Sesame AI Voice App Redefines Conversational AI and Raises Ethical Questions
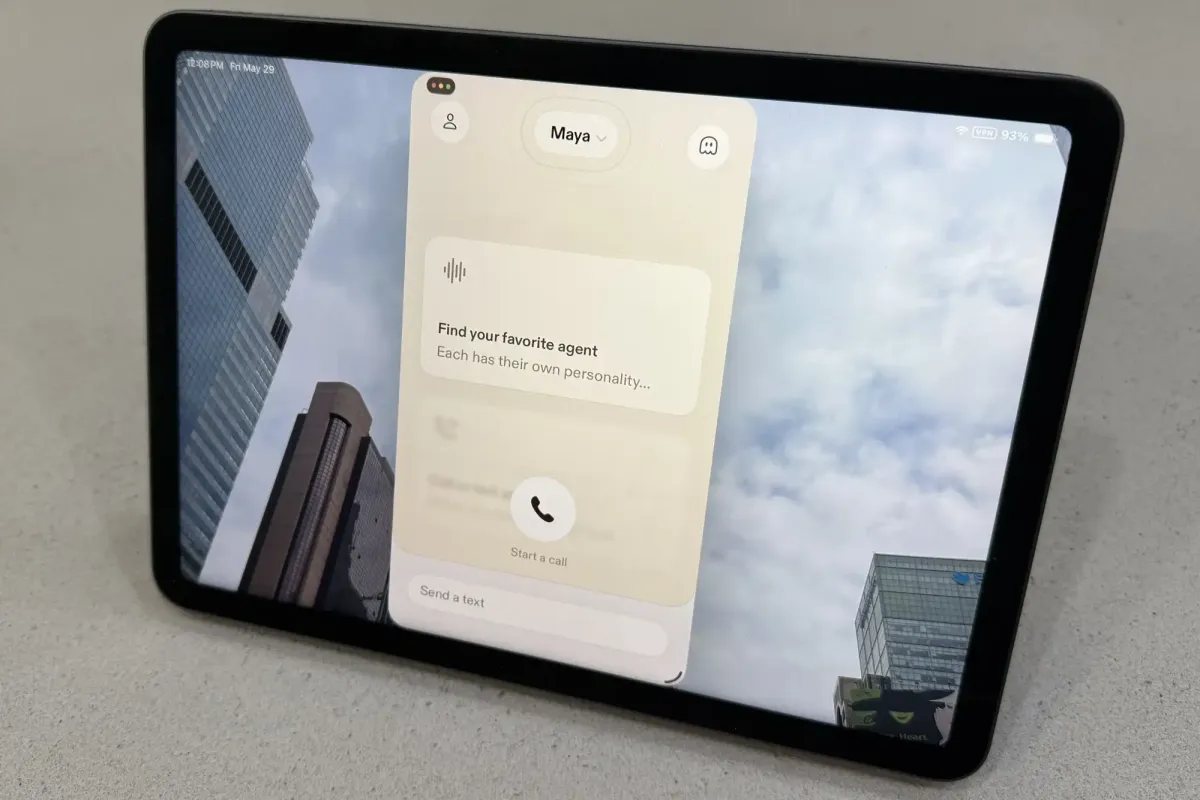
Sesame’s new iOS application delivers the most natural conversational AI voice experience to date by combining Google’s Gemma 4 language model with custom speech synthesis. The system performs live web searches during dialogue, creating a fluid exchange that challenges existing boundaries between intuitive design and potential user manipulation.
The intersection of artificial intelligence and human communication has reached a critical threshold that demands careful examination. Recent advancements in voice synthesis have shifted the focus from mere text-to-speech conversion to dynamic, context-aware dialogue. This evolution presents both remarkable utility and profound philosophical questions regarding the nature of machine interaction. Understanding these developments requires a comprehensive analysis of the underlying technology and its broader societal impact.
Sesame’s new iOS application delivers the most natural conversational AI voice experience to date by combining Google’s Gemma 4 language model with custom speech synthesis. The system performs live web searches during dialogue, creating a fluid exchange that challenges existing boundaries between intuitive design and potential user manipulation.
What is the current state of AI voice interaction?
The landscape of artificial intelligence voice assistants has historically been defined by rigid command structures and predictable response patterns. Early implementations prioritized functional accuracy over conversational fluidity, resulting in systems that processed inputs and delivered preformatted outputs. Users quickly recognized the artificial nature of these exchanges, noting the mechanical pacing and lack of contextual adaptation. This limitation created a persistent barrier to widespread adoption for complex tasks.
Modern iterations have attempted to bridge this gap by incorporating large language models into voice frameworks. These systems can now generate more coherent responses and understand nuanced queries. However, the fundamental architecture often remains rooted in sequential processing. The assistant formulates a complete answer internally before vocalizing it, which preserves the illusion of a prepared lecture rather than a spontaneous discussion. This structural constraint limits the perceived authenticity of the interaction.
