The Ethics and Engineering of Hyper-Realistic AI Voice Interfaces
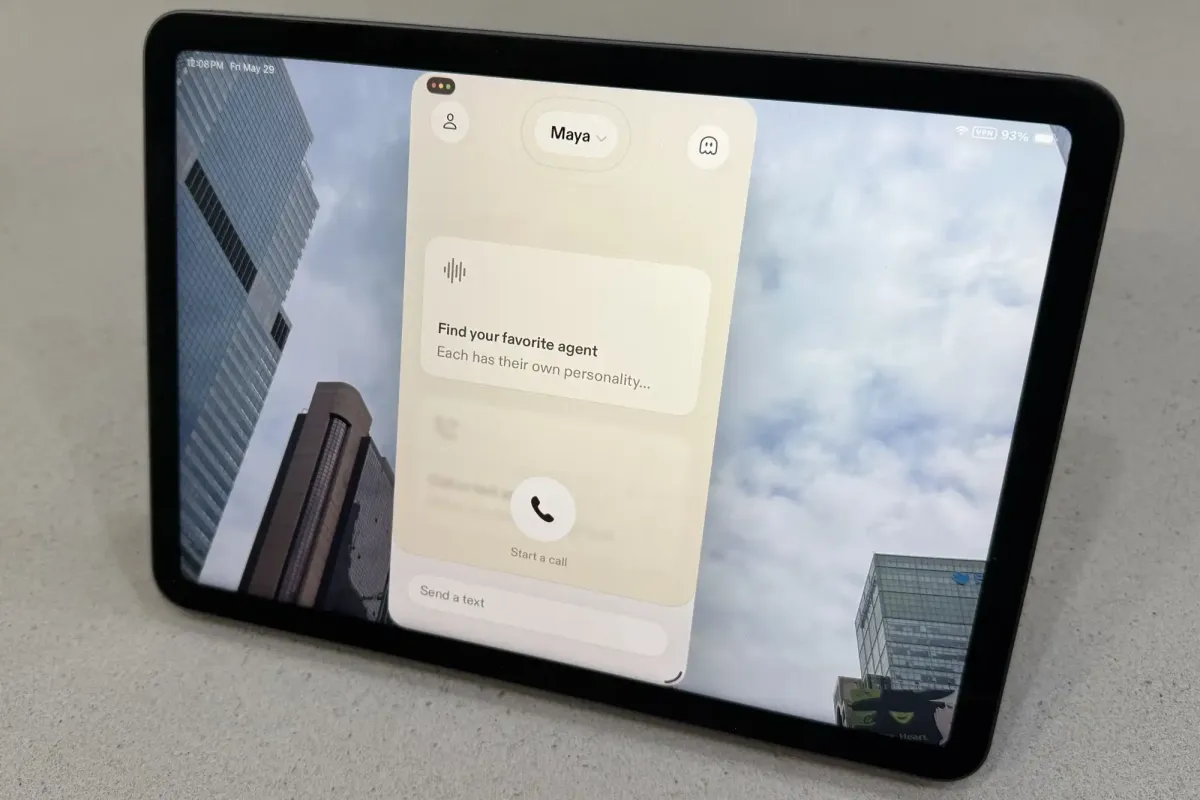
Sesame’s new iOS application delivers a remarkably human-like conversational experience by combining Google’s Gemma 4 language model with custom speech synthesis technology. The app performs real-time background searches while speaking, allowing for dynamic mid-conversation course corrections that eliminate the listening fatigue typical of traditional AI voice modes. This advancement raises critical questions about the ethical boundary between intuitive design and potential user manipulation as digital assistants become increasingly indistinguishable from human interlocutors.
The rapid evolution of artificial intelligence has consistently prioritized raw computational power over human-centric design, yet a quiet revolution is currently reshaping how users interact with digital systems. Recent developments in conversational voice technology suggest that the industry is finally addressing one of its most persistent flaws: the unnatural cadence of machine-generated speech. When an algorithm speaks with hesitation, filler words, and dynamic pacing, it bridges a psychological gap that flat text-to-speech engines have struggled to cross for decades. This shift demands careful examination of both the technical achievements and the underlying ethical considerations that accompany hyper-realistic digital personas.
Sesame’s new iOS application delivers a remarkably human-like conversational experience by combining Google’s Gemma 4 language model with custom speech synthesis technology. The app performs real-time background searches while speaking, allowing for dynamic mid-conversation course corrections that eliminate the listening fatigue typical of traditional AI voice modes. This advancement raises critical questions about the ethical boundary between intuitive design and potential user manipulation as digital assistants become increasingly indistinguishable from human interlocutors.
What is driving the shift toward conversational AI voice interfaces?
The trajectory of artificial intelligence development has consistently oscillated between maximizing processing efficiency and optimizing for human usability. Early voice assistants relied on rigid command structures that required users to adapt their language to machine expectations. As large language models matured, text-based interfaces became more sophisticated. Yet they still demanded active reading and cognitive engagement. Voice modes emerged as a solution to reduce friction, but early implementations suffered from severe limitations.
They typically processed queries in isolation, generated complete responses offline, and delivered them through synthetic voices that lacked natural prosody. The result was an experience that felt less like a dialogue and more like receiving a prepared monologue. Sesame represents a structural departure from this paradigm by integrating continuous inference with streaming audio generation. The application utilizes Google’s Gemma 4 foundation model alongside CSM-1B, a specialized conversational speech architecture designed to handle dynamic pacing.
This dual-model approach allows the system to process incoming queries while simultaneously generating audio output. It creates a feedback loop that mimics human cognitive processing. Users can observe background web searches occurring in real time. This visibility provides transparency into how the system gathers information without interrupting the vocal flow. The technical achievement here lies not merely in speech synthesis quality, but in the architectural decision to prioritize conversational continuity over response perfection.
