Sesame AI Voice App: Natural Dialogue and Ethical Design
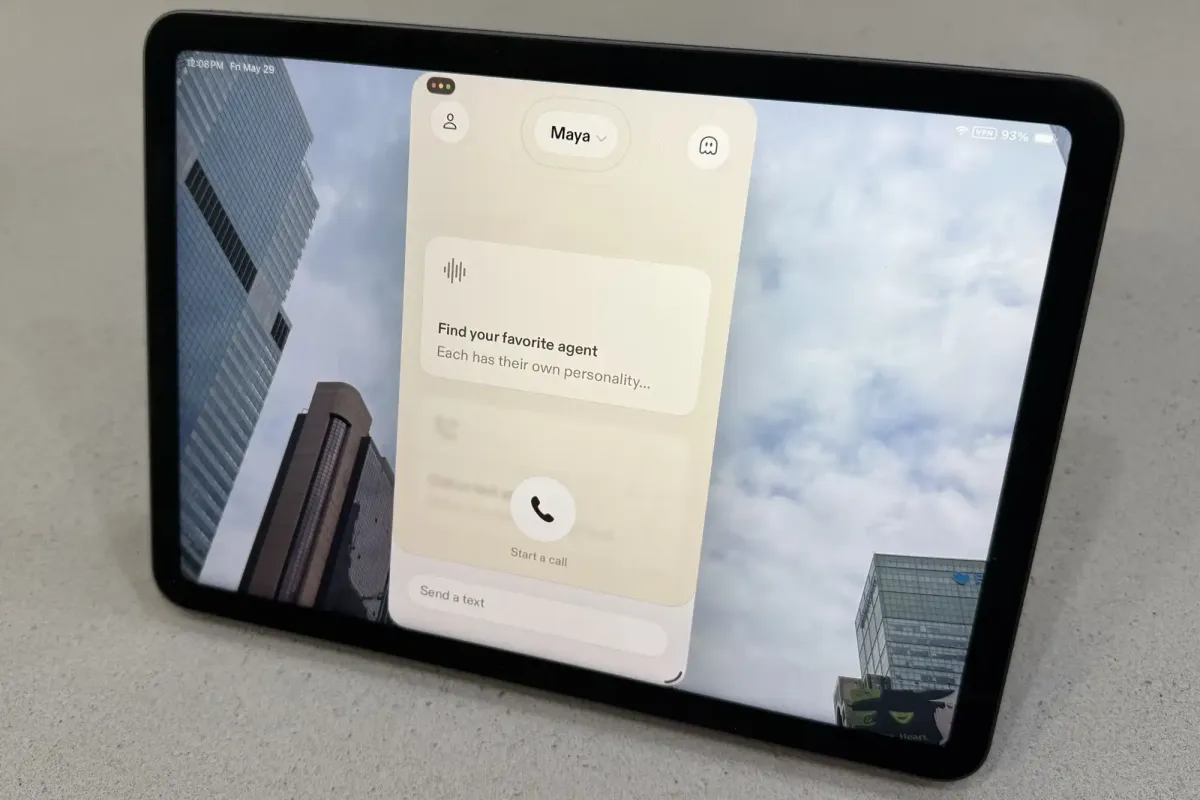
Sesame’s new AI voice application delivers highly natural conversational interactions by integrating real-time web searches directly into the dialogue process. This dynamic approach contrasts sharply with traditional voice assistants that read pre-formatted responses. The technology raises important questions about the ethical boundaries between intuitive design and potential user manipulation.
The rapid evolution of artificial intelligence has shifted the focus from mere text generation to immersive, real-time voice interaction. Developers are now racing to replicate the subtle cadences of human speech, creating systems that respond with unprecedented fluidity. This transition marks a significant departure from earlier digital assistants that delivered rigid, pre-scripted replies. The latest generation of voice applications prioritizes conversational continuity, allowing users to engage in dynamic exchanges that mimic natural dialogue. As these tools become more sophisticated, the industry must carefully examine the underlying mechanics and the broader implications of synthetic vocalization.
Sesame’s new AI voice application delivers highly natural conversational interactions by integrating real-time web searches directly into the dialogue process. This dynamic approach contrasts sharply with traditional voice assistants that read pre-formatted responses. The technology raises important questions about the ethical boundaries between intuitive design and potential user manipulation.
What is the current state of AI voice technology?