Industry leaders have acknowledged this shortcoming and are actively developing new paradigms to address it. The goal is to transition from static response generation to dynamic conversational flow. Developers are experimenting with parallel processing techniques that allow the system to evaluate incoming data while simultaneously producing audio output. This approach aims to replicate the natural cadence of human dialogue, where thought and speech occur concurrently rather than in isolated stages.
How does Sesame redefine conversational AI?
Sesame represents a significant departure from traditional voice assistant architectures by prioritizing real-time adaptability. The application utilizes a combination of Google’s Gemma 4 language model and a proprietary conversational speech framework. This dual-engine approach enables the system to process linguistic inputs and generate vocal responses with minimal latency. The result is a dialogue that feels continuous rather than segmented into distinct query and response phases.
The application features multiple distinct voice agents designed to simulate different conversational styles. Each agent incorporates subtle vocal characteristics such as intentional pauses, filler sounds, and tonal variations. These elements are not merely decorative but serve a functional purpose in signaling cognitive processing. Users report that the presence of these micro-pauses creates a psychological space that mimics natural human listening and thinking patterns.
A defining characteristic of this system is its ability to conduct background web searches while actively speaking. Traditional voice assistants typically halt vocalization to perform research, creating awkward silences that break conversational momentum. Sesame circumvents this issue by weaving search results directly into the ongoing dialogue. The agent can pivot its response mid-sentence when new information emerges, demonstrating a level of contextual agility that previous generations of assistants could not achieve.
What technical mechanisms enable real-time dialogue?
The underlying architecture of this voice application relies on sophisticated parallel processing pipelines. When a user submits a query, the system simultaneously activates multiple computational threads. One thread manages the linguistic understanding and response formulation, while another continuously monitors external data sources for relevant updates. This concurrent execution allows the voice agent to maintain vocal output without sacrificing informational accuracy.
The custom speech synthesis model plays a crucial role in maintaining vocal continuity. Rather than stitching together pre-recorded phonemes, the system generates audio waveforms dynamically based on the evolving context of the conversation. This approach ensures that intonation and pacing adjust naturally to the content being delivered. The model also incorporates probabilistic timing mechanisms that introduce realistic hesitations and breath patterns without disrupting the overall flow of information.
Transparency indicators within the user interface provide visibility into these background operations. The application displays real-time status updates that reveal when the system is accessing external databases or recalculating responses. This design choice serves both educational and practical purposes. It helps users understand the computational processes occurring behind the interface while reinforcing the system’s capability to adapt to new information without losing conversational coherence.
Why does the human-like quality of AI voice raise ethical concerns?
The pursuit of hyper-realistic voice synthesis has introduced complex ethical considerations that extend beyond technical performance. When a machine replicates the subtle vocal cues of human conversation, it triggers deep psychological responses in listeners. Users naturally project empathy, trust, and social expectations onto the system. This phenomenon, often referred to as the ELIZA effect, becomes significantly more pronounced when the auditory experience closely mirrors interpersonal communication.
The distinction between intuitive design and manipulative interface engineering grows increasingly narrow as voice technology improves. Developers face the challenge of creating systems that feel approachable and responsive without crossing into deceptive territory. The primary ethical boundary lies in transparency. Systems must clearly communicate their artificial nature while still delivering a frictionless user experience. Maintaining this balance requires careful calibration of vocal characteristics and conversational pacing.
Industry observers note that the potential for misuse increases alongside technological sophistication. Highly convincing voice agents could be deployed in customer service, education, or therapeutic contexts where emotional resonance is valuable. While these applications offer genuine utility, they also demand rigorous oversight to prevent exploitation. Users must retain the ability to recognize the artificial origin of the interaction and understand the limitations of machine empathy.
What are the broader implications for technology design?
The advancement of conversational voice AI necessitates a fundamental reevaluation of how humans interact with digital systems. Traditional interface design prioritized explicit commands and clear feedback loops. The new paradigm emphasizes implicit understanding and adaptive responses. This shift requires designers to consider not only functional efficiency but also psychological impact. Systems must be engineered to support user autonomy rather than foster dependency.
The development roadmap for these technologies points toward even more integrated experiences. Future iterations may incorporate multi-modal inputs that combine voice with visual and environmental data. The integration of intelligent wearable devices could enable seamless context awareness, allowing the system to anticipate needs before they are explicitly stated. Such capabilities will require robust privacy frameworks and explicit user consent mechanisms to maintain trust.
Regulatory bodies and industry standards organizations are beginning to address the challenges posed by realistic AI voices. New guidelines are emerging that focus on disclosure requirements, data usage transparency, and user control mechanisms. These frameworks aim to ensure that technological progress does not outpace ethical considerations. The goal is to establish clear boundaries that protect users while allowing innovation to continue.
Conclusion
The evolution of artificial intelligence voice systems marks a pivotal moment in human-computer interaction. The ability to engage in fluid, context-aware dialogue represents a significant technological achievement with profound practical applications. However, this progress demands careful navigation of ethical boundaries and user trust. As voice synthesis continues to improve, the focus must remain on creating transparent, user-centric systems that enhance rather than replace human connection. The future of this technology depends on balancing innovation with responsibility.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)