Sesame AI Voice App Raises Questions About Human-Like Interaction
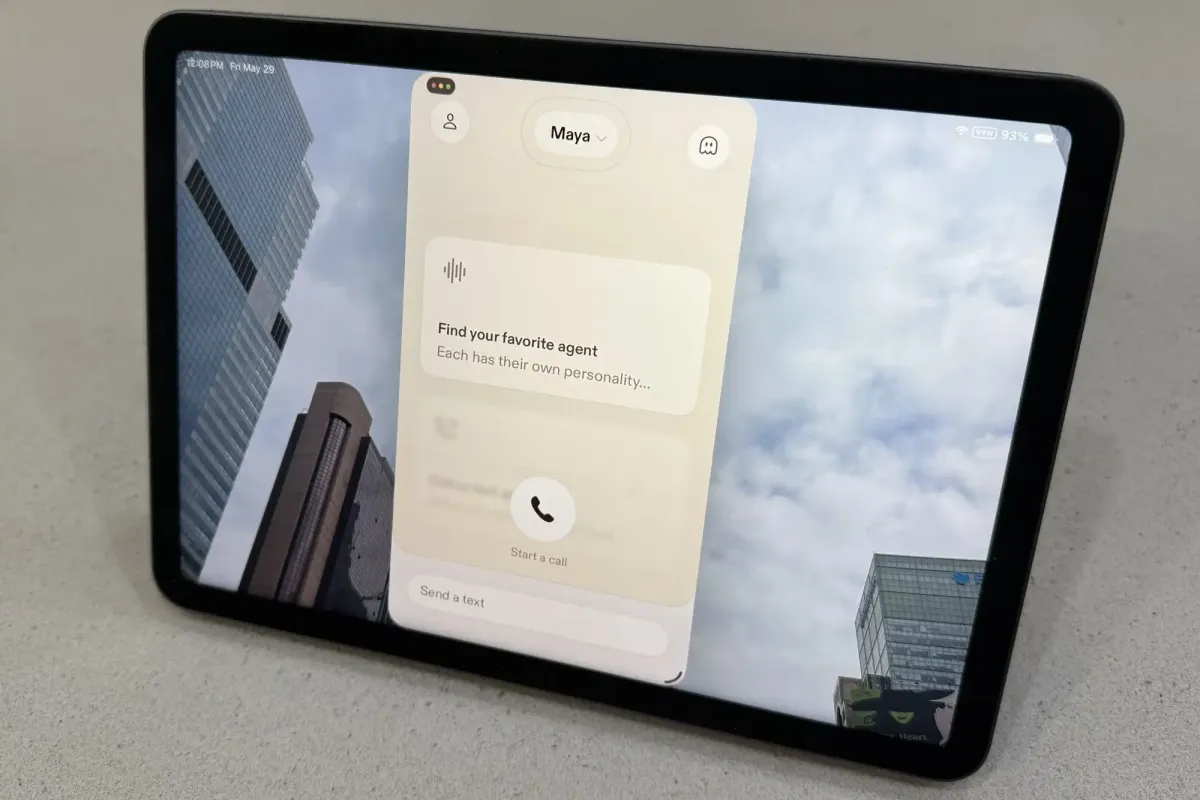
Sesame’s new iOS application delivers the most natural conversational voice experience available by combining Google’s Gemma 4 language model with custom speech synthesis. The system conducts background web searches during dialogue, yet its hyperrealistic delivery forces a necessary examination of how human-like artificial agents might subtly influence user behavior and blur ethical boundaries in digital interaction.
The rapid evolution of artificial intelligence has shifted focus from text-based interfaces to immersive auditory experiences. Developers are now prioritizing latency reduction and natural prosody to create systems that respond with human cadence rather than robotic precision. This technological leap introduces unprecedented convenience while simultaneously complicating established boundaries between machine assistance and genuine interpersonal communication.
Sesame’s new iOS application delivers the most natural conversational voice experience available by combining Google’s Gemma 4 language model with custom speech synthesis. The system conducts background web searches during dialogue, yet its hyperrealistic delivery forces a necessary examination of how human-like artificial agents might subtly influence user behavior and blur ethical boundaries in digital interaction.
What is the current state of conversational voice AI?
Early iterations of spoken language assistants relied heavily on pre-recorded phrases or rigid text-to-speech engines that struggled with emotional nuance. Users frequently reported feeling disconnected from these systems because the responses lacked organic pacing and natural hesitation patterns. Modern architectures now attempt to replicate human speech composition by generating audio tokens in real time while simultaneously processing incoming queries.
This dual-process approach allows the system to adjust its delivery dynamically rather than reciting a fully constructed monologue. The transition from static output to fluid dialogue represents a significant engineering milestone, though it also introduces new layers of complexity regarding latency management and contextual awareness. Developers must balance computational efficiency with acoustic realism to prevent listener fatigue during extended exchanges.
Foundry has spent over twelve months refining its proprietary conversational speech model alongside established large language frameworks. The resulting architecture prioritizes continuous vocalization over abrupt pauses, creating a seamless auditory experience that closely mirrors natural telephone conversations. This engineering philosophy directly addresses the primary complaint surrounding earlier voice assistants, which felt mechanical and disconnected from human interaction rhythms.
The introduction of multiple distinct voice agents further demonstrates how developers are attempting to diversify user engagement strategies. Each agent operates with unique tonal characteristics and conversational pacing, allowing individuals to select interfaces that align with their personal comfort levels. This customization represents a significant step forward in making synthetic dialogue feel less like a standardized product and more like a tailored communication tool.
How does real-time reasoning change user interaction?
