The Ethics and Engineering Behind Hyper-Realistic AI Voice Interfaces
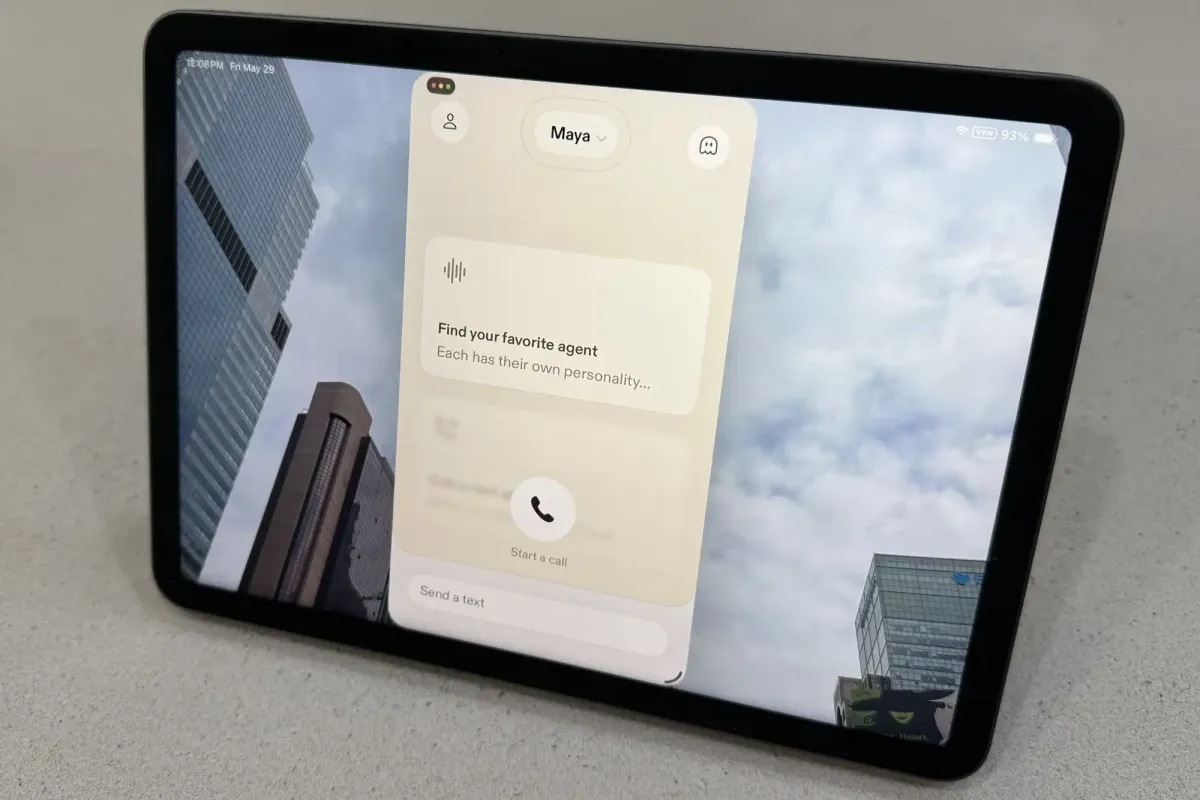
PCWorld’s reporter tested Sesame’s new AI voice app and found it delivers the most human-like conversational experience available, using Google’s Gemma 4 LLM and custom speech models. The app performs real-time web searches while speaking and offers more natural dialogue flow compared to current AI voice modes that feel like lectures. This advanced conversational AI raises ethical concerns about the fine line between intuitive design and potential user manipulation through human-like interactions.
The evolution of artificial intelligence has consistently moved toward reducing friction between human intent and machine execution. Voice interfaces represent the most direct pathway to this goal, yet achieving genuine conversational fluidity remains a complex engineering challenge. Recent developments in generative speech models are beginning to bridge that gap, transforming how users interact with digital assistants on a daily basis.
PCWorld’s reporter tested Sesame’s new AI voice app and found it delivers the most human-like conversational experience available, using Google’s Gemma 4 LLM and custom speech models. The app performs real-time web searches while speaking and offers more natural dialogue flow compared to current AI voice modes that feel like lectures. This advanced conversational AI raises ethical concerns about the fine line between intuitive design and potential user manipulation through human-like interactions.
What is Driving the Shift Toward Natural Voice Interfaces?
For years, digital assistants relied on rigid command structures and predictable response patterns to function reliably. Users quickly adapted to treating these systems as transactional tools rather than conversational partners. The limitation became apparent when voice outputs lacked the organic cadence of human speech, often delivering lengthy monologues that felt disconnected from immediate context. Developers recognized that true utility requires more than accurate information retrieval; it demands contextual awareness and adaptive pacing.
Modern large language models have begun addressing these shortcomings by integrating specialized conversational speech architectures. Sesame represents a notable step in this direction, combining Google’s Gemma 4 foundation with a custom CSM-1B model designed specifically for dialogue flow. This technical pairing allows the system to generate responses that adapt dynamically rather than following predetermined script templates. The result is an interface that responds to user input with measurable flexibility and reduced latency.
The industry has spent considerable resources refining how machines process spoken language and synthesize vocal output. Early iterations struggled with unnatural pauses, abrupt tonal shifts, and repetitive phrasing that broke immersion during extended conversations. Recent advancements in neural speech synthesis have significantly improved prosody, intonation, and rhythmic variation. These improvements enable voice agents to mimic conversational behaviors like thoughtful hesitation or mid-sentence course correction without compromising clarity or accuracy.
How Does Real-Time Search Alter Conversational Dynamics?
Traditional voice assistants typically complete their internal processing before delivering a final response, creating noticeable delays that interrupt natural dialogue. Sesame introduces a different approach by conducting multiple background web searches while the agent continues speaking. This architectural choice fundamentally changes how information is gathered and presented during an interaction. Users experience continuous flow rather than waiting for isolated data retrieval cycles to finish.
The ability to pull fresh information mid-conversation allows the system to adjust its answers based on newly available context. If a user asks about local dining options, the agent can simultaneously query location data, review aggregators, and cross-reference operating hours without breaking vocal continuity. This parallel processing capability reduces the perception of computational delay while maintaining contextual relevance throughout the exchange.
Real-time search integration also enables more nuanced follow-up questions that reflect evolving user interests. Instead of delivering a static list of recommendations, the voice agent can pivot toward specific preferences as new details emerge during the dialogue. This dynamic adaptation mirrors how human experts approach complex queries, gathering additional information to refine their guidance rather than relying solely on initial prompts.
The Mechanics of Adaptive Dialogue
Implementing continuous search while maintaining vocal output requires sophisticated synchronization between language processing and speech synthesis engines. Developers must balance computational load with audio rendering speed to prevent stuttering or desynchronization. When executed correctly, the system creates an impression of active listening rather than mechanical execution. This distinction profoundly impacts user comfort during extended interactions.
The technical infrastructure supporting this functionality relies on streaming architectures that process incoming queries and outgoing responses simultaneously. Data packets from web sources are evaluated in real time, allowing the model to incorporate fresh facts without halting vocal generation. Engineers have optimized these pipelines to prioritize low-latency updates while preserving grammatical coherence across shifting topics.
The Architecture of Human-Like Interaction
Achieving authentic conversational quality requires more than accurate information delivery; it demands careful calibration of vocal characteristics and behavioral patterns. Sesame offers multiple voice agents, each designed with distinct tonal profiles to accommodate different user preferences. These voices incorporate deliberate pauses, filler sounds, and rhythmic variations that signal active processing rather than robotic recitation.
The inclusion of conversational markers like thoughtful hesitations serves a specific psychological function during human-machine interaction. These subtle cues help users interpret the system as engaged in genuine reasoning rather than instantly retrieving stored responses. When deployed appropriately, such features reduce cognitive load by signaling that the agent is evaluating context before formulating its next statement.
Designing these vocal behaviors requires balancing authenticity with transparency. Engineers must ensure that human-like qualities enhance usability without crossing into deceptive territory. The goal remains creating frictionless communication pathways while maintaining clear boundaries between simulated behavior and actual consciousness. Users should always understand they are interacting with sophisticated software rather than an autonomous entity.
Why Does Ethical Transparency Matter in Conversational AI?
As voice interfaces become increasingly indistinguishable from human conversation, the ethical implications of anthropomorphic design grow more significant. Systems that mimic emotional nuance and conversational rhythm can inadvertently trigger psychological attachment or misplaced trust. Users may begin attributing genuine understanding or personal experience to algorithms that only process statistical patterns in language data.
The distinction between intuitive design and manipulative engineering becomes particularly relevant when voice agents simulate empathy or personalized concern. Developers face the challenge of creating comfortable interactions while preventing users from forming unrealistic expectations about machine capabilities. Clear communication about system limitations remains essential for maintaining informed user relationships over time.
Industry standards are gradually evolving to address these concerns through standardized disclosure practices and behavioral guidelines. Responsible implementation requires ongoing evaluation of how vocal characteristics influence user perception and decision-making. Transparency frameworks help ensure that technological advancement does not outpace ethical consideration, preserving user autonomy in increasingly immersive digital environments.
The Trajectory of Agent Capabilities
Current voice applications represent only the initial phase of broader agent development initiatives. Roadmaps across the industry point toward systems capable of executing complex tasks rather than merely discussing them. Future iterations will likely integrate deeper environmental awareness, allowing agents to interact with smart home ecosystems, calendar networks, and professional software suites simultaneously.
The expansion into active task execution introduces new technical requirements for security verification and permission management. Agents must navigate user authorization protocols while maintaining conversational fluidity during multi-step processes. Engineers are developing secure handoff mechanisms that allow voice interfaces to trigger external actions without breaking dialogue continuity or compromising data privacy.
Practical applications will emerge across customer service, executive training, and therapeutic simulation domains. Simulated role-playing environments can provide safe spaces for practicing difficult conversations or refining communication strategies. These use cases demonstrate how advanced conversational AI could supplement rather than replace human expertise in specialized professional contexts.
Navigating the Future of Voice Technology
The rapid advancement of voice-based artificial intelligence demands careful navigation between technological capability and responsible deployment. Users benefit from increasingly fluid interactions, yet the industry must establish robust frameworks for transparency and ethical design. Adapting to this shift requires ongoing dialogue between developers, researchers, and consumers about how these tools should function in daily life.
The focus must remain on enhancing human agency rather than obscuring machine limitations through sophisticated simulation. As conversational models grow more capable, regulatory bodies and technology companies will need to collaborate on establishing clear usage boundaries. Sustainable progress depends on prioritizing user understanding alongside technical innovation in every subsequent development cycle.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)