Scientists Should Treat Artificial Intelligence as a Tool, Not an Oracle
Researchers must approach artificial intelligence as a methodological instrument rather than a definitive authority. Treating algorithmic outputs as unquestionable truth introduces systemic bias and undermines scientific rigor. Adopting a disciplined framework preserves intellectual autonomy and ensures computational assistance enhances critical analysis. This approach guarantees that empirical standards remain intact throughout the research process.
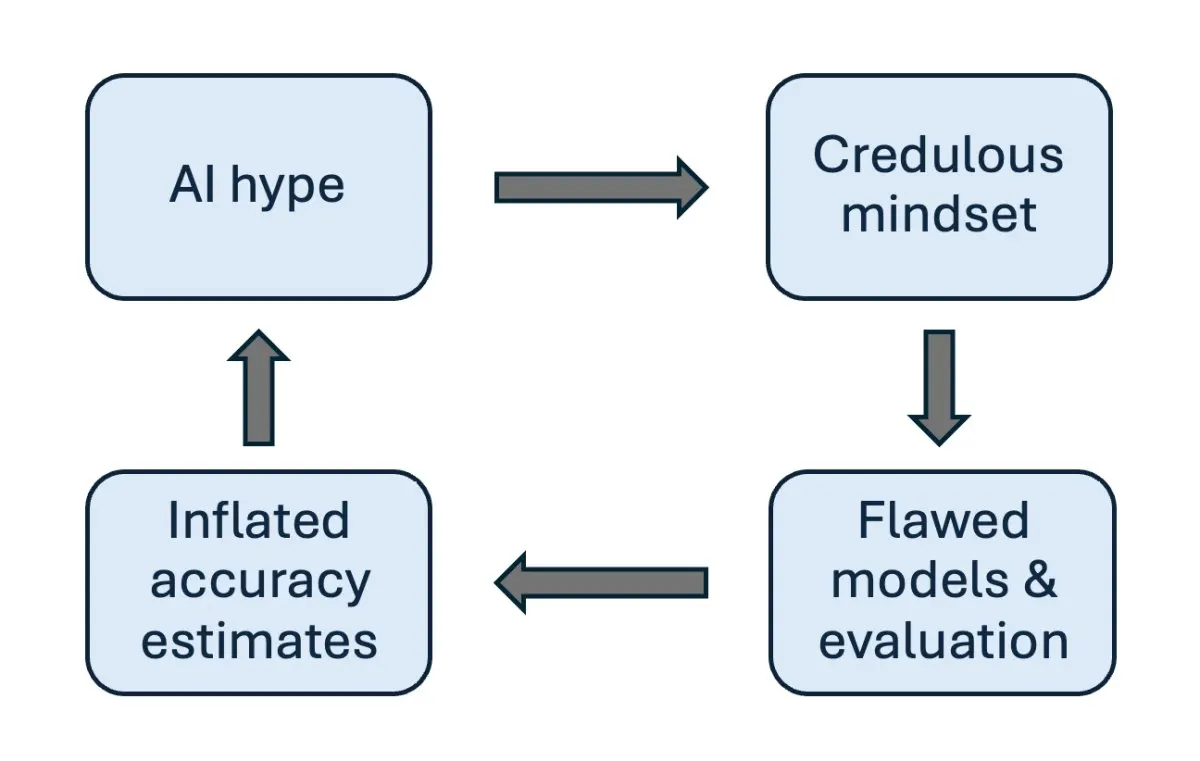
The modern research landscape is undergoing a profound transformation as computational systems become deeply embedded in experimental design and data analysis. Researchers now routinely interact with algorithmic models that generate hypotheses and process vast datasets. This integration brings undeniable efficiency, yet it also introduces a subtle but dangerous shift in how scientific truth is pursued. When algorithmic outputs are treated as definitive answers rather than provisional suggestions, the foundational principles of empirical inquiry begin to erode.
What is the fundamental difference between a scientific instrument and an algorithmic oracle?
Traditional scientific tools extend human perception while remaining subject to calibration, error margins, and operator interpretation. These instruments require active engagement, continuous validation, and explicit acknowledgment of their limitations. An algorithmic oracle operates differently by presenting complex outputs as self-contained conclusions. The interface masks the underlying computational steps, creating an illusion of infallibility. Researchers who accept these outputs without interrogation surrender their analytical responsibility to a system that cannot be questioned in the traditional scientific manner.
The distinction matters because scientific progress depends on transparent methodology, reproducible procedures, and the willingness to challenge every piece of evidence. When a computational model replaces the scientist as the primary arbiter of truth, the entire epistemological framework shifts from verification to acceptance. Historical advances in science have always required researchers to maintain a critical distance from their instruments. This distance ensures that observations remain grounded in reality rather than in the characteristics of the measuring device itself.
Why does treating computational assistance as infallible threaten research integrity?
