearsed and lack organic pauses. The technology has improved significantly, yet the fundamental architecture often remains rooted in sequential processing. This design prioritizes structural accuracy over conversational fluidity in every interaction.
A query is submitted, the system formulates a complete answer, and the audio engine renders it in one continuous stream. This method prioritizes accuracy over conversational fluidity. The result is an experience that feels more like listening to a broadcast. Developers have recognized this limitation and are exploring new architectures. The primary goal is to bridge the gap between computational speed and natural communication.
How does real-time conversational processing change user experience?
The introduction of systems that process information while speaking represents a fundamental shift in interaction design. Instead of waiting for a complete response to render, the application can simultaneously query external data sources. This parallel processing capability allows the system to maintain momentum during a conversation. Users no longer experience the awkward silence that typically accompanies complex queries.
The interface can also display visual indicators of ongoing background activity. This transparency helps users understand that the interaction is dynamic rather than static. The psychological impact of this design is notable. When a system demonstrates the ability to pivot mid-sentence, it creates an impression of active listening. This perception reduces cognitive load for the user.
The experience becomes iterative and collaborative rather than transactional. Users can formulate follow-up questions without waiting for a monologue to conclude. The system can also incorporate newly discovered information into its ongoing response. This capability transforms the interaction from a simple Q and A format into a continuous dialogue. The technology effectively removes the friction that previously defined digital conversations.
Technical Architecture and Latency Management
Building a voice system that maintains natural cadence while performing complex computational tasks requires sophisticated engineering. The underlying framework must manage multiple concurrent processes without introducing perceptible delays. Speech synthesis models are trained to replicate human vocal patterns, including filler sounds and strategic pauses. These elements serve as cognitive cues that signal processing time.
When paired with a large language model capable of rapid contextual analysis, the system can generate responses that feel immediate. The integration of custom speech architectures allows developers to fine-tune how the model handles interruptions. Latency remains the primary engineering challenge in this space. Even minor delays can break the illusion of natural conversation.
Engineers address this by optimizing data pathways and implementing predictive text generation. The result is a system that can seamlessly blend information retrieval with vocal delivery. Developers must constantly balance computational demands with user expectations. The architecture must be robust enough to handle unexpected queries while maintaining a smooth conversational flow.
Why does human-like vocalization trigger ethical concerns?
The pursuit of natural-sounding artificial intelligence inevitably intersects with questions of authenticity and user consent. When a system successfully replicates human vocal tics, it can evoke emotional responses that blur the boundary between tool and companion. This phenomenon is not new, but the current generation of models achieves it with unprecedented accuracy.
Users may find themselves attributing empathy to a system that operates purely on mathematical probability. The ethical dilemma centers on transparency. Developers must balance the desire for intuitive design with the responsibility to clearly communicate the synthetic nature of the interaction. If a system is designed to feel human, does it have an obligation to explicitly state that it is not?
The tension lies in the fact that overt reminders of artificiality can disrupt the very flow that makes the technology useful. Striking the right balance requires careful interface design and clear communication policies. Users should never feel deceived about the fundamental nature of the technology they are using. Establishing trust remains a priority for developers.
The Transparency Dilemma in Synthetic Media
As voice synthesis technology advances, distinguishing between human and machine output becomes increasingly difficult for the average user. This capability raises significant concerns regarding misinformation and psychological manipulation. Systems that can mimic conversational nuance can also be engineered to persuade users in specific directions. The line between helpful assistance and subtle influence is often defined by design choices.
Developers must establish clear guidelines for how synthetic voices should represent themselves. This includes avoiding claims of consciousness or emotional experience. The responsibility extends to how the system handles sensitive topics and personal data. Users need to trust that their interactions are being processed securely. Regulatory frameworks are still evolving to address these challenges.
Industry standards will likely emerge that mandate clear labeling for all voice-based artificial intelligence products. Transparency must be woven into the core architecture rather than treated as an afterthought. The goal is to empower users with accurate information about the tools they use. This approach fosters a healthier relationship between humans and machines.
What are the practical applications for enterprise and consumer markets?
The utility of advanced voice interaction extends far beyond casual conversation. Customer service, executive coaching, and therapeutic training represent just a few of the domains where realistic dialogue can provide significant value. Systems that can simulate complex human interactions offer a safe environment for practice and skill development. Professionals can rehearse difficult conversations without real-world consequences.
The technology also streamlines routine tasks by allowing users to interact with digital tools through natural language. This reduces the friction associated with traditional graphical interfaces. The shift from command-based interaction to conversational assistance will redefine how people engage with digital environments. As the technology matures, integration with existing workplace software will become standard.
Voice commands will evolve into collaborative dialogue that can manage schedules and analyze data. This capability makes technology more accessible to non-technical users. The industry is moving toward a model where assistance is proactive rather than reactive. Organizations that adopt these systems early will likely see significant improvements in operational efficiency and user satisfaction.
Integration with Workplace Automation and Security
The deployment of conversational AI in professional settings requires careful consideration of security and operational efficiency. Organizations are increasingly exploring how voice-based agents can complement existing automation frameworks. Platforms like Microsoft Project Solara demonstrate how AI agents can be integrated into workplace infrastructure to manage tasks.
Voice interaction adds a layer of accessibility and speed to these systems. Employees can initiate complex processes through natural dialogue without navigating multiple menus. However, this integration also introduces new security considerations. Voice data must be encrypted and processed in compliance with privacy regulations. Authentication mechanisms need to verify user identity without compromising the seamless nature of the conversation.
Developers are working on biometric verification and contextual awareness to ensure that voice agents only respond to authorized users. The future of workplace automation will likely combine voice interaction with robust security protocols. This combination will create efficient yet protected digital environments. The industry must prioritize both innovation and safety as these systems become more widespread.
What is the future trajectory of synthetic voice technology?
The evolution of conversational AI will continue to accelerate as computational power increases and modeling techniques improve. Systems will likely become more context-aware, capable of remembering long-term preferences and adapting to individual communication styles. This progression will blur the lines between standalone applications and integrated digital ecosystems. Users will expect seamless transitions between text, voice, and visual interfaces.
As these capabilities expand, the focus will shift toward responsible deployment and ethical oversight. Developers will need to implement stricter safeguards against misuse while preserving the intuitive nature of the technology. The industry must establish clear boundaries for how synthetic voices can be used in sensitive contexts. Public trust will depend on consistent transparency and user control.
The conversation about artificial intelligence is no longer about whether it can sound human, but about how we choose to live alongside it. The technology itself is neutral, but its implementation will determine whether it enhances human capability or undermines trust. As these systems become more sophisticated, the focus will shift from how well they mimic human speech to how responsibly they are deployed.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)