By allowing the model to pivot mid-sentence when new data arrives, developers have effectively removed the latency barrier that previously made voice interactions feel disjointed and artificial. This engineering choice fundamentally alters how users perceive machine responsiveness. It shifts expectations toward systems that can adapt rather than simply recite. The industry must continue refining these architectures to support sustained multi-turn conversations without degrading accuracy.
Why does human-like vocalization matter in digital assistants?
Psychological research into human-computer interaction consistently demonstrates that auditory cues significantly influence trust and engagement levels. When a system speaks with predictable rhythm and flawless articulation, listeners subconsciously register it as non-human. This creates a psychological distance that can hinder collaboration. The introduction of calculated imperfections serves a functional purpose rather than merely adding decorative realism. Strategic pauses, breath sounds, and filler words like um or ah signal active processing time.
These markers give users a natural interval to formulate follow-up questions without feeling they are interrupting a machine. This phenomenon directly addresses the listening fatigue that frequently accompanies extended interactions with traditional AI voice modes. When an algorithm delivers lengthy, fully formed responses without conversational breathing room, cognitive load increases rapidly. The listener must constantly parse dense information streams while waiting for complete delivery.
Sesame’s approach deliberately incorporates these organic speech patterns to distribute mental effort more evenly across the interaction. The system does not attempt to hide its artificial nature behind polished perfection. Instead, it uses vocal hesitation as a pacing mechanism that aligns with human conversational norms. This design philosophy acknowledges that usability improvements often stem from embracing controlled imperfection rather than eliminating it entirely.
As voice models continue to refine their ability to replicate natural speech rhythms, the distinction between functional utility and psychological comfort will become increasingly intertwined. Developers must recognize that optimizing for human-like vocalization is not merely an aesthetic choice but a fundamental requirement for reducing cognitive friction in daily digital tasks. The industry must prioritize sustainable interaction patterns over short-term novelty.
How does real-time information retrieval change user expectations?
The integration of live web search capabilities into streaming voice interfaces represents a significant leap beyond static knowledge retrieval systems. Traditional AI assistants operate within constrained training datasets or rely on batch-processing search queries that introduce noticeable delays between question and answer. Sesame circumvents this limitation by executing multiple background searches while the audio output continues uninterrupted. Users can observe visual cues indicating active data gathering, which provides transparency without breaking conversational immersion.
This capability allows the system to correct course mid-sentence when fresh information contradicts initial assumptions or reveals more relevant alternatives. The practical implications for customer service, research assistance, and collaborative planning are substantial. When a digital agent can verify facts against current sources while maintaining vocal continuity, it transforms from a passive repository into an active problem-solving partner.
The ability to pivot dynamically based on live data reduces the likelihood of delivering outdated or inaccurate information. This reliability has historically undermined trust in automated assistants across multiple sectors. Users no longer need to wait for complete response generation before evaluating relevance. They can assess partial answers while the system continues working behind the scenes. Enterprise adoption of these conversational architectures will likely accelerate rapidly as latency barriers disappear.
Organizations seeking to deploy voice assistants for internal support or client-facing applications will prioritize systems that maintain contextual awareness across extended dialogues. The challenge lies in managing this increased complexity without overwhelming users with excessive data or contradictory findings. As voice interfaces become capable of handling multi-step reasoning alongside real-time verification, the baseline expectation for responsiveness will continue to rise across all software categories.
Where is the ethical boundary between intuitive design and manipulation?
The rapid improvement of conversational AI introduces profound questions regarding transparency, consent, and psychological influence. When a system successfully replicates human vocal patterns, pacing, and even emotional cadence, it inevitably triggers anthropomorphic responses in users who may not consciously recognize the artificial nature of the interaction. Sesame’s developers have explicitly addressed this tension by emphasizing that their goal is frictionless communication rather than deception.
The application maintains clear boundaries regarding its identity while utilizing human-like cues solely to improve usability and reduce cognitive load. This distinction highlights a critical ethical dilemma that extends beyond any single product. Systems optimized for maximum engagement may inadvertently exploit psychological vulnerabilities by mimicking empathy or urgency without actually possessing those qualities. Users might find themselves trusting recommendations from agents that sound convincingly human.
They remain unaware of the underlying algorithmic decision-making processes. The responsibility falls on developers to implement robust disclosure mechanisms that remain visible during interaction rather than buried in terms of service agreements. Regulatory bodies are beginning to examine synthetic media and voice cloning under existing consumer protection statutes. Future legislation will likely require explicit auditory or visual indicators whenever a system operates in conversational mode.
These mandates aim to prevent deceptive practices while preserving the utility of natural-sounding interfaces. Developers must anticipate compliance requirements during the design phase rather than retrofitting disclosures after launch. The industry standard for ethical voice AI will ultimately depend on consistent implementation across competing platforms. Transparency remains the only sustainable path forward for conversational technology development.
Conclusion on Future Adaptation
The convergence of advanced language models, dynamic speech synthesis, and real-time data retrieval is fundamentally restructuring how humans interact with digital systems. Sesame demonstrates that technical capability alone does not guarantee positive user outcomes. The architectural choices surrounding transparency and pacing determine whether these tools enhance productivity or erode critical thinking.
As voice interfaces continue to close the gap between machine output and human conversation, developers will face increasing pressure to balance usability with ethical responsibility. Users must approach these systems with informed skepticism. They should recognize that natural-sounding dialogue does not equate to genuine understanding or unbiased judgment. The future of conversational AI depends less on achieving perfect vocal realism and more on establishing clear boundaries that protect user autonomy while delivering practical utility.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.









Comments (0)