Siri AI Introduces Customizable Voice Expressiveness and Pacing
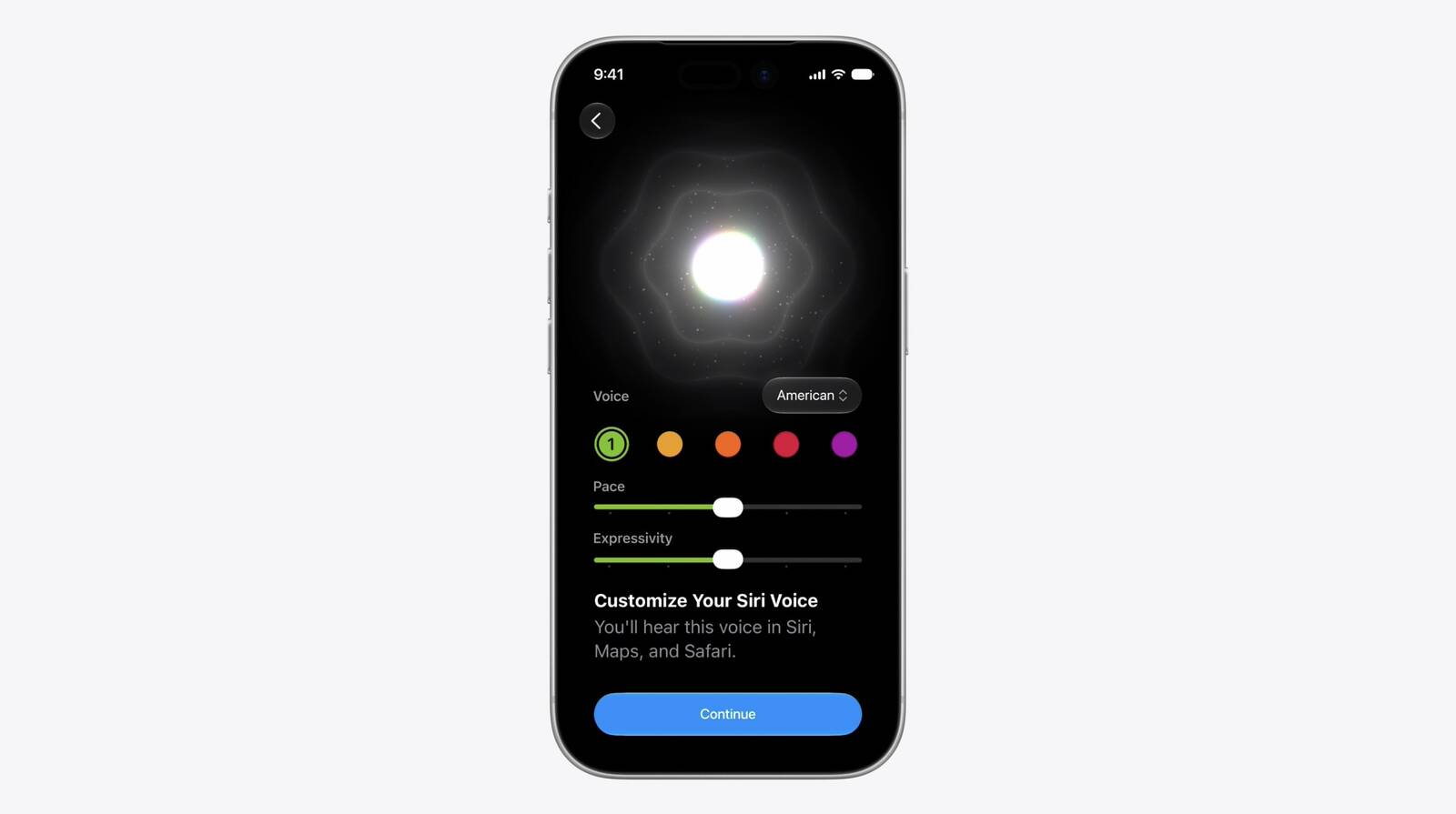
Apple has introduced adjustable voice expressiveness and pacing controls for Siri AI, enabling users to tailor vocal output through a dedicated interface. The update also enhances systemwide dictation accuracy by processing speech directly on compatible hardware, ensuring faster response times and improved transcription reliability across supported devices.
Voice interaction has long served as the primary bridge between human intent and digital execution. The latest iteration of Apple's virtual assistant introduces a refined approach to vocal customization that prioritizes user comfort and contextual clarity. This development marks a deliberate shift toward adaptive audio profiles that respond to individual listening preferences rather than relying on static system defaults.
Apple has introduced adjustable voice expressiveness and pacing controls for Siri AI, enabling users to tailor vocal output through a dedicated interface. The update also enhances systemwide dictation accuracy by processing speech directly on compatible hardware, ensuring faster response times and improved transcription reliability across supported devices.
What is the technical foundation behind the new voice customization features?
The underlying architecture relies heavily on Apple Silicon processors to handle complex audio synthesis without routing data through external servers. This on-device methodology ensures that vocal adjustments remain entirely local, preserving user privacy while reducing latency during interactive sessions. Previous iterations required cloud-based rendering for advanced vocal modulation, which introduced noticeable delays and raised data retention concerns. The current implementation leverages dedicated neural processing units to generate dynamic vocal patterns in real time.
Users can now manipulate expressiveness and pacing through intuitive slider controls that adjust pitch, rhythm, and tonal variation. These adjustments do not alter the fundamental language model but rather modify the output layer that converts text to audio. The system continuously learns from individual preferences to maintain consistency across different applications and operating environments. This approach aligns with broader industry trends toward localized artificial intelligence processing, where computational efficiency and user control take precedence over centralized server infrastructure.
The implementation of neural processing units allows the device to generate complex vocal patterns without relying on external servers. This architectural choice significantly reduces the time required to convert text into audible speech. Users experience near-instantaneous responses even when adjusting vocal parameters mid-conversation. The local processing model also ensures that voice customization remains functional during periods of limited network connectivity. This capability proves essential for travelers and professionals who frequently operate in environments with unstable internet access. The technology demonstrates how hardware optimization can directly enhance software functionality.
Why does adjustable vocal pacing matter for everyday computing?
Adjustable vocal pacing directly impacts how users process auditory information during complex tasks. When individuals can slow down or accelerate speech output, they gain greater control over information intake without interrupting their workflow. This capability proves particularly valuable for professionals managing multiple applications simultaneously or users navigating dense technical documentation. Static voice speeds often force listeners to adapt their cognitive processing to the machine, rather than allowing the machine to adapt to human preferences. The new slider interface removes this friction by providing granular control over delivery speed. Users can match the vocal output to their current environment, whether they are in a quiet office or a bustling public space. This flexibility reduces mental fatigue during extended interaction sessions and improves overall comprehension accuracy.
The pacing adjustments also intersect with broader accessibility standards that prioritize inclusive design principles. Individuals with auditory processing differences or specific learning preferences benefit significantly from customizable speech rates. By allowing users to fine-tune delivery speed, the system accommodates a wider range of neurological and cognitive profiles. This shift moves voice assistants away from a one-size-fits-all model toward a more personalized computing experience. The technology also supports users who rely on auditory feedback for navigation, scheduling, and information retrieval. When speech output matches individual comfort levels, interaction becomes more intuitive and less taxing. The industry has gradually recognized that vocal customization is not merely a convenience feature but a fundamental requirement for modern digital interfaces.
Early testing during the developer beta phase has revealed how the new interface handles rapid parameter adjustments. Users report that the slider controls respond immediately to input, allowing for precise calibration of vocal output. The system retains these preferences across reboots and application switches, ensuring a consistent listening experience. Developers have noted that the underlying code structure supports future expansions to additional vocal characteristics. This modular design enables Apple to introduce new customization options without requiring major system updates. The beta testing process also helps identify potential edge cases where voice synthesis might struggle with complex linguistic structures.
How does the updated dictation engine improve systemwide text input?
The updated dictation engine captures spoken language and transforms it into polished text without requiring manual editing. Automatic capitalization, punctuation, and formatting occur in real time, which significantly reduces the friction traditionally associated with voice-to-text workflows. Users can now speak naturally without worrying about grammatical structure or typographical conventions. The system interprets conversational phrasing and converts it into properly formatted written content. This capability proves especially useful for drafting emails, composing messages, and annotating documents during active work sessions. The improved speech understanding module processes linguistic patterns more accurately, allowing it to distinguish between homophones and contextual meanings with greater precision.
Reliability in transcription directly impacts user trust in voice input as a primary writing method. When the system consistently delivers accurate results, individuals are more likely to rely on speech for routine tasks. The enhanced engine reduces the need for constant corrections, which historically discouraged widespread adoption of voice typing. Apple has optimized the underlying algorithms to handle regional accents, technical terminology, and rapid speech patterns without compromising output quality. This improvement extends across all supported applications, creating a unified experience that functions seamlessly regardless of the active software environment. The technology also minimizes background noise interference, ensuring that dictation remains functional in less than ideal acoustic conditions.
The integration of advanced dictation capabilities transforms how professionals approach document creation and communication. Writers, developers, and researchers can now capture ideas immediately without interrupting their creative flow. The system automatically structures spoken thoughts into coherent paragraphs, reducing the time spent on manual editing. This efficiency gain becomes particularly noticeable during brainstorming sessions or rapid note-taking scenarios. Users can dictate complex technical specifications or legal terminology with greater confidence. The improved accuracy also minimizes the frustration associated with misinterpreted commands. As voice input becomes more reliable, it will likely replace keyboard typing for a significant portion of daily digital interactions.
What are the hardware requirements and platform limitations for this update?
Access to the most advanced on-device processing capabilities depends on specific hardware configurations that meet Apple Intelligence standards. Only the latest generation of smartphones and computers can run the required neural processing workloads efficiently. Older devices lack the necessary computational capacity to handle real-time voice synthesis and dictation optimization without relying on cloud servers. The feature is currently available in the initial developer beta for iOS 27 and macOS 27 developer betas. Early testing indicates that the implementation requires substantial storage allocation and background processing power. Users who upgrade to the new operating systems should verify their device compatibility before expecting full functionality.
Regional availability also plays a significant role in feature distribution due to regulatory frameworks governing artificial intelligence services. Certain jurisdictions have imposed strict data processing requirements that delay the rollout of advanced voice capabilities. The European Union has implemented regulations that require careful evaluation of how user data is handled during AI interactions. Apple has acknowledged these compliance challenges and is working to align the feature distribution with local legal standards. This means that some users may experience delayed access even after updating to the latest software versions. The company continues to monitor regulatory developments to ensure that voice customization features can be deployed safely across all supported markets.
The hardware requirements for these advanced features reflect the growing computational demands of modern artificial intelligence. Processing complex voice synthesis and real-time dictation optimization requires substantial memory bandwidth and thermal management capabilities. Apple has structured its device lineup to ensure that only models with sufficient neural processing capacity can access the full feature set. This tiered approach prevents performance degradation on older hardware while maintaining a consistent user experience across the ecosystem. Developers must also account for varying storage capacities when implementing the new dictation engine. The company continues to refine its optimization techniques to maximize efficiency across all compatible devices.
How does this development fit into the broader evolution of virtual assistants?
The virtual assistant landscape has undergone significant transformation over the past decade. Early implementations focused on basic command execution and simple information retrieval. Modern systems now prioritize contextual awareness, proactive suggestions, and adaptive communication styles. The introduction of customizable vocal parameters represents a natural progression toward more human-like interaction models. Competitors in the technology sector have experimented with similar features, but Apple's approach emphasizes local processing and user control. This strategy differentiates the platform from services that depend on continuous cloud connectivity. The shift reflects a broader industry recognition that privacy and performance must coexist within AI-driven interfaces.
Future developments will likely expand vocal customization to include additional tonal characteristics and contextual voice profiles. Users may eventually select different vocal identities for various scenarios, such as professional communication, casual conversation, or accessibility mode. The current slider-based interface serves as a foundational step toward more sophisticated audio personalization. As computational efficiency improves, the system will be able to process more complex vocal adjustments without impacting battery life or thermal performance. This evolution will continue to reshape how individuals interact with digital devices on a daily basis. The focus remains on creating technology that adapts to human behavior rather than forcing users to adapt to rigid system constraints.
The broader industry context reveals a clear shift toward privacy-preserving artificial intelligence architectures. Competitors have gradually moved away from cloud-dependent voice processing due to growing consumer concerns regarding data security. Local processing models offer a compelling alternative that maintains functionality while protecting user information. Apple's approach aligns with this industry-wide transition, emphasizing on-device computation and transparent feature distribution. The developer beta program allows early adopters to provide feedback that will shape the final release. This collaborative development process ensures that the technology meets real-world usage requirements before widespread deployment. The focus remains on delivering reliable, secure, and highly customizable voice interactions.
Conclusion
The integration of adjustable voice expressiveness and pacing marks a meaningful step toward more responsive digital interfaces. By prioritizing local processing and user-controlled audio parameters, the update addresses longstanding concerns regarding latency, privacy, and accessibility. The enhanced dictation engine further solidifies voice input as a reliable alternative to traditional typing methods. As the technology matures across supported devices, users will experience increasingly seamless interactions that adapt to their individual preferences. The ongoing rollout will continue to shape how artificial intelligence integrates into everyday computing workflows.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)