VMware Cloud Foundation 9.1 and the Shift to Private Enterprise AI
Broadcom has released VMware Cloud Foundation 9.1 to position private cloud infrastructure as the primary environment for enterprise artificial intelligence workloads. The update emphasizes cost optimization, expanded hardware compatibility, and integrated zero-trust security to address the growing operational and compliance demands of production AI deployment.
The enterprise technology landscape is undergoing a fundamental recalibration as artificial intelligence transitions from experimental pilot programs to core production infrastructure. Organizations are no longer asking whether to deploy generative models, but rather where to host them securely and economically. This strategic pivot has accelerated the migration of inference workloads away from public hyperscalers and toward controlled, on-premises environments. The shift reflects a broader industry realization that data sovereignty, operational latency, and long-term expenditure must be balanced against the raw computational power of cloud providers.
Why does the private cloud matter for enterprise AI?
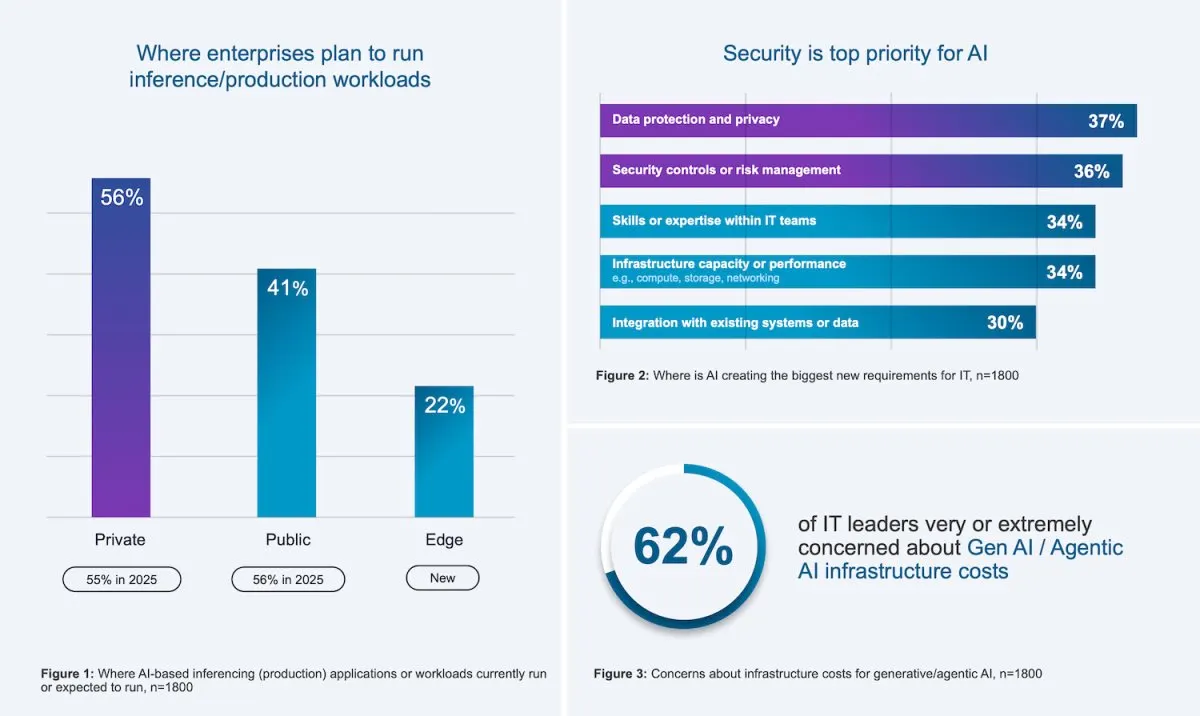
The transition toward private infrastructure represents a significant departure from the early cloud-first dogma that dominated the previous decade. Enterprise leaders are increasingly recognizing that public cloud models, while initially attractive for their rapid provisioning capabilities, often introduce unpredictable expenditure curves and complex data residency challenges. Recent industry surveys indicate that a majority of organizations are either running or actively planning to deploy inference workloads within private environments. This trend underscores a pragmatic recalibration where control over the underlying hardware becomes as valuable as the compute capacity itself.
Data governance remains a primary catalyst for this architectural shift. Regulatory frameworks across multiple jurisdictions continue to tighten around how sensitive information is processed, stored, and transmitted. When artificial intelligence models interact with proprietary corporate data, keeping that data within a physically controlled perimeter reduces compliance friction and minimizes exposure to third-party processing risks. Organizations that prioritize strict data localization are finding that private cloud architectures provide the necessary isolation without sacrificing the scalability required for modern machine learning pipelines.
Operational latency also drives the private cloud adoption curve. Inference applications demand consistent response times that public networks cannot always guarantee during peak congestion periods. By hosting compute resources closer to the data source, enterprises eliminate the round-trip delays inherent in cross-region cloud routing. This proximity enables faster decision-making cycles for applications ranging from real-time customer service automation to industrial monitoring systems. The resulting performance stability justifies the capital investment required to maintain dedicated hardware fleets.
The historical context of this migration reveals a maturation in enterprise IT strategy. Early cloud adoption focused heavily on capital expenditure avoidance and rapid scaling. As artificial intelligence workloads matured, financial leaders began tracking the true cost of data egress, network interconnectivity, and specialized accelerator rentals. These recurring expenses frequently exceed initial projections, prompting a return to hybrid models where core intelligence resides internally while burst capacity remains accessible externally.
How does VCF 9.1 address infrastructure efficiency?
Broadcom has structured the latest platform release around tangible efficiency gains that directly impact total cost of ownership. The architecture introduces intelligent memory tiering mechanisms designed to maximize workload density without requiring proportional hardware expansion. By dynamically allocating memory resources based on real-time demand, the platform claims to reduce server infrastructure costs by up to forty percent. This approach allows engineering teams to run more concurrent processes on existing silicon, effectively extending the useful lifespan of current data center assets.
Storage optimization forms another critical pillar of the efficiency strategy. Artificial intelligence pipelines generate massive volumes of intermediate data during training and inference phases. The updated platform incorporates enhanced compression and deduplication techniques specifically tailored for these data workflows. These storage improvements target a reduction in total cost of ownership by nearly forty percent. Organizations managing large-scale model deployments can now retain necessary historical data and checkpoint files without triggering exponential storage procurement cycles.
Kubernetes operations have also been refined to lower administrative overhead. The platform aims to reduce operational friction by up to thirty-eight percent while simultaneously improving deployment velocity and cluster scalability. Engineering teams benefit from accelerated cluster upgrades that execute four times faster than previous iterations. This speed reduction in maintenance windows translates directly into higher application availability. The expanded fleet capacity supports up to five thousand hosts, enabling enterprises to scale distributed AI infrastructure across multiple geographic locations without proportional increases in management complexity.
Hardware flexibility has become a decisive factor in infrastructure planning. Ongoing supply constraints in the graphical processing unit market have forced technology leaders to adopt multi-vendor strategies. The updated platform supports AMD and NVIDIA accelerators alongside Intel and AMD central processing units. This interoperability allows procurement teams to source components based on market availability rather than vendor lock-in. Organizations can mix and match hardware configurations to match specific workload requirements while maintaining a consistent management layer.
Unified architecture for mixed workloads
Modern data centers rarely run a single type of workload. The updated platform continues to push toward a unified infrastructure model that seamlessly supports virtual machines, containers, and specialized AI accelerators on the same physical hardware. This convergence addresses the growing reality that artificial intelligence does not operate in isolation. Inference engines frequently interact with legacy application databases, while agentic workflows require substantial central processing power alongside graphical processing units.
The expanded Kubernetes capabilities provide greater cluster scale and shorter upgrade windows, which are essential for production-grade services that demand continuous availability. Operational tooling now includes granular observability features that track critical metrics such as time-to-first-token, token throughput, and graphical processing unit utilization across multiple accelerator types. These metrics enable capacity planners to make data-driven decisions about resource allocation. Reusable application blueprints further standardize deployments, reducing configuration drift and ensuring consistent performance across development and production environments.
What role does security play in this architecture?
Security integration has moved from an afterthought to a foundational requirement in enterprise artificial intelligence deployment. The platform implements zero-trust segmentation across all workloads, including complex Kubernetes environments. This architectural approach ensures that no component automatically trusts another, regardless of network location. Distributed intrusion detection and prevention systems provide high-throughput inspection capabilities that monitor traffic patterns without introducing significant latency.
Ransomware protection has been explicitly addressed through isolated recovery environments and automated validation tools. These systems integrate with established endpoint security frameworks to protect high-value artificial intelligence assets. Keeping sensitive training data and model weights localized within the enterprise perimeter directly supports data sovereignty requirements. Organizations facing strict regulatory scrutiny can maintain audit readiness through continuous compliance features that automate monitoring and remediation against defined policy frameworks.
Live patching capabilities further reduce operational risk by enabling system updates without requiring service interruptions. This feature supports always-on artificial intelligence services that cannot afford traditional maintenance windows. The integration of virtualized load balancing and security services eliminates reliance on external hardware appliances. This consolidation helps reduce capital expenditures while maintaining application resilience and lifecycle automation across distributed infrastructure.
Compliance automation represents a significant operational advantage for large enterprises. Manual audit preparation often consumes substantial engineering hours and introduces human error into security reporting. Automated policy enforcement ensures that infrastructure configurations remain aligned with internal governance standards at all times. When regulatory requirements shift, updated policies can be deployed across the entire fleet simultaneously, ensuring consistent adherence without manual intervention across individual nodes.
How does the platform fit into the broader industry landscape?
The release represents a logical evolution for an organization attempting to reposition its infrastructure stack as a viable foundation for enterprise artificial intelligence. The emphasis on private cloud deployment, integrated security, and unified operations aligns closely with the stated needs of large enterprises. However, the broader technology ecosystem continues to evolve along different trajectories. Modern distributed artificial intelligence pipelines are increasingly built around Kubernetes-first architectures that prioritize direct access to accelerated compute resources.
In environments where flexibility and rapid iteration take precedence, traditional virtualization layers can sometimes function as additional overhead rather than a foundational benefit. Cost considerations also remain a significant factor in platform adoption decisions. While efficiency gains are measurable, ongoing concerns regarding licensing structures and total cost of ownership persist across many enterprise IT departments. Smaller organizations often exhibit heightened sensitivity to platform lock-in and licensing changes, which can complicate long-term infrastructure planning.
Larger enterprises, by contrast, typically possess the financial flexibility and dedicated engineering expertise to absorb licensing costs and invest in specialized Kubernetes operations. These organizations are more likely to view the platform as a strategic asset that consolidates management overhead. The clear role for this infrastructure lies with enterprises that are already deeply invested in the ecosystem and prioritize data governance, operational consistency, and private infrastructure control.
Vendor ecosystem integration continues to shape platform viability. Interoperability with established networking standards and security providers reduces friction during deployment. Organizations can leverage existing relationships with infrastructure partners while adopting new artificial intelligence capabilities. This approach minimizes disruption to established operational workflows and allows teams to focus on application development rather than infrastructure reconciliation.
What does this mean for future enterprise infrastructure?
The ongoing consolidation of artificial intelligence workloads into private environments signals a maturation in how organizations approach technological adoption. Early experimentation phases have given way to structured production requirements that demand reliability, compliance, and predictable expenditure. Infrastructure providers that successfully bridge the gap between traditional virtualization management and modern containerized workflows will likely capture significant market share in the coming years.
Enterprises must carefully evaluate their existing technical debt against future scalability needs. Organizations that prioritize data sovereignty and operational control will find substantial value in unified platforms that support mixed workloads. Teams focused on rapid innovation and modular architecture may continue to lean toward specialized Kubernetes-native stacks. The decision ultimately hinges on aligning infrastructure capabilities with specific business objectives rather than following broad industry trends.
As artificial intelligence capabilities continue to expand, the underlying infrastructure must remain adaptable. The focus will increasingly shift toward intelligent resource allocation, automated compliance monitoring, and seamless hardware abstraction. Providers that deliver measurable efficiency gains while maintaining strict security boundaries will remain relevant. The industry will continue to balance the demand for rapid deployment with the necessity of long-term operational stability.
The strategic positioning of private infrastructure reflects a broader industry correction toward sustainable growth models. Companies that previously prioritized speed over cost are now recalibrating their capital allocation strategies. This shift encourages technology vendors to develop solutions that offer transparent pricing and modular component selection. The market will likely reward platforms that demonstrate clear return on investment through measurable operational improvements rather than abstract performance benchmarks.
Future infrastructure planning will require greater collaboration between engineering teams and financial stakeholders. Budget approvals for artificial intelligence initiatives will depend on concrete efficiency metrics and long-term maintenance projections. Organizations that establish clear governance frameworks early in their deployment cycles will navigate hardware procurement and software licensing more effectively. The convergence of operational technology and financial planning will define the next generation of enterprise computing strategies.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)