The Ethical Threshold of Human-Like AI Voice Interfaces
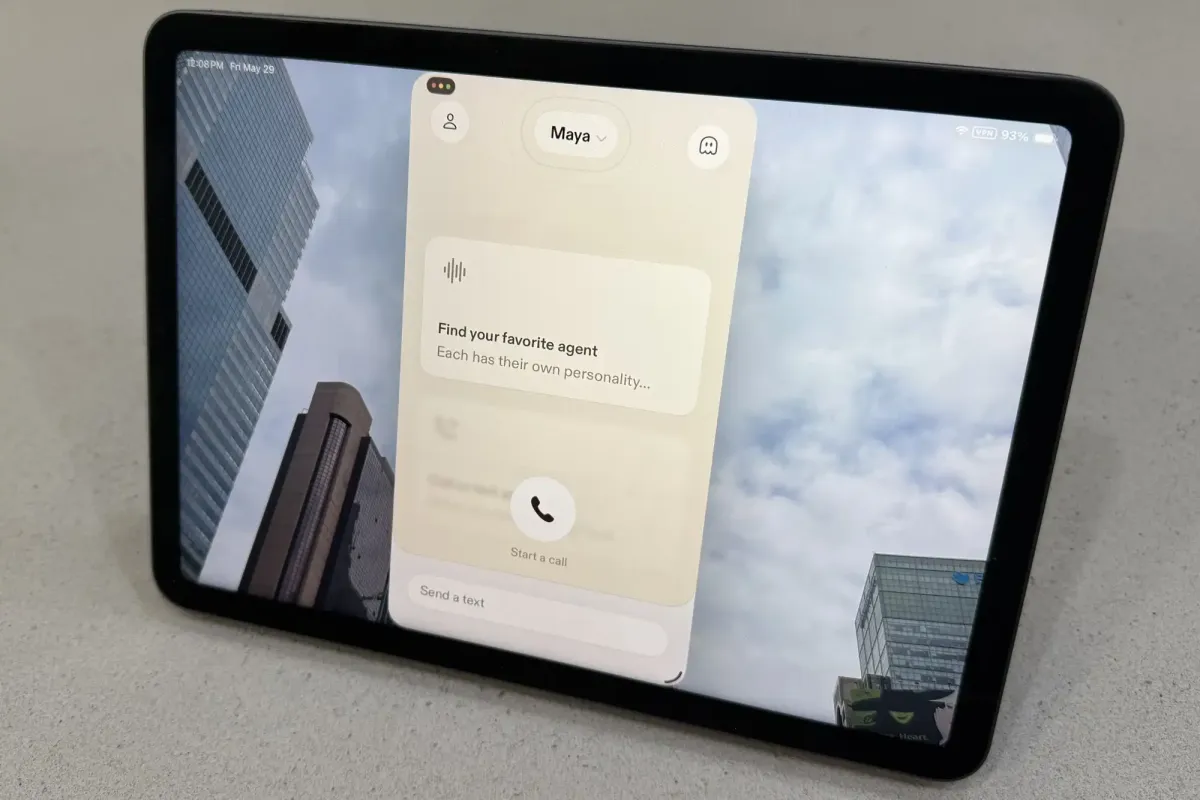
Sesame’s newly released iOS application delivers a remarkably human-like conversational experience by leveraging Google’s Gemma 4 large language model alongside custom speech architecture. The system conducts real-time web searches during dialogue, enabling fluid topic shifts and reducing conversational latency. While the technology offers significant utility for customer service and collaborative tasks, its advanced realism prompts necessary discussions about transparency, ethical design boundaries, and the long-term implications of human-mimicking artificial intelligence interfaces.
The rapid evolution of artificial intelligence has quietly shifted from text-based prompts to fluid vocal exchanges, fundamentally altering how users interact with digital assistants. Recent developments in conversational voice technology demonstrate a marked departure from rigid command-and-response paradigms toward dynamic, context-aware dialogue systems that process information while speaking. This transition introduces unprecedented convenience but simultaneously raises complex questions regarding design ethics and user autonomy. As these systems grow increasingly sophisticated, the boundary between intuitive assistance and psychological manipulation becomes progressively thinner.
Sesame’s newly released iOS application delivers a remarkably human-like conversational experience by leveraging Google’s Gemma 4 large language model alongside custom speech architecture. The system conducts real-time web searches during dialogue, enabling fluid topic shifts and reducing conversational latency. While the technology offers significant utility for customer service and collaborative tasks, its advanced realism prompts necessary discussions about transparency, ethical design boundaries, and the long-term implications of human-mimicking artificial intelligence interfaces.
What is the architectural shift in modern AI voice interfaces?
Modern conversational artificial intelligence has moved beyond static text generation into dynamic audio processing environments. Previous iterations of voice-enabled assistants primarily functioned as delayed readers, converting lengthy written outputs into synthesized speech after computation completed entirely. This sequential approach created noticeable latency and stripped the interaction of natural pacing. Contemporary systems now integrate language model inference directly with continuous speech synthesis pipelines.
The latest generation of these applications utilizes specialized conversational speech models alongside foundational large language architectures. By combining Google’s Gemma 4 framework with custom-built acoustic processing layers, developers can generate vocal responses that adapt to incoming queries in real time. This dual-processing capability allows the system to maintain audio output while simultaneously evaluating new data streams or executing background operations.
Real-time web searching represents a critical advancement within this architecture. Traditional voice assistants typically halt speech generation to fetch external information, resulting in awkward silences that break conversational immersion. Advanced implementations now route search queries through parallel processing threads while the vocal engine continues producing phonemes. This architectural design enables the system to pivot mid-sentence when new contextual data emerges during a query.
