Sesame AI Voice App Raises Questions About Natural Interaction and Ethics
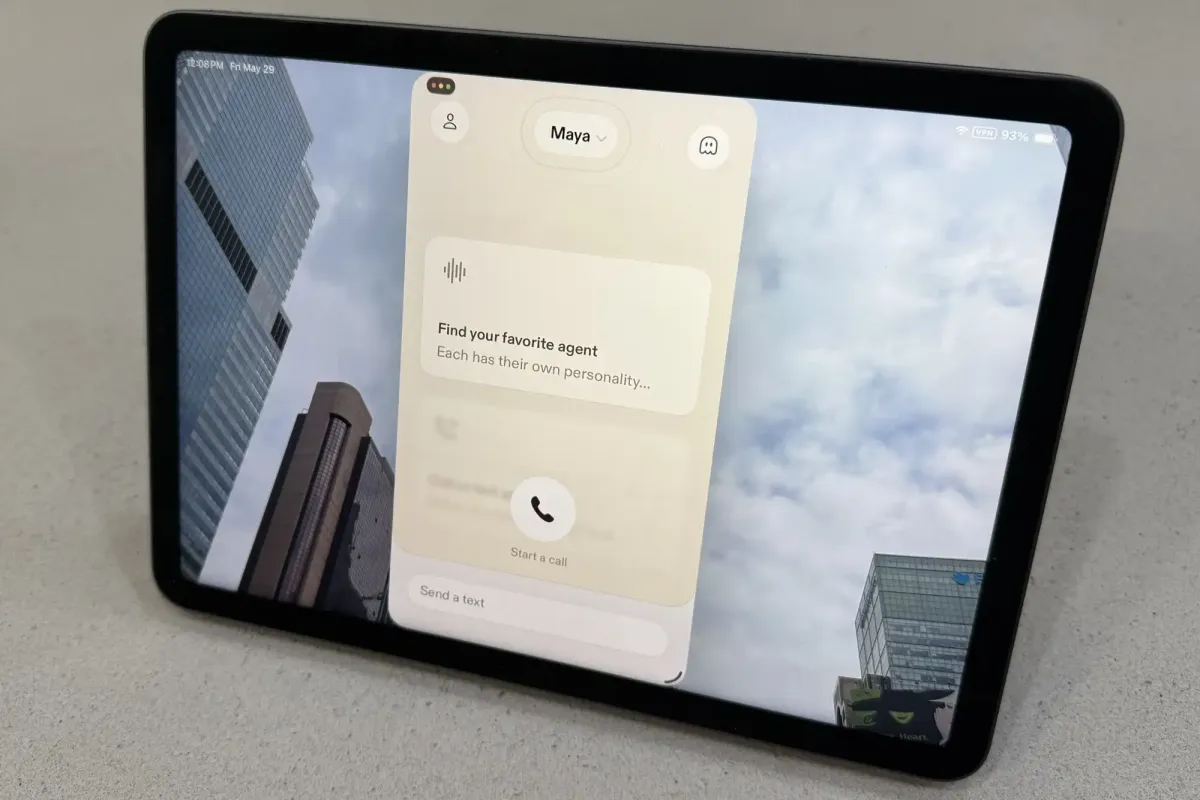
Sesame has released a free iOS application that utilizes advanced language models and custom speech synthesis to deliver highly natural conversational audio. The system performs real-time web searches while speaking, creating fluid dialogue that contrasts with traditional lecture-style AI responses. This technological leap raises important questions about transparency, user manipulation, and the future of human-computer interaction in modern digital spaces.
The rapid advancement of artificial intelligence has fundamentally altered how users interact with digital assistants. Recent developments in voice synthesis have moved beyond simple command execution toward complex, fluid dialogue systems that mimic human conversational patterns. A recent release from Sesame exemplifies this trajectory, introducing a mobile application capable of generating highly natural audio responses while simultaneously processing live information. This capability marks a significant departure from earlier iterations of automated speech, yet it also introduces complex questions regarding user trust and interface design.
Sesame has released a free iOS application that utilizes advanced language models and custom speech synthesis to deliver highly natural conversational audio. The system performs real-time web searches while speaking, creating fluid dialogue that contrasts with traditional lecture-style AI responses. This technological leap raises important questions about transparency, user manipulation, and the future of human-computer interaction in modern digital spaces.
What is driving the shift toward hyper-realistic AI voice interfaces?
For decades, text-to-speech technology operated within rigid parameters that prioritized mechanical accuracy over natural delivery. Early systems produced robotic outputs that required users to adapt their listening habits to accommodate unnatural pacing and tonal consistency. The industry gradually improved these outputs through statistical modeling and later neural network architectures.
A persistent gap remained between synthetic audio and genuine human speech until recent architectural innovations emerged. Current voice modes in major conversational platforms often function as broadcast mechanisms rather than interactive dialogue systems. They generate complete responses before playback begins, resulting in monologues that lack the organic cadence of spontaneous conversation.
Sesame addresses this limitation through a dual-engine approach designed to simulate active listening and processing. The application relies on Google Gemma 4, a large language model optimized for efficient local and cloud processing. This foundation pairs with CSM-1B, a proprietary conversational speech architecture developed specifically by the company.
