Apple Intelligence Writing Tools Shift to Contextual Adaptation in iOS 27
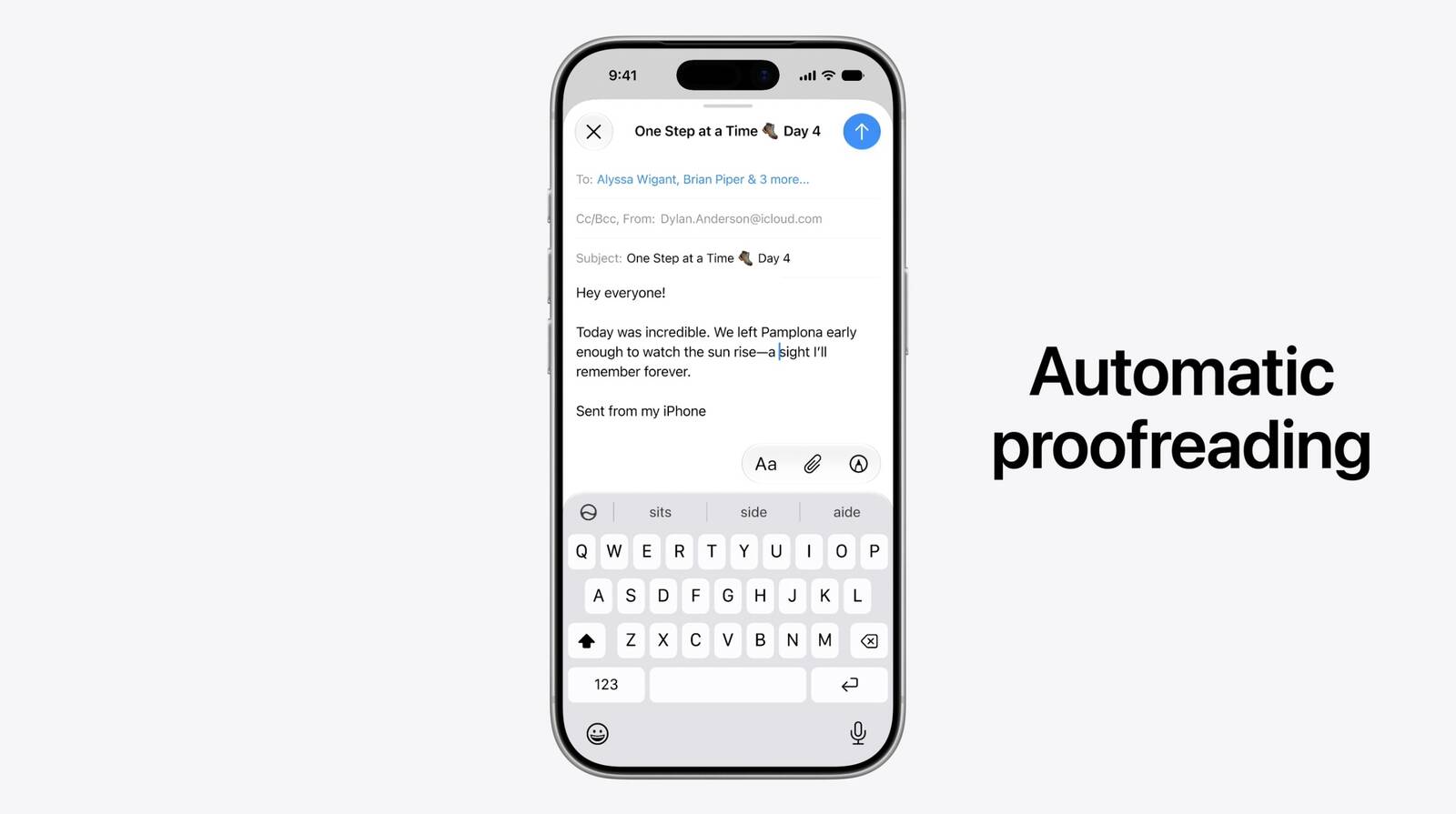
Apple Intelligence introduces adaptive composition, system-wide proofreading, and content-aware file naming in iOS 27. These updates shift focus from generic generation to personalized assistance that aligns with individual communication habits and organizational preferences. The changes emphasize privacy-preserving on-device processing while streamlining daily digital workflows across messaging, email, and document management.
The integration of artificial intelligence into everyday communication has shifted from experimental novelty to foundational infrastructure. Recent platform updates signal a deliberate pivot toward contextual awareness rather than raw generative power. Software ecosystems are increasingly prioritizing seamless adaptation over explicit command inputs. This evolution reflects a broader industry consensus that utility lies in anticipation, not just execution. Users now expect digital tools to recognize patterns and adjust outputs accordingly. The latest release cycle demonstrates this principle through refined writing assistants that operate across multiple applications simultaneously.
Apple Intelligence introduces adaptive composition, system-wide proofreading, and content-aware file naming in iOS 27. These updates shift focus from generic generation to personalized assistance that aligns with individual communication habits and organizational preferences. The changes emphasize privacy-preserving on-device processing while streamlining daily digital workflows across messaging, email, and document management.
What is the Core Shift in Apple Intelligence Writing Tools?
The transition from static text generation to dynamic contextual assistance represents a fundamental recalibration of how software interacts with human input. Previous iterations relied heavily on predefined templates or broad statistical models that often produced uniform results regardless of user intent. The current framework abandons this one-size-fits-all approach in favor of continuous learning within secure boundaries. By analyzing historical communication patterns, the system constructs individualized linguistic profiles without transmitting personal data to external servers. This architectural choice ensures that stylistic nuances remain private while still delivering highly relevant suggestions.
The implications extend beyond mere convenience. When writing assistants understand a user's professional tone versus casual correspondence habits, they reduce cognitive friction during composition. Writers no longer need to manually adjust phrasing or search for alternative vocabulary because the tool anticipates the required register before typing concludes. This proactive adjustment accelerates drafting phases and minimizes post-composition editing cycles. The underlying technology maps semantic relationships between past messages and current prompts, creating a feedback loop that refines accuracy over time.
Industry observers note that this direction aligns with broader computational trends emphasizing localized processing models. Centralized cloud-based generation requires constant data transmission, which introduces latency and privacy vulnerabilities. Localized execution eliminates those bottlenecks while maintaining responsiveness across different applications. The result is a more cohesive experience where writing assistance functions as an integrated layer rather than a disconnected utility. This integration allows seamless transitions between drafting emails, composing messages, and editing documents without interrupting workflow momentum.
How Does Adaptive Composition Change User Interaction?
Communication platforms have historically treated each message as an isolated event, ignoring the relational context that defines modern digital correspondence. The updated composition assistant directly addresses this limitation by tracking conversational history and contact-specific preferences. When drafting a professional email to a colleague, the system recognizes formal conventions and suggests appropriate terminology. Conversely, interactions with close contacts trigger more relaxed syntax and familiar phrasing patterns. This differentiation eliminates the need for manual tone adjustments during rapid exchanges.
Smart Reply mechanisms have undergone similar transformations. Earlier iterations offered standardized responses that frequently felt impersonal or contextually misaligned. The revised approach draws upon personalized writing styles to generate quick replies that sound authentically human. Users receive suggestions that mirror their own vocabulary choices, sentence structures, and punctuation habits. This personalization reduces the awkwardness often associated with automated messaging tools while preserving speed during high-volume communication periods.
The technical foundation relies on sophisticated pattern recognition algorithms operating within secure enclaves. These systems analyze syntactic markers, lexical preferences, and conversational rhythms without storing raw message content indefinitely. By focusing on structural relationships rather than specific data points, the assistant maintains privacy compliance while delivering highly tailored outputs. Developers have prioritized this balance to ensure that personalization does not compromise user trust or regulatory requirements across different jurisdictions.
The Mechanics of Contextual Adaptation
Understanding how contextual adaptation functions requires examining the underlying data processing architecture. The assistant continuously evaluates linguistic markers during active composition sessions, building a dynamic model of individual communication habits. This model updates incrementally rather than resetting with each new session, ensuring long-term accuracy without demanding explicit configuration from users. The system distinguishes between temporary stylistic variations and consistent behavioral patterns to avoid overfitting suggestions to isolated incidents.
Why Does System-Wide Proofreading Matter for Workflow Efficiency?
Traditional proofreading tools function as separate applications requiring manual activation and text selection. This fragmented approach interrupts creative flow and demands additional cognitive effort from users who must constantly switch contexts between writing and editing phases. The new automatic proofreading feature eliminates this friction by surfacing corrections in real time as characters appear on screen. Spelling discrepancies and grammatical inconsistencies receive immediate visual indicators alongside contextual suggestions that adapt to regional language standards.
Real-time correction mechanisms require substantial computational optimization to maintain responsiveness across diverse hardware configurations. The system prioritizes low-latency processing by leveraging specialized neural architecture designed for continuous text analysis. Users experience minimal delay between keystrokes and suggestion delivery, preserving the natural rhythm of composition. This seamless integration transforms proofreading from a post-drafting chore into an invisible background process that enhances accuracy without demanding active attention.
The broader impact on professional environments involves reduced error rates and improved communication clarity. Teams utilizing shared messaging platforms benefit from consistent terminology and standardized formatting across different devices. Individuals drafting lengthy documents experience fewer revision cycles because foundational errors are addressed during initial composition rather than after publication. This shift toward preventive correction aligns with modern productivity frameworks that emphasize continuous refinement over retrospective editing.
What Are the Practical Implications for Digital Organization?
File management has traditionally relied on manual naming conventions and rigid folder hierarchies that struggle to scale alongside growing digital archives. The introduction of intelligent file and folder naming suggestions addresses this structural limitation by analyzing document content to generate descriptive titles automatically. Users no longer need to memorize complex directory structures or spend time crafting precise labels for every new asset. The system extracts key themes, dates, and subject matter from the underlying material to produce contextually accurate identifiers.
This capability extends beyond simple text extraction by incorporating semantic understanding of document purpose and audience. A technical specification receives different naming conventions than a creative brief or financial report. The assistant recognizes these distinctions through pattern matching against established organizational standards while remaining flexible enough to accommodate individual preferences. Users retain full control over final nomenclature, allowing them to accept suggestions, modify them, or override the system entirely when necessary.
Long-term digital hygiene improves significantly when naming conventions adapt dynamically to content evolution rather than static user input. Archives become more searchable and navigable as files accumulate across multiple projects and timeframes. Collaboration environments benefit from standardized terminology that reduces ambiguity during cross-team document sharing. This organizational layer operates quietly in the background, ensuring that information retrieval remains efficient regardless of how rapidly digital assets multiply over extended periods.
Intelligent Naming Conventions and File Management
The convergence of natural language processing and file system architecture represents a significant milestone in digital organization. By treating filenames as dynamic descriptors rather than static labels, the platform reduces administrative overhead for power users. This approach mirrors how human memory associates concepts with contextual cues rather than rigid categorization schemes. As digital workspaces grow increasingly complex, automated semantic labeling provides a scalable solution that adapts to evolving project requirements without manual intervention.
How Will These Updates Reshape Future Platform Development?
The current iteration establishes a baseline for continuous environmental adaptation rather than periodic feature expansion. Software ecosystems are increasingly designed to learn from usage patterns while maintaining strict boundaries around data retention and processing scope. This model encourages developers to prioritize contextual accuracy over raw generative capacity, shifting research focus toward more efficient local computation techniques. Future updates will likely build upon this foundation by refining predictive algorithms and expanding compatibility across additional applications.
Cross-platform synchronization remains a critical consideration as users transition between mobile devices, desktop computers, and wearable hardware. The architecture must ensure that personalized linguistic profiles update consistently without introducing version conflicts or privacy breaches during data transmission. Engineers are addressing these challenges through encrypted local storage protocols and incremental learning frameworks that preserve user preferences across device ecosystems. This approach guarantees that assistance remains reliable regardless of which interface initiates a communication task.
The broader trajectory points toward increasingly autonomous digital assistants capable of managing complex workflows with minimal explicit direction. Writing tools will continue evolving from reactive suggestion engines into proactive collaborators that anticipate structural needs before users articulate them. Industry standards around ethical AI deployment will likely tighten as personalization capabilities expand, requiring transparent documentation of how linguistic profiles are constructed and maintained. Organizations adopting these systems must balance efficiency gains with rigorous oversight to prevent unintended bias or over-reliance on automated outputs.
The integration of adaptive writing assistance marks a decisive step toward more intuitive digital environments. By prioritizing contextual awareness, localized processing, and seamless cross-application functionality, the latest platform update addresses longstanding friction points in everyday communication. Users gain tools that respect privacy boundaries while delivering highly personalized outputs tailored to individual habits. This evolution demonstrates how computational resources can be allocated toward refinement rather than expansion, creating sustainable pathways for future technological advancement. The focus remains firmly on enhancing human capability through unobtrusive, reliable assistance that adapts continuously to changing workflows and organizational demands.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)