For years, digital assistants operated on a simple query-response framework that prioritized speed over nuance. Users would issue commands, and the system would retrieve information or execute tasks with minimal conversational friction. The introduction of large language models changed this paradigm by enabling more complex reasoning capabilities. However, the vocal output often remained disconnected from the cognitive process. Systems would generate complete responses offline and then read them aloud, creating a noticeable gap between thought and speech. This approach frequently resulted in stilted delivery that failed to capture the organic rhythm of human conversation. The industry recognized that true utility required bridging this divide between processing power and vocal expression.
The latest wave of applications attempts to solve this latency problem by integrating speech synthesis directly into the reasoning loop. Developers are now experimenting with models that can pause, revise, and pivot mid-sentence without breaking the auditory experience. This architectural shift allows the system to gather information dynamically while maintaining a continuous vocal stream. Users no longer experience the awkward silence that previously accompanied complex queries. Instead, they observe a conversational partner that appears to think aloud while working through a problem. This real-time processing capability represents a fundamental upgrade in how machines communicate with people.
Major technology companies have invested heavily in refining these vocal interfaces to improve accessibility and user engagement. The goal is to create systems that feel less like software and more like collaborative partners. This ambition has driven significant research into acoustic modeling and linguistic pattern recognition. Engineers focus on replicating natural breathing patterns, filler words, and tonal variations that signal active listening. The result is a generation of voice agents that can navigate complex topics with remarkable fluidity. Yet this progress also introduces new challenges regarding system design and user expectations.
How does Sesame change the conversational dynamic?
Recent applications in this space demonstrate a clear departure from traditional command-line interactions. The Sesame iOS application, for example, utilizes a combination of Google Gemma 4 large language model and a custom conversational speech model known as CSM-1B. This technical foundation enables the system to perform multiple background searches while actively speaking. Users can observe the application querying external databases without interrupting the ongoing dialogue. This capability allows the voice agent to adjust its responses dynamically as new information becomes available. The result is a highly adaptive conversation that feels responsive rather than predetermined.
The application offers several distinct voice agents, each designed to maintain a consistent personality throughout extended exchanges. These agents incorporate subtle vocal tics that signal cognitive processing rather than mechanical execution. Listeners notice deliberate pauses, strategic repetitions, and natural inflection shifts that mimic human thought patterns. The system does not simply output a finished paragraph; it constructs its answer in real time. This approach reduces the cognitive load on users who must parse dense, monolithic responses. Instead, they engage with a flowing narrative that evolves alongside their own input.
The practical implications of this technology extend beyond casual conversation into professional environments. Customer service platforms could benefit from agents that adapt their tone and pacing to match user frustration levels. Executive coaching tools might utilize these systems to simulate complex interpersonal scenarios with realistic emotional nuance. The technology essentially bridges the gap between static information retrieval and dynamic role-playing. Developers emphasize that the objective remains frictionless interaction rather than deceptive imitation. The focus stays on making the exchange feel intuitive while preserving the underlying mechanical reality.
As artificial intelligence continues to scale, the underlying infrastructure required to support these real-time vocal models grows increasingly complex. Recent industry developments, such as the Microsoft closed-loop cooling system for AI data centers, highlight the massive resource demands of continuous processing. Maintaining low-latency speech synthesis across millions of concurrent sessions requires substantial computational power and advanced thermal management. The environmental and economic costs of this infrastructure will shape how widely such conversational tools can be deployed.
Why does the human-like quality of AI matter?
The pursuit of vocal realism stems from a fundamental principle of human communication. People naturally adjust their speaking patterns to accommodate listeners who struggle to process information quickly. Synthetic voices that replicate this adaptive behavior can significantly reduce user fatigue during extended interactions. When a machine pauses to gather its thoughts or rephrases a complex idea, the listener experiences a sense of shared cognitive effort. This psychological alignment makes the technology feel more approachable and less intimidating. Users are more likely to trust systems that demonstrate active listening rather than rapid-fire data delivery.
However, the deliberate engineering of human-like vocal characteristics raises important design questions. Creators must decide how much authenticity is necessary before the interaction crosses into uncanny territory. The goal is to make the technology feel intuitive, not to convince users that they are speaking with a biological entity. Transparency remains the guiding principle for responsible development. Systems should clearly communicate their synthetic nature while still delivering a smooth conversational experience. Striking this balance requires careful calibration of vocal pacing, filler sounds, and response timing.