This combination allows the system to generate audio streams dynamically while simultaneously evaluating incoming user input. The result is an interface that pauses naturally, incorporates filler sounds like hesitations and breaths, and adjusts its tone based on contextual cues. Engineers have spent considerable effort refining these micro-pauses because they serve as critical signals of active processing.
When a system mimics the slight irregularities of human speech patterns, users experience reduced cognitive friction during extended interactions. The technology does not merely convert text to audio; it reconstructs dialogue in real time. This architectural shift represents a fundamental rethinking of how machines should communicate with people in everyday scenarios.
How does real-time conversational processing change user interaction?
Traditional voice assistants operate on a request-response cycle that prioritizes speed over nuance and contextual depth. Users submit a query, the system retrieves data, and an audio file plays back the compiled answer. This linear workflow creates noticeable latency and often strips away conversational context during complex exchanges.
Sesame introduces a parallel processing model that fundamentally alters this dynamic by enabling simultaneous computation streams. As the application generates spoken responses, it conducts multiple background searches to gather supplementary information without interrupting the audio output. Users can observe visual indicators within the interface showing active data retrieval while speech continues uninterrupted.
This capability enables the system to pivot mid-conversation when new facts emerge, much like a human speaker adjusting their narrative upon receiving fresh input. The continuous flow of dialogue reduces the mental effort required from users who must otherwise wait for complete responses before formulating follow-up questions.
Natural language processing benefits significantly from this iterative approach because it allows the model to refine its answers based on real-time context. The application also supports multiple distinct voice profiles, each calibrated with specific tonal qualities and pacing variations that serve functional purposes beyond mere aesthetics.
A creative collaborator might utilize a more dynamic rhythm, while an analytical assistant could employ measured pauses to emphasize precision. The underlying technology demonstrates how streaming audio generation can transform passive listening into active engagement for diverse user groups.
Why does human-like AI voice design raise ethical concerns?
The pursuit of naturalistic audio output introduces significant philosophical and practical challenges for developers and users alike. When synthetic voices incorporate realistic vocal tics, breathing patterns, and emotional inflections, they trigger subconscious social responses in human listeners that bypass rational scrutiny.
Psychological research consistently shows that people attribute greater trust and competence to speakers who exhibit authentic conversational markers, even when those markers are artificially generated through algorithmic pattern matching. This phenomenon creates a delicate boundary between intuitive interface design and potential user manipulation.
Sesame explicitly addresses this tension during internal testing phases, emphasizing that transparency must remain central to the development process. The company maintains that the objective is frictionless interaction rather than deception, yet the line between comfort and confusion grows increasingly narrow as audio synthesis improves.
Users may find themselves attributing genuine understanding or emotional presence to systems that merely simulate these qualities through mathematical calculations. This discrepancy becomes particularly problematic when applications operate in sensitive domains such as healthcare guidance, financial advice, or executive coaching scenarios.
If a voice interface consistently mirrors human conversational habits without clear disclosure of its artificial nature, users might inadvertently form parasocial attachments or overestimate the system's capabilities. Industry standards currently lack comprehensive frameworks for labeling synthetic audio in real-time conversations across different platforms.
What are the practical applications and future trajectories for this technology?
Advanced voice synthesis extends far beyond novelty applications and enters critical operational domains where auditory interfaces provide substantial advantages over traditional text or button-based controls. Customer service represents an immediate implementation target because human-like dialogue can reduce caller frustration during complex troubleshooting scenarios.
When a system can dynamically adjust its tone based on detected user stress levels while simultaneously pulling account information, resolution times decrease significantly for both consumers and support teams. Executive coaching and therapeutic training also emerge as viable use cases for this technology in professional development environments.
Simulated conversations that replicate high-stakes professional interactions allow individuals to practice communication strategies in controlled settings without risking real-world consequences. The ability to generate nuanced responses that adapt to emotional cues makes these simulations more effective than traditional role-playing exercises conducted by human trainers.
Accessibility benefits represent another crucial trajectory for conversational voice AI across diverse user demographics. Individuals with visual impairments or motor coordination challenges gain substantial independence when digital interfaces respond naturally to spoken commands rather than requiring rigid syntax or precise touch inputs.
The technology also supports multilingual translation in real time, allowing users to maintain conversational continuity across language barriers without noticeable latency. Integration with emerging wearable devices and smart home ecosystems will likely accelerate as audio becomes the primary interaction layer for ambient computing environments.
How should stakeholders navigate the future of synthetic voice interfaces?
Developers are already exploring how these voice agents can coordinate with other software tools to execute multi-step workflows through natural dialogue rather than command-line interfaces. However, widespread adoption requires robust safety architectures that prevent misuse in deepfake generation or automated persuasion campaigns across public networks.
Industry coalitions must establish certification standards for synthetic audio transparency before the technology reaches mainstream saturation levels. Users will need intuitive controls to verify whether they are interacting with human operators or algorithmic systems during critical transactions or sensitive discussions.
The future of voice computing depends on balancing innovation with accountability, ensuring that naturalistic interfaces enhance rather than exploit human psychology. Establishing transparent frameworks now will prevent future crises while preserving the genuine benefits of fluid conversational technology for all demographics.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)