Traditional voice assistants typically pause to retrieve information before generating a response, creating noticeable delays that disrupt conversational flow. Newer implementations address this friction by performing parallel processing tasks while the audio output continues. The application can query external databases and synthesize speech simultaneously, allowing the agent to pivot its narrative mid-sentence when fresh data arrives.
This capability transforms passive listening into an active collaborative experience where information updates feel organic rather than mechanical. Users no longer endure prolonged silences waiting for a complete answer to materialize on screen or through speakers. The system effectively buys time through continuous vocalization while conducting complex backend operations, resulting in interactions that closely mirror natural human problem-solving patterns during phone conversations.
The ability to conduct multiple background searches while speaking fundamentally alters how information is consumed in mobile environments. Individuals can receive location-based recommendations, entertainment schedules, or technical explanations without interrupting their physical activities. This continuous flow of data eliminates the cognitive friction associated with switching between applications and waiting for discrete responses to load.
Engineering teams have also focused on reducing the latency gap between user input and system acknowledgment. By maintaining a steady stream of conversational markers, the software keeps users engaged during computational heavy lifting. The result is an interface that feels responsive and attentive rather than sluggish or disconnected from the ongoing dialogue.
Why do human-like vocal patterns raise ethical questions?
The deliberate incorporation of filler sounds and strategic pauses serves a specific psychological purpose within synthetic dialogue design. These micro-behaviors signal active listening and cognitive processing to the human counterpart, fostering an illusion of genuine comprehension. When artificial agents successfully replicate these subtle acoustic markers, they cross into territory where users may unconsciously attribute consciousness or emotional depth to the software.
This phenomenon creates a delicate operational boundary between intuitive interface design and potential psychological manipulation. Designers must carefully calibrate how closely their systems mimic biological speech without crossing into deceptive territory that compromises user autonomy. The technology itself remains neutral, but its deployment strategies require rigorous ethical oversight to prevent exploitation of human social instincts.
Transparency regarding system capabilities becomes increasingly critical as vocal realism improves. Users should never experience confusion about whether they are interacting with a machine or a person during sensitive conversations. Clear disclosure mechanisms must be embedded directly into the application framework rather than buried in lengthy terms of service documents that most individuals skip entirely.
The tension between frictionless design and honest representation defines the current ethical landscape for conversational AI. Companies that prioritize acoustic fidelity above all else risk normalizing deceptive interaction patterns across broader technology sectors. Responsible development requires maintaining explicit boundaries between simulation and reality, even when doing so slightly reduces interface polish.
The transparency threshold in synthetic dialogue
Maintaining clear boundaries between machine assistance and simulated personhood requires consistent operational honesty from development teams. Systems should acknowledge their computational nature during complex exchanges rather than relying solely on acoustic realism to build trust. Users benefit when applications explicitly state their limitations regarding memory retention or emotional capacity.
This straightforward approach prevents the gradual erosion of user skepticism that occurs when artificial agents consistently perform beyond their actual capabilities. Transparency protocols must be embedded directly into the interaction framework rather than treated as afterthoughts during product launches. Clear communication about system capabilities ensures that users maintain appropriate expectations regarding automated assistance.
Industry standards will likely evolve to mandate specific disclosure requirements for hyperrealistic voice interfaces. Regulatory frameworks may eventually require audible or visual indicators whenever synthetic agents are actively processing queries. Such measures would protect consumers from unintended psychological manipulation while preserving the utility of advanced conversational tools.
What practical applications emerge from advanced voice synthesis?
The commercial viability of highly realistic conversational systems extends well beyond casual inquiry and entertainment sectors. Enterprise environments stand to gain substantial efficiency improvements by deploying these tools for executive coaching simulations and therapeutic training scenarios. Organizations can utilize the technology to recreate high-stakes professional interactions without exposing human staff to repetitive role-playing exercises.
Medical professionals might employ the system to practice difficult patient conversations while receiving immediate feedback on tone and pacing adjustments. Customer service departments could implement adaptive agents that maintain contextual continuity across lengthy support tickets, reducing resolution times significantly. The underlying architecture supports scalable deployment across multiple industries where nuanced communication directly impacts operational outcomes.
The integration of conversational AI into professional workflows also necessitates careful consideration of workforce adaptation strategies. Employees must understand how to collaborate effectively with synthetic colleagues without developing overreliance on automated assistance. Training programs should emphasize critical thinking and verification skills alongside technical proficiency in managing these new digital tools.
Looking ahead, the convergence of voice synthesis and workplace automation will likely reshape traditional communication hierarchies. Microsoft’s Scout AI agent is aimed directly at your workplace, illustrating how major technology providers are already positioning conversational interfaces as central components of modern business infrastructure. Organizations that adapt quickly to these changes will maintain competitive advantages in efficiency and customer engagement.
How does industry adoption reshape digital communication standards?
The widespread integration of conversational AI requires careful consideration of workforce adaptation and user training protocols. Companies must establish clear guidelines regarding when synthetic voices should be utilized versus human representatives during critical support interactions. Regulatory frameworks will likely evolve to mandate disclosure requirements for automated systems handling sensitive personal data or financial transactions.
This shift demands that technology providers prioritize interoperability and accessibility alongside acoustic fidelity. Standardized protocols for voice authentication and identity verification will become essential as synthetic agents gain greater autonomy in professional environments. Organizations that fail to implement robust oversight mechanisms risk exposing themselves to compliance violations and reputational damage during future audits.
Continuous monitoring of user feedback will shape future development cycles across the entire industry. Developers must remain responsive to public concerns regarding privacy, manipulation, and emotional dependency on artificial systems. Balancing innovation with social responsibility will determine which companies successfully navigate the coming decade of auditory technology expansion.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)