The psychological impact of highly realistic voice agents cannot be ignored. People naturally form social bonds with entities that exhibit consistent personality traits and emotional resonance. When an artificial system consistently mirrors human speech patterns, it can trigger genuine emotional responses. This phenomenon is particularly relevant in therapeutic or educational contexts where rapport directly influences outcomes. Developers must acknowledge that users may anthropomorphize these tools regardless of explicit disclaimers. The design philosophy should prioritize clarity and consent over maximum emotional immersion.
The hardware requirements for running these sophisticated models locally also drive innovation in peripheral computing. Enthusiasts and professionals are increasingly exploring high-performance external graphics enclosures for advanced computing tasks to offload intensive neural network processing. As conversational AI demands more real-time inference power, the boundary between cloud-based and local processing will continue to blur. This hardware evolution will determine how accessible and private future voice applications can become for everyday users.
Where does the line between utility and manipulation lie?
The ethical framework surrounding synthetic voice technology centers on the distinction between simulation and deception. A system can mimic human speech patterns without claiming human consciousness or intent. The critical factor is whether the design intentionally obscures its artificial nature to extract compliance or emotional investment. When voice agents use persuasive pacing or emotional tonality to influence decisions, the interaction shifts from helpful assistance to subtle behavioral engineering. This distinction becomes especially important in commercial applications where user trust directly impacts revenue.
Transparency protocols must evolve alongside the technology itself. Users need clear indicators that distinguish between genuine human conversation and algorithmic simulation. Current applications often rely on explicit disclaimers, but these notices can be easily overlooked during natural dialogue. Future systems might incorporate subtle auditory cues that signal synthetic operation without breaking immersion. The industry must establish standardized labeling practices that prevent confusion while preserving the functional benefits of realistic vocalization. Regulatory bodies are beginning to examine how synthetic media intersects with consumer protection laws.
The long-term consequences of widespread adoption require careful consideration. If conversational AI becomes indistinguishable from human dialogue, social dynamics could shift in unpredictable ways. People might prefer interacting with compliant, endlessly patient virtual agents over complex human relationships. This preference could reduce empathy development and alter how society handles conflict resolution. The technology itself remains neutral, but its application will define its cultural impact. Developers bear the responsibility of ensuring that convenience does not come at the cost of authentic human connection.
How will this technology reshape human-computer interaction?
The next generation of voice applications will likely prioritize contextual awareness and proactive assistance. Systems will learn individual communication preferences and adjust their vocal delivery accordingly. Users might experience personalized pacing, vocabulary selection, and emotional tone that match their current stress levels or cognitive load. This level of customization will make digital assistants feel like dedicated collaborators rather than generic tools. The shift from reactive commands to anticipatory dialogue will redefine how people manage daily tasks and professional workflows.
Integration with external data sources will further enhance the practical utility of these systems. Real-time information retrieval will allow voice agents to function as dynamic research assistants. Users could ask complex questions and receive continuously updated answers that incorporate breaking news, financial data, or scientific developments. The ability to pivot mid-conversation based on fresh information will make these tools indispensable for fast-paced industries. The boundary between searching and conversing will effectively disappear.
Educational and training applications will also undergo significant transformation. Simulated role-playing exercises will become more sophisticated, allowing students to practice difficult conversations with virtual mentors. These systems can provide immediate feedback on communication style, tone, and argument structure. The immersive nature of realistic voice interaction will accelerate skill acquisition in fields ranging from sales to healthcare. The technology will serve as a safe environment for practicing interpersonal skills before applying them in real-world scenarios.
The fundamental challenge will remain balancing advancement with ethical guardrails. As voice models grow more persuasive and emotionally resonant, the potential for misuse increases. Developers must implement robust verification systems to prevent deepfake audio generation and unauthorized impersonation. Security protocols will need to evolve alongside the generative capabilities themselves. The industry must establish clear boundaries that protect users while fostering innovation. Responsible development will determine whether this technology enhances human capability or erodes trust in digital communication.
Looking Ahead
The trajectory of artificial voice technology points toward increasingly seamless integration into daily life. The current generation of applications demonstrates that realistic conversation is no longer a futuristic concept but an active development phase. Users will benefit from more intuitive interfaces that reduce cognitive friction and improve information retrieval. At the same time, society must remain vigilant about the psychological and ethical implications of synthetic vocalization. The focus should remain on building tools that augment human understanding rather than replace authentic interaction. The future of digital communication depends on maintaining this delicate equilibrium between innovation and integrity.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)