Evaluating Sesame AI Voice App: Natural Speech and Ethical Boundaries
Sesame has released a free iOS application that delivers highly natural conversational audio by combining Google’s Gemma 4 LLM with a custom speech model. The system performs background web searches while speaking, creating fluid dialogue rather than static broadcasts. This advancement prompts necessary discussion regarding transparency, user manipulation risks, and the future of ethical voice AI deployment across mobile platforms.
The rapid evolution of conversational artificial intelligence has fundamentally altered how users interact with digital assistants across mobile platforms. Recent developments in voice synthesis and large language model integration have moved beyond simple command execution toward continuous, dynamic dialogue. A newly released iOS application from the developer Sesame demonstrates a significant leap in this trajectory by delivering highly natural speech patterns combined with real-time information retrieval capabilities. This advancement forces a necessary examination of how human-like vocalization impacts user trust, cognitive engagement, and broader ethical standards within the technology sector.
Sesame has released a free iOS application that delivers highly natural conversational audio by combining Google’s Gemma 4 LLM with a custom speech model. The system performs background web searches while speaking, creating fluid dialogue rather than static broadcasts. This advancement prompts necessary discussion regarding transparency, user manipulation risks, and the future of ethical voice AI deployment across mobile platforms.
What is driving the shift toward human-like AI voice interfaces?
Traditional voice assistants have long relied on rigid command-and-response frameworks that prioritize speed over conversational fluidity. Modern large language models now generate responses at unprecedented scales, yet early implementations often produced monotonous outputs that felt more like automated broadcasts than genuine exchanges. The introduction of specialized speech synthesis architectures addresses this limitation by incorporating natural vocal cadence, strategic pauses, and contextual hesitation markers. Developers recognize that frictionless communication requires mimicking the organic rhythm of human dialogue rather than forcing structured data delivery into artificial audio formats.
Sesame utilizes Google’s Gemma 4 LLM alongside a custom conversational speech model designated as CSM-1B to achieve this balance. The underlying architecture processes user input through multiple neural layers before generating synchronized vocal output that adapts dynamically to conversation flow. Unlike earlier systems that delivered fully formed responses without intermediate processing, this approach allows the application to formulate answers while simultaneously conducting background web searches. Users receive continuous auditory feedback rather than enduring prolonged silence during complex query resolution. This technical foundation establishes a new baseline for conversational responsiveness across mobile environments.
The industry has gradually recognized that user retention depends heavily on interaction comfort and perceived responsiveness. Early voice interfaces suffered from high abandonment rates when users encountered robotic pacing or abrupt topic termination. By implementing dynamic speech modeling, developers can maintain engagement during extended queries without triggering cognitive fatigue. This shift represents a fundamental recalibration of interface design priorities, moving away from raw processing speed toward nuanced auditory delivery. The resulting systems feel less like computational tools and more like collaborative partners.
How does real-time contextual awareness alter user experience?
The integration of location-based services and live information retrieval transforms passive listening into active collaboration. When users request dining recommendations or entertainment schedules, the application cross-references geographic data with current listings to provide highly specific suggestions. Interface elements display processing indicators that reveal background search operations without interrupting the spoken dialogue. This transparency helps users understand how the system gathers information while maintaining conversational momentum. The result is an interaction model where auditory and visual feedback loops operate in parallel rather than sequentially.
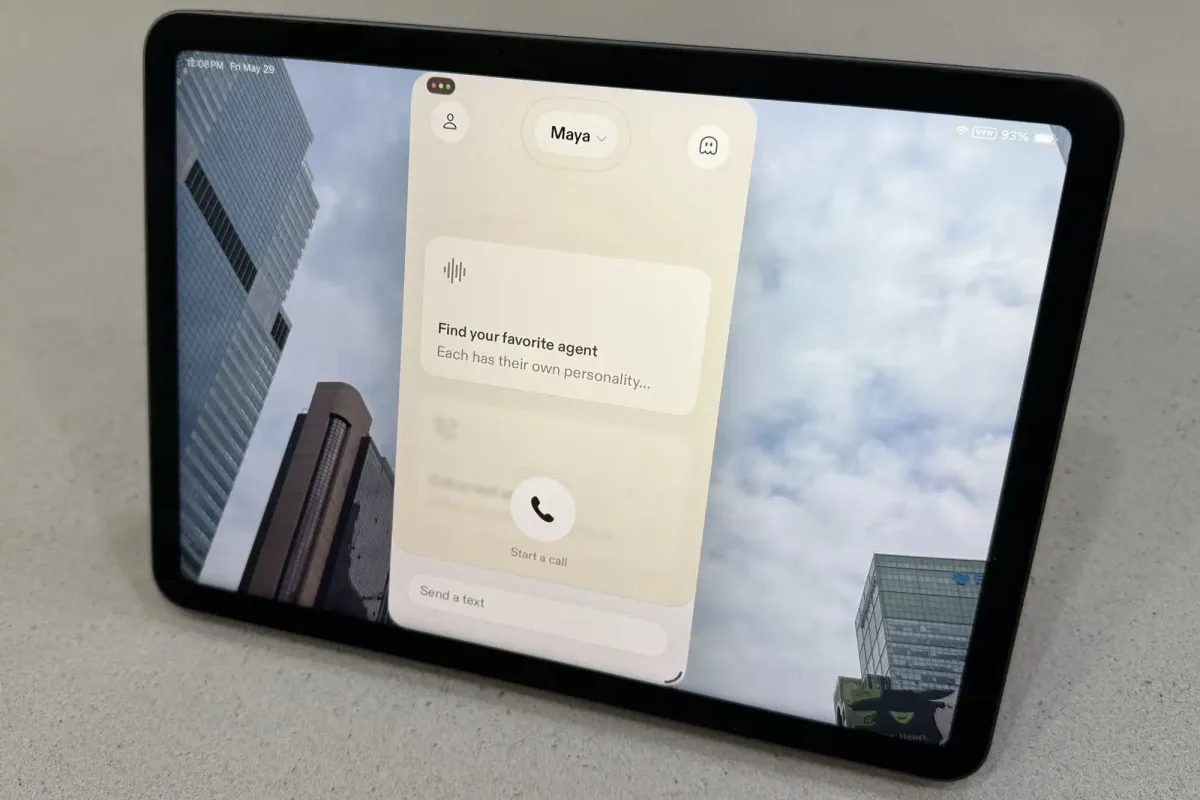
Multiple voice agents within the application offer distinct tonal characteristics and conversational styles to accommodate different user preferences. Each agent maintains consistent personality markers while adapting responses to match the specific context of the discussion. The system avoids overly aggressive questioning patterns that characterized earlier beta versions, instead focusing on collaborative dialogue structures that prioritize clarity over novelty. Users can navigate between different vocal profiles without experiencing jarring transitions in tone or pacing. This modular approach allows developers to refine individual agent behaviors independently while preserving a unified core architecture.
Real-time contextual processing also reduces the cognitive load required from users during complex information gathering tasks. Instead of manually verifying search results across multiple applications, individuals can receive synthesized recommendations delivered through natural speech patterns. This capability aligns with broader industry trends toward ambient computing and hands-free digital assistance. Companies like Apple are simultaneously exploring similar integration pathways through Apple's new voice control initiatives. The convergence of these efforts suggests a market moving toward seamless, context-aware auditory interfaces.
Why does natural vocalization raise ethical considerations?
The pursuit of indistinguishable human speech introduces complex questions regarding transparency and user manipulation. When artificial voices replicate subtle vocal tics, conversational pivots, and emotional resonance, users may unconsciously attribute genuine understanding or intent to the system. This psychological effect can blur the boundary between intuitive design and deceptive interface patterns. Developers must carefully calibrate how closely an application mimics human communication without implying capabilities it does not possess. The industry faces mounting pressure to establish clear standards for disclosing artificial origins in conversational interfaces.
Ethical frameworks surrounding voice AI emphasize the necessity of maintaining explicit boundaries between simulation and reality. Applications that achieve remarkable vocal fidelity risk fostering unwarranted emotional attachment or misplaced trust in automated decision-making processes. Responsible deployment requires implementing consistent disclosure mechanisms that remind users they are interacting with algorithmic systems rather than human operators. Transparency must extend beyond initial onboarding screens to remain visible throughout extended conversations. The technology sector must collectively address how artificial empathy influences consumer behavior and digital literacy standards across diverse demographics.
Regulatory bodies worldwide are beginning to draft guidelines specifically addressing synthetic media authenticity and conversational AI disclosure requirements. These frameworks aim to prevent malicious actors from exploiting vocal mimicry for fraud or psychological manipulation. Ethical developers prioritize user autonomy by ensuring that artificial agents never claim human identity or independent consciousness. The tension between creating intuitive interfaces and maintaining honest system representation remains a central challenge. Addressing this balance requires ongoing collaboration between engineers, ethicists, and policy makers to establish sustainable operational standards.
What are the practical limitations and future trajectories of this technology?
Current iterations of voice-focused applications face inherent constraints regarding file handling, transcript generation, and cross-platform synchronization. Users cannot attach external documents to conversations or retrieve verbatim records of completed exchanges without navigating away from the primary interface. These restrictions stem from architectural priorities that emphasize real-time audio processing over comprehensive data logging. Developers acknowledge these gaps while outlining roadmaps that promise expanded functionality through next-generation agent frameworks. The transition from conversational simulation to task execution represents a critical milestone for the platform.
Future developments will likely integrate voice capabilities with emerging hardware ecosystems and specialized computing environments. Industry observers note that seamless audio processing across wearable devices and mobile operating systems requires substantial infrastructure investment. Companies are exploring how intelligent eyewear and spatial computing interfaces can complement auditory interactions without overwhelming users with excessive feedback loops. These advancements depend heavily on optimizing neural network efficiency while maintaining low latency requirements for natural dialogue. The competitive landscape will increasingly reward developers who balance technical capability with responsible user experience design.
The broader implications of this technological shift extend beyond individual applications to influence regulatory approaches and consumer protection standards. As voice synthesis becomes more sophisticated, policymakers must evaluate how artificial communication impacts digital rights and information authenticity. Organizations that prioritize transparent development practices will likely establish stronger market positioning than those relying on psychological manipulation tactics. Users benefit from clear guidelines that define acceptable boundaries for conversational AI deployment across commercial and public sectors. The industry must collectively navigate these challenges to ensure sustainable innovation without compromising fundamental user autonomy.
Adapting to this new paradigm requires continuous education regarding the capabilities and limitations of modern speech synthesis systems. Users who understand how background processing, large language models, and audio generation interact can make more informed decisions about digital tool selection. Developers must remain accountable for implementing safeguards that prevent excessive anthropomorphism while preserving functional utility. The technology sector faces a critical juncture where ethical considerations must guide architectural decisions rather than follow them as afterthoughts. Establishing clear operational boundaries will determine how successfully these systems integrate into daily workflows and personal communication habits.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)