Algorithmic systems are trained on historical data that reflects existing biases, gaps, and methodological constraints. When researchers treat these outputs as authoritative, they inadvertently encode past limitations into future discoveries. The danger lies in the feedback loop that forms when unverified computational results guide experimental design. This cycle obscures alternative explanations and narrows the scope of inquiry. Scientific rigor demands that every finding be scrutinized through multiple independent lenses to prevent systemic error.
Computational assistance should function as a catalyst for hypothesis generation, not as a substitute for peer review and empirical validation. Maintaining methodological independence ensures that discoveries remain grounded in observable reality rather than statistical probability. The scientific method relies on falsifiability and the continuous testing of assumptions. When researchers outsource critical evaluation to automated systems, they remove the very mechanisms that protect against confirmation bias and methodological drift.
Establishing methodological boundaries in computational research
Researchers can preserve analytical independence by implementing strict protocols around algorithmic integration. The first step involves treating every computational output as a preliminary draft rather than a final determination. This requires explicit documentation of model parameters, training data sources, and known error rates. Scientists must also establish independent verification pathways that do not rely on the same computational infrastructure. Cross-validation through traditional experimental methods remains essential for confirming algorithmic predictions.
The goal is not to reject computational assistance but to structure its use within a transparent framework. When researchers maintain clear boundaries between hypothesis generation and empirical validation, they prevent algorithmic bias from dictating scientific direction. This disciplined approach aligns computational efficiency with the established standards of scientific accountability. Institutions that adopt these practices will find that methodological rigor and technological adoption can coexist, echoing the structural shifts observed during NVIDIA GTC Taipei and COMPUTEX: Architectural Shifts in AI Development.
How can the scientific community adapt without abandoning computational progress?
The integration of advanced computational systems into research workflows requires structural adjustments rather than outright rejection. Institutions must develop training programs that emphasize algorithmic literacy alongside traditional scientific methodology. Researchers need to understand how models process information, where they fail, and how to interpret probabilistic outputs correctly. Collaborative frameworks that bring together computational experts and domain specialists can help establish shared standards for validation and transparency.
These efforts demonstrate that computational assistance and rigorous inquiry are not mutually exclusive. The objective is to build systems that enhance human judgment rather than replace it. Academic programs and professional development courses should prioritize critical evaluation skills alongside technical proficiency. By fostering a culture of methodological skepticism, the research community can harness computational power while maintaining the intellectual independence that drives genuine discovery, much like the collaborative frameworks discussed in the 1,000 Scientist AI Jam Session.
Preserving intellectual autonomy in an automated research environment
Scientific advancement has always depended on the ability to question established paradigms and pursue unexpected results. When computational systems dominate the research process, there is a risk that algorithmic constraints will silently dictate which questions are worth asking. Researchers must actively cultivate intellectual autonomy by maintaining independent analytical pathways and refusing to outsource critical evaluation to automated systems. This requires deliberate effort to document alternative hypotheses and challenge model outputs.
The most robust research programs treat computational assistance as one component within a broader investigative strategy. By preserving the scientist as the primary decision maker, the field maintains its commitment to empirical truth and methodological transparency. The history of science shows that breakthroughs often emerge from anomalies that algorithms initially dismiss as noise. Maintaining human oversight ensures that unexpected findings receive the attention they require rather than being filtered out by probabilistic thresholds.
What structural changes are necessary to safeguard future discovery?
Academic institutions and funding agencies must revise evaluation criteria to reward methodological transparency over computational novelty. Publication standards should require detailed documentation of algorithmic inputs, processing steps, and validation procedures. Peer review processes need to incorporate specialists who can assess computational methodology alongside traditional scientific claims. These structural adjustments will create incentives for researchers to maintain analytical independence while utilizing advanced tools.
Professional organizations should develop clear guidelines for the ethical integration of algorithmic systems into experimental workflows. These guidelines must emphasize that computational outputs are provisional until confirmed through independent empirical methods. Training programs must continue to evolve alongside technological capabilities, ensuring that new generations of researchers inherit both technical proficiency and critical skepticism. The long-term health of scientific inquiry depends on maintaining this balance.
Conclusion
The trajectory of modern research depends on how scholars navigate the intersection of human judgment and computational capability. Algorithmic systems offer unprecedented speed and scale, yet they cannot replicate the critical reasoning that drives scientific discovery. Treating these tools as authoritative sources of truth introduces systemic vulnerabilities that compromise the reliability of published findings. Researchers who maintain strict methodological boundaries will preserve the integrity of their work.
The future of scientific inquiry relies on balancing computational efficiency with unwavering analytical independence. Only by treating algorithmic assistance as a subordinate instrument can the research community ensure that discovery remains guided by evidence rather than probability. The enduring strength of science lies in its willingness to question every assumption, including the ones embedded in the tools we use to explore the world.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)