The user interface reflects these technical capabilities through multiple distinct voice agents, each calibrated for specific interaction styles. Developers have engineered variations that adjust pacing, tonal range, and conversational warmth to suit different use cases. Some configurations prioritize rapid information retrieval, while others emphasize collaborative dialogue patterns that mimic professional coaching or creative brainstorming sessions.
Underlying telemetry displays provide users with visibility into these background processes. Applications now frequently render visual indicators showing active search operations, data parsing stages, and response formulation progress. This transparency helps bridge the gap between opaque computational workflows and user expectations for immediate feedback.
Why does conversational latency matter for user experience?
The psychological impact of response timing fundamentally shapes how humans perceive artificial intelligence systems. When digital assistants deliver fully formed paragraphs after extended processing delays, listeners often interpret the output as a formal lecture rather than an interactive exchange. This structural rigidity creates cognitive friction that diminishes engagement over prolonged usage periods.
Conversely, systems capable of generating speech while simultaneously processing information produce a markedly different psychological effect. The continuous audio stream maintains conversational momentum and signals active listening to the user. Listeners perceive these interactions as collaborative rather than instructional, which significantly reduces mental fatigue during complex queries or extended discussions.
Vocal pacing mechanisms play an equally crucial role in shaping perceived authenticity. Modern speech synthesis engines incorporate deliberate pauses, filler sounds, and tonal variations that mirror natural human communication patterns. These micro-adjustments prevent the robotic monotony that historically plagued automated voice interfaces. The strategic placement of brief hesitations allows listeners to process information while simultaneously signaling that the system is still computing a response.
Dialogue flow optimization also addresses the structural limitations of traditional large language models. Earlier text-based outputs often followed rigid paragraph structures that translated poorly into spoken format. Current architectures prioritize conversational topology over linear exposition, enabling sentences to loop back, pivot toward new information, or acknowledge contradictory data without breaking audio continuity.
This fluidity transforms routine queries into dynamic exchanges where both parties adapt in real time. Users no longer need to wait for complete responses before formulating follow-up questions. The system can adjust its trajectory based on partial input, creating an environment that closely resembles human-to-human problem solving rather than database retrieval.
How do synthetic vocal tics influence human trust and manipulation?
The deliberate engineering of human-like vocal characteristics introduces profound ethical considerations for interface designers. When artificial systems replicate natural speech patterns with high fidelity, users frequently experience subconscious emotional responses that blur the line between tool and companion. This psychological phenomenon stems from evolutionary mechanisms that prioritize vocal cues as indicators of social intent.
Designers must navigate a narrow pathway between intuitive usability and deceptive presentation. Systems that utilize conversational filler sounds and adaptive pacing achieve remarkable engagement metrics, yet they simultaneously risk fostering unwarranted anthropomorphism. Users may unconsciously attribute genuine understanding or emotional depth to algorithms that merely simulate these qualities through statistical modeling.
The tension becomes particularly evident when discussing applications like executive coaching or therapeutic training simulations. These use cases demand high levels of user trust and psychological safety, which synthetic voices can artificially generate through calibrated vocal warmth. While this capability enhances practical utility, it also raises questions about informed consent regarding the artificial nature of the interaction.
Industry stakeholders increasingly recognize that transparency must remain foundational to voice interface development. Clear communication about computational processes helps maintain appropriate user expectations without sacrificing conversational fluidity. Regulatory frameworks addressing digital infrastructure and privacy continue evolving alongside these technological capabilities, as seen in recent policy discussions surrounding national artificial intelligence deployment strategies. Canada Unveils AI for All Strategy Amid Infrastructure and Privacy Debates illustrates how governments are beginning to map regulatory boundaries around synthetic media and automated interaction systems.
The distinction between sounding human and pretending to be one requires careful architectural implementation. Ethical design prioritizes frictionless interaction over emotional deception, ensuring that vocal realism serves functional purposes rather than psychological manipulation. Developers face ongoing pressure to establish industry standards that prevent voice synthesis from crossing into deceptive territory while preserving the usability benefits of natural pacing.
What are the long-term implications for human-computer interaction?
The rapid advancement of conversational voice technology signals a fundamental restructuring of how humans access information and execute digital tasks. As computational efficiency improves and speech synthesis models grow more sophisticated, the distinction between text-based and audio interfaces will continue to diminish. Users will increasingly expect seamless transitions between reading and listening without sacrificing contextual accuracy or response speed.
Safety assurances from technology providers must evolve alongside capability improvements. Current development cycles prioritize functional performance over comprehensive ethical auditing, creating a gap between marketing narratives and actual system behavior. Independent researchers and regulatory bodies will need to establish standardized evaluation metrics that measure both technical proficiency and psychological impact across diverse user demographics.
The competitive landscape will accelerate innovation as multiple developers race to replicate successful conversational architectures. Each new iteration will likely push vocal realism further, potentially outpacing existing ethical guidelines and user adaptation mechanisms. Organizations deploying these systems must anticipate scenarios where highly persuasive synthetic voices could influence decision-making processes in ways that bypass critical analytical thinking.
Practical implementation strategies should focus on hybrid interaction models that combine voice fluidity with explicit system identification markers. Users require consistent feedback regarding computational status, data usage boundaries, and artificial origin without experiencing constant interruptions to conversational flow. Training programs for corporate and educational environments will need to address digital literacy concerns specific to advanced vocal interfaces.
The trajectory of this technology suggests that future interactions will prioritize contextual awareness over command execution. Systems will anticipate user needs by analyzing speech patterns, historical queries, and environmental data simultaneously. This evolution demands rigorous oversight to ensure that convenience never supersedes user autonomy or psychological well-being in automated interaction design.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)