Apple Foundation Models Upgrade Boosts Image Playground Performance
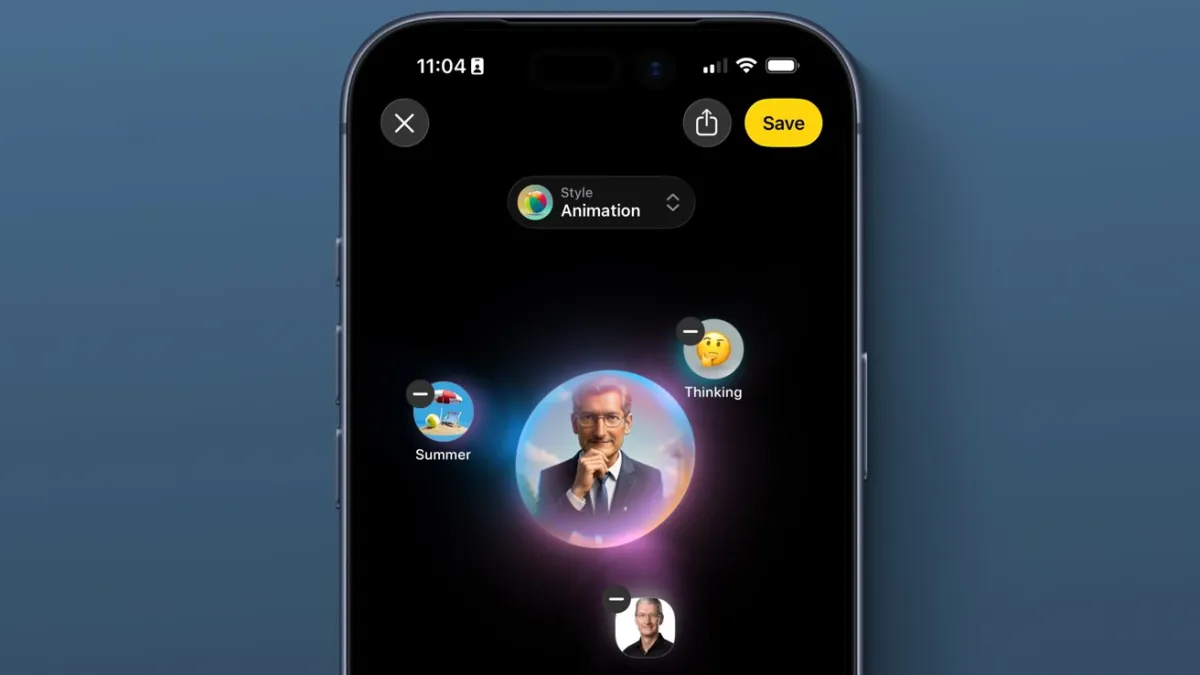
Apple Foundation Models will receive substantial upgrades in the upcoming operating system cycle, directly addressing previous shortcomings in generative artificial intelligence tools. Image Playground and Genmoji functionality should experience notable performance enhancements as the underlying neural architecture matures across compatible hardware devices.
Apple has long approached artificial intelligence with deliberate caution, prioritizing device security over rapid feature deployment. The company consistently emphasizes local processing capabilities to ensure user data remains confined within hardware boundaries rather than traveling across external networks. This architectural philosophy shapes every subsequent software update and defines the baseline expectations for consumer technology integration.
What is Apple Foundation Models?
The Apple Foundation Models framework represents a dedicated suite of machine learning architectures designed specifically for on-device execution. These systems operate independently from cloud-based inference networks, allowing applications to generate text and imagery without requiring persistent internet connectivity. The design prioritizes computational efficiency while maintaining strict privacy boundaries that prevent raw user inputs from leaving the local environment.
Developers utilize these frameworks to build consistent experiences across multiple operating system versions and hardware generations. The architecture standardizes how neural networks interpret prompts, process contextual data, and render outputs directly within application interfaces. This approach eliminates latency issues associated with remote servers while ensuring predictable performance metrics across diverse device configurations.
The underlying technology relies heavily on specialized silicon components that accelerate matrix operations and tensor calculations. Engineers optimize these pathways to balance thermal output with sustained computational throughput during extended generation sessions. Users benefit from reduced power consumption compared to traditional cloud-dependent alternatives, though initial processing times may vary based on available hardware resources.
Why does generative AI matter for macOS users?
Creative workflows increasingly depend upon automated assistance tools that streamline repetitive tasks and accelerate concept development. Professionals require reliable systems that understand contextual nuances while maintaining consistent output quality across multiple sessions. The integration of localized neural networks enables continuous iteration without interrupting established production pipelines or compromising sensitive project documentation.
Consumer applications similarly demand responsive interfaces that adapt to individual preferences and historical usage patterns. Users expect seamless transitions between manual drafting and automated refinement phases without encountering unexpected formatting errors or degraded visual fidelity. Reliable generation capabilities transform ordinary productivity suites into dynamic environments capable of supporting complex design requirements.
The broader ecosystem benefits from standardized model implementations that reduce fragmentation across different software categories. Applications share common architectural foundations, allowing developers to focus on interface design rather than rebuilding core inference engines for every new release cycle. This consolidation accelerates feature deployment while maintaining predictable performance standards across the entire platform.
The evolution of local processing architectures
Early implementations struggled with limited memory allocation and constrained computational pathways that restricted output complexity. Engineers gradually expanded neural network capacity by optimizing compiler instructions and refining memory management protocols. Each subsequent hardware generation introduced dedicated acceleration units that dramatically improved inference speed while maintaining consistent thermal profiles during intensive workloads.
Software updates continuously refine how these systems interpret ambiguous prompts and resolve conflicting contextual requirements. The architecture now supports multi-modal processing capabilities that combine textual inputs with visual references to generate more accurate outputs. This progression eliminates previous limitations regarding style consistency and structural coherence across extended generation sequences.
Future iterations will likely expand parameter counts while maintaining strict privacy boundaries through enhanced encryption protocols. Developers anticipate smoother transitions between active processing