Understanding the Rise of Conversational AI Voice Systems
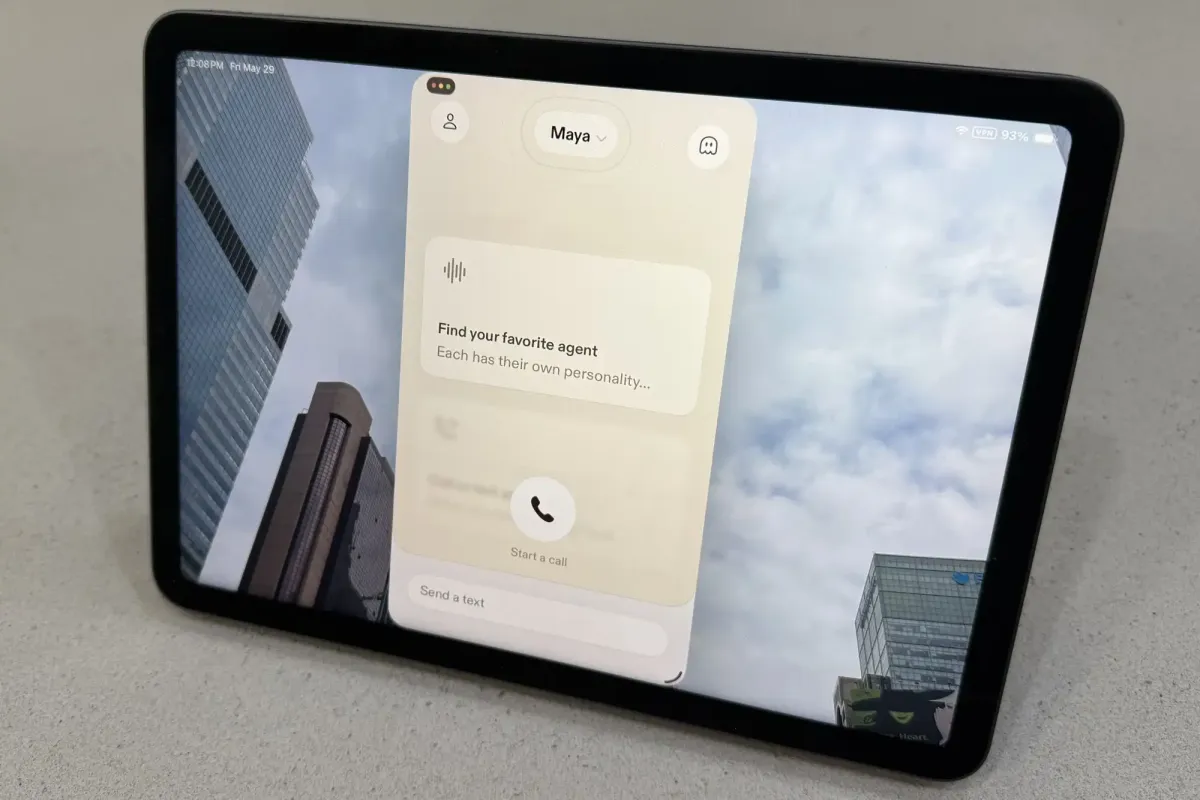
Sesame’s AI voice application delivers realistic conversational interactions by combining large language models with custom speech synthesis architectures. The platform performs real-time background searches while speaking, creating natural dialogue rather than lecture-based responses. This rapid technological progression prompts necessary industry-wide discussions about transparency and ethical boundaries for future development standards.
The rapid advancement of artificial intelligence has fundamentally altered how users interact with digital assistants across computing platforms. Recent developments in voice synthesis have moved beyond mechanical text-to-speech outputs toward fluid, context-aware dialogue that mimics human cadence and pacing. This technological shift introduces both unprecedented convenience and complex questions regarding user experience design and psychological engagement. As synthetic voices grow increasingly indistinguishable from natural speech, developers face mounting pressure to balance intuitive functionality with transparent operational boundaries.
Sesame’s AI voice application delivers realistic conversational interactions by combining large language models with custom speech synthesis architectures. The platform performs real-time background searches while speaking, creating natural dialogue rather than lecture-based responses. This rapid technological progression prompts necessary industry-wide discussions about transparency and ethical boundaries for future development standards.
The Evolution of Synthetic Speech Technologies
Early voice assistants relied on rigid phonetic mapping to convert written text into audible output. Users quickly recognized the mechanical nature of these systems, which often lacked emotional nuance or conversational pacing. Modern architectures have replaced those foundational methods with transformer-based language models capable of processing context across extended exchanges. Google’s Gemma 4 large language model now serves as a foundational component for several next-generation voice platforms, providing the structural framework for understanding complex queries and generating coherent responses. Custom speech synthesis layers build upon these linguistic foundations by introducing prosody, breath patterns, and strategic pauses that mirror human vocal behavior.
The integration of conversational speech models represents a significant departure from earlier generation systems. Developers now prioritize latency reduction alongside semantic accuracy to maintain the illusion of continuous dialogue. When an application processes information while simultaneously articulating responses, it eliminates the awkward silences that previously disrupted user engagement. This dual-processing approach allows the system to adjust its trajectory mid-conversation without breaking the flow of interaction. Users experience a sense of active listening rather than passive reception, fundamentally changing how digital tools are perceived in daily routines.
Historical attempts at natural speech generation frequently failed due to computational constraints and limited training data diversity. Contemporary models overcome these barriers through massive parameter scaling and advanced acoustic modeling techniques that account for regional accents and emotional variance. The shift from rule-based synthesis to neural network-driven generation has enabled unprecedented control over vocal timbre and resonance. Applications can now dynamically adjust pitch, volume, and tempo based on contextual cues rather than relying on static configuration files. This adaptability ensures that synthetic voices maintain consistency across diverse conversational scenarios while preserving the subtle variations that characterize authentic human communication.
Training methodologies have also evolved to prioritize conversational continuity over isolated sentence accuracy. Engineers now utilize reinforcement learning from human feedback to refine pacing and turn-taking behaviors. These iterative improvements allow systems to recognize when a user is processing information versus actively responding. The resulting architecture supports extended dialogue sessions without degradation in response quality or emotional consistency. This foundational progress establishes the technical groundwork for more sophisticated assistant ecosystems.
What Makes Conversational Voice Technology Different?
Traditional voice interfaces operate on a strictly sequential model where input triggers a complete output generation cycle. The newer conversational paradigm operates continuously, allowing the system to gather contextual data while still vocalizing its initial thoughts. Background web searches execute in parallel with speech synthesis, enabling the application to incorporate fresh information without requiring explicit pauses for processing. This capability transforms the interaction from a static query-response mechanism into a dynamic exchange that evolves alongside the user’s input.
The inclusion of natural vocal markers such as filler words and intentional hesitation patterns further distinguishes modern implementations from earlier iterations. These elements serve functional purposes beyond mere realism, providing listeners with cognitive cues about processing depth and decision confidence. When an application pauses briefly before continuing, it signals active evaluation rather than mechanical retrieval. Users report feeling less fatigued during extended conversations because the pacing aligns more closely with natural human dialogue rhythms. The psychological comfort derived from these subtle design choices significantly impacts long-term adoption rates across consumer applications.
Real-time adaptation represents another critical differentiator in contemporary voice systems. Earlier assistants struggled to recover gracefully when users interrupted or changed topics mid-sentence. Current architectures maintain contextual memory while simultaneously processing new input streams, allowing for seamless topic transitions and conversational pivots. This resilience reduces user frustration and encourages more exploratory dialogue patterns. The technology effectively bridges the gap between rigid command-based interfaces and organic human conversation, creating an environment where users feel heard rather than processed.
Latency optimization remains a primary engineering focus across development teams. Network round-trip times previously forced systems to generate complete responses before playback could begin. Modern edge computing capabilities and optimized inference pipelines now allow partial audio streams to transmit while the language model continues drafting subsequent segments. This streaming architecture creates an uninterrupted auditory experience that closely mirrors face-to-face communication. The elimination of perceptible lag fundamentally alters user expectations regarding responsiveness.
Why Does Human-Like Interaction Raise Ethical Concerns?
The pursuit of seamless user experience often intersects with complex questions about transparency and psychological influence. When synthetic voices replicate human vocal tics with high fidelity, users naturally project personality traits and emotional states onto the system. This anthropomorphic tendency can create a false sense of mutual understanding or shared intent. Developers must carefully navigate the distinction between designing intuitive interfaces and crafting interactions that subtly manipulate user expectations through simulated empathy.
Transparency remains the primary safeguard against unintended psychological effects. Clear communication about the artificial nature of the voice prevents users from forming inappropriate emotional dependencies or misattributing consciousness to algorithmic processes. The industry continues to debate where the line falls between frictionless design and deceptive realism. Regulatory frameworks are gradually adapting to address these concerns, emphasizing that technological capability should never override user autonomy. Responsible implementation requires ongoing evaluation of how vocal realism influences decision-making patterns and trust formation in digital environments.
Psychological research indicates that prolonged exposure to highly realistic synthetic voices can alter perception thresholds regarding authenticity. Users may begin accepting algorithmic suggestions as personal advice or overlook logical inconsistencies due to the comforting delivery method. This phenomenon necessitates robust ethical guidelines that prioritize user awareness over engagement metrics. Developers must implement explicit disclosure mechanisms and provide users with straightforward controls to adjust vocal realism settings. Balancing commercial objectives with psychological safety requires continuous monitoring of user feedback and independent auditing of conversational design choices.
Accountability frameworks are being established to address potential misuse scenarios involving deepfake audio and unauthorized voice cloning. Organizations must distinguish between legitimate synthetic assistance and deceptive impersonation tactics. Clear labeling standards for AI-generated media help consumers maintain critical thinking during digital interactions. The technology itself remains neutral, but its deployment requires strict governance to prevent erosion of public trust in verified communication channels.
The Practical Applications and Future Trajectory
Customer service operations represent one of the most immediate use cases for advanced conversational voice systems. Organizations require tools that can handle complex inquiries while maintaining consistent tone and contextual awareness across thousands of simultaneous interactions. Executive coaching and therapeutic training simulations also benefit from realistic dialogue generation, allowing professionals to practice high-stakes conversations in controlled environments. These applications demonstrate how nuanced vocal synthesis can bridge the gap between theoretical training and practical execution.
The roadmap for next-generation voice platforms extends beyond mobile applications into specialized hardware ecosystems. Intelligent eyewear and ambient computing devices will likely integrate these conversational architectures directly into everyday wearables. Such integration demands rigorous attention to privacy protocols, contextual awareness, and user control mechanisms. Developers must ensure that background processing capabilities operate within clearly defined boundaries to prevent unauthorized data collection or persistent monitoring. The trajectory of this technology points toward increasingly embedded assistant systems that require robust ethical guidelines alongside technical innovation.
Industry stakeholders are actively developing standards for synthetic media labeling and voice authentication protocols. These initiatives aim to protect consumers from potential misuse while preserving the legitimate benefits of advanced conversational AI. Educational institutions and corporate training programs will likely adopt these tools to simulate realistic workplace scenarios without risking actual human interactions. The continued refinement of speech synthesis models will undoubtedly introduce new capabilities, but those advancements must be paired with comprehensive safety frameworks.
Cross-platform compatibility remains a critical challenge for widespread adoption. Developers must ensure that conversational engines function reliably across diverse operating systems and hardware configurations while maintaining consistent latency performance. Standardized application programming interfaces will facilitate smoother integration between third-party services and core voice processing layers. As the ecosystem matures, interoperability standards will dictate which platforms achieve mainstream commercial success.
Conclusion
The progression from mechanical text-to-speech outputs to fluid conversational interfaces marks a significant milestone in human-computer interaction. As synthetic voices achieve greater realism through advanced language models and custom speech synthesis, the industry must prioritize transparent design practices over pure experiential optimization. Users benefit immensely from reduced latency and natural pacing, yet those advantages require careful management to prevent psychological manipulation or misplaced trust. Ongoing dialogue between developers, researchers, and regulatory bodies will determine how this technology integrates into daily life without compromising user autonomy. The focus must remain on creating tools that enhance human capability while maintaining clear boundaries around artificial consciousness simulation.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)