Why AI Leaderboards Are Obsolete and Pareto Curves Succeed
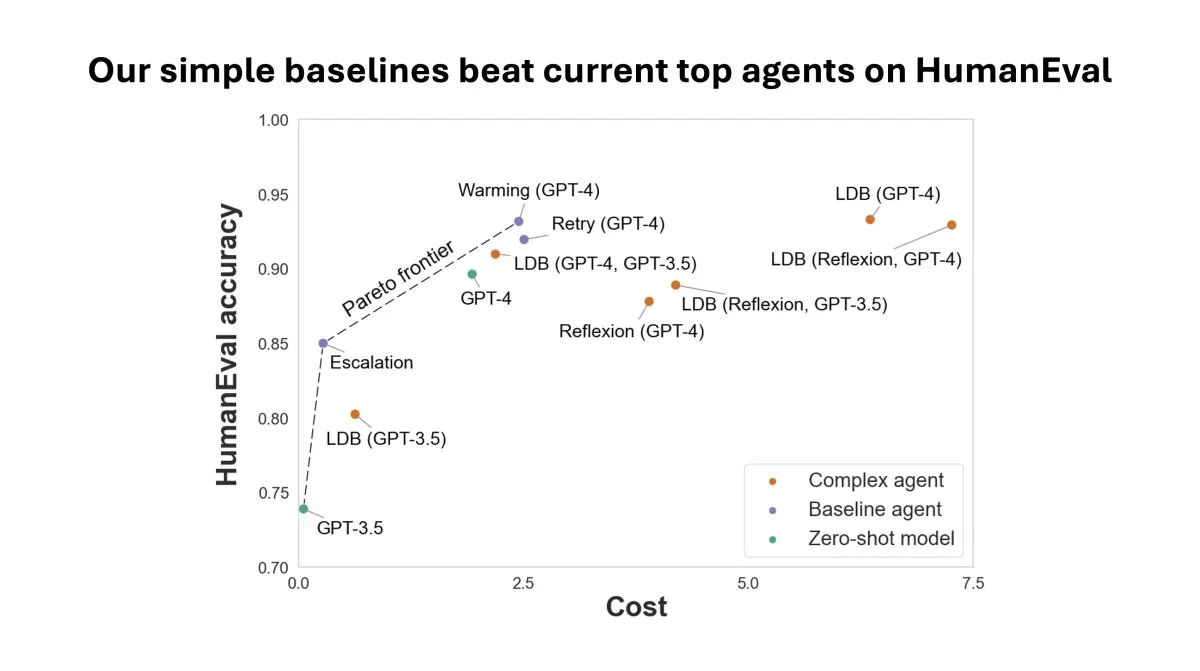
Single-metric AI leaderboards no longer reflect reality. Engineers must evaluate models using Pareto curves to understand performance trade-offs across multiple objectives. This approach reveals optimal configurations for specific deployment contexts. Teams should prioritize balanced optimization over artificial rankings to build reliable systems.
The rapid advancement of artificial intelligence has fundamentally altered how researchers measure progress. Traditional evaluation methods once relied on singular metrics to declare a clear winner. Those days have passed. Modern systems require balancing accuracy, latency, cost, and safety simultaneously. Relying on a single number to rank models creates a distorted view of real-world performance. Engineers now face a complex landscape where optimizing one capability inevitably degrades another. This shift demands a more nuanced approach to assessment. The industry must abandon outdated ranking systems and adopt frameworks that reflect genuine operational trade-offs.
What is the fundamental flaw in current AI evaluation frameworks?
Traditional benchmarking methodologies assume that a single score can capture the entirety of a model capability. This assumption collapses under the weight of modern system complexity. Researchers historically treated evaluation as a linear competition. They believed that improving one metric would naturally improve overall utility. That premise ignores the inherent conflicts between different performance dimensions. Accuracy often requires larger parameter counts, which directly increases inference costs. Latency improvements frequently demand architectural simplifications that reduce reasoning depth. Safety enhancements routinely limit creative output or flexibility. These competing objectives cannot be compressed into a single number without losing critical information.
When evaluation frameworks force models into a rigid hierarchy, they create artificial winners and losers. A model that ranks first on a standard test may perform poorly in production environments. The ranking system rewards narrow optimization rather than robust deployment readiness. Engineers waste resources chasing marginal gains on outdated benchmarks. They neglect the actual constraints that determine whether a system functions in the real world. The industry continues to treat evaluation as a sport rather than an engineering discipline. This misalignment slows progress and misdirects funding toward superficial improvements.
The core problem lies in how rankings obscure the underlying data distribution. A single aggregate score hides the variance across different task types. It masks the specific conditions where a model excels or fails. Users cannot determine whether a top-ranked system is suitable for their particular use case. The ranking provides a false sense of clarity. It suggests that one model dominates all others across every dimension. This illusion prevents teams from making informed architectural decisions. They select models based on prestige rather than practical fit. The evaluation process must shift toward multidimensional analysis.
The reliance on static benchmarks creates a feedback loop that stifles innovation. Researchers optimize for test conditions rather than actual user needs. This behavior distorts the direction of technological progress. The field becomes trapped in a cycle of diminishing returns. Teams spend years refining models for datasets that no longer reflect market demands. The opportunity cost of this approach is substantial. Capital and talent are diverted from genuine breakthroughs toward incremental benchmark chasing. The industry must break this cycle by redefining success metrics.
Why does the Pareto curve offer a superior alternative?
The Pareto curve represents a mathematical framework for mapping trade-offs between competing objectives. It identifies the set of optimal solutions where improving one metric inevitably worsens another. This approach acknowledges that no single model can maximize every capability simultaneously. Engineers can plot performance across multiple dimensions to visualize the true frontier of capability. The curve reveals the exact points where additional investment yields diminishing returns. It highlights the most efficient configurations for specific operational requirements. This methodology transforms abstract performance data into actionable engineering insights.
Traditional leaderboards force a linear comparison that ignores these natural boundaries. A Pareto analysis respects the complex reality of system design. It shows that different deployment scenarios require different points along the curve. A customer service application might prioritize latency and cost over absolute accuracy. A medical diagnostics tool might prioritize precision regardless of computational expense. The curve provides the necessary context to make these decisions. It transforms evaluation from a ranking exercise into a strategic planning tool.
This framework also exposes the limitations of current benchmarking datasets. Many existing tests measure narrow capabilities that do not translate to production value. The Pareto approach forces teams to define their own relevant objectives. It encourages the creation of custom evaluation suites tailored to specific domains. Researchers can track progress along multiple axes simultaneously. They can identify which models occupy the most advantageous positions for their needs. The methodology promotes transparency and reproducibility in system assessment.
Visualizing the Pareto frontier also clarifies the limits of current hardware constraints. Computational efficiency often conflicts with model capacity. Engineers can identify the exact point where additional processing power yields negligible gains. This knowledge prevents unnecessary infrastructure expenditure. It guides architects toward more efficient algorithmic designs. The curve serves as a compass for resource allocation. Teams can stop chasing impossible performance targets and focus on achievable optimization goals.
How do multi-objective trade-offs reshape model development?
Development pipelines must adapt to accommodate multidimensional optimization strategies. Engineers can no longer treat model training as a single-target optimization problem. They must design loss functions that balance competing priorities from the outset. This requires careful calibration of weighting parameters across different performance metrics. Teams need robust monitoring systems that track trade-offs in real time. Continuous evaluation becomes essential rather than optional. The training process must explicitly account for the cost of performance degradation in other areas.
The shift toward multi-objective development changes how research funding is allocated. Institutions must fund experiments that explore the full capability frontier instead of chasing narrow benchmarks. This approach reduces the risk of building systems that excel only in controlled environments. It encourages the development of more versatile architectures that can adapt to varying constraints. Researchers gain a clearer understanding of where future improvements are possible. They can identify bottlenecks that single-metric evaluations completely conceal.
Production teams benefit directly from this expanded perspective. Deployment decisions become grounded in actual operational requirements rather than artificial rankings. Engineering groups can select models that align precisely with their infrastructure limits. They can predict how scaling decisions will impact overall system behavior. The multi-objective framework provides a common language for cross-functional collaboration. Product managers, researchers, and infrastructure engineers can discuss trade-offs using shared data. This alignment accelerates the path from prototype to reliable service, much like accelerating engineering cycles 20% with OpenAI demonstrates for modern development workflows.
Model selection processes require complete restructuring to accommodate this new reality. Procurement teams must evaluate proposals based on multidimensional performance profiles. They should request detailed trade-off data rather than aggregate scores. This practice ensures that purchased systems match actual workload requirements. It also establishes clearer accountability for development teams. Engineers are incentivized to build versatile models rather than narrow specialists. The procurement process becomes a strategic alignment exercise rather than a simple comparison.
What practical adjustments should engineering teams implement?
Organizations must first audit their current evaluation practices to identify reliance on outdated metrics. Teams should map their specific deployment constraints onto a multidimensional coordinate system. This mapping process clarifies which objectives matter most for their particular context. Engineering leaders can then design custom evaluation suites that reflect these priorities. The new framework should replace legacy benchmarking tools entirely. The transition requires careful planning and sustained commitment from leadership.
Data collection protocols require immediate revision to capture performance across multiple dimensions. Teams must log inference costs, latency distributions, and accuracy variance simultaneously. Automated monitoring systems should generate dynamic Pareto plots for every model iteration. These visualizations make trade-offs immediately apparent to decision makers. Engineers can track how architectural changes shift a model along the capability frontier. The data stream provides continuous feedback for iterative improvement. This practice eliminates guesswork from the development cycle.
Collaboration workflows must evolve to support multidimensional analysis. Cross-functional teams should establish shared definitions for each evaluation axis. Regular review meetings should focus on interpreting the Pareto frontier rather than comparing aggregate scores. This cultural shift reduces friction between research and engineering departments. It ensures that model selection aligns with long-term business objectives. Organizations that adopt this methodology will build more resilient and adaptable systems. This approach mirrors LaunchDarkly's approach to AI-powered product management by emphasizing controlled rollout strategies over broad deployment.
Training protocols must incorporate dynamic weighting mechanisms to handle shifting priorities. Fixed evaluation weights quickly become obsolete as market conditions change. Adaptive systems can automatically adjust optimization goals based on real-time feedback. This flexibility allows models to remain relevant across different deployment phases. Engineers can pivot focus without rebuilding architectures from scratch. The training pipeline becomes responsive to operational demands. This adaptability reduces long-term maintenance costs and extends model lifespans.
What does the future of AI assessment look like?
The transition away from singular rankings represents a necessary evolution in AI assessment. Multidimensional evaluation frameworks provide the clarity that traditional leaderboards cannot. Engineers gain actionable insights into real-world performance boundaries. Teams can make informed decisions that balance capability, cost, and reliability. The industry moves forward by embracing complexity rather than simplifying it. Sustainable progress depends on accurate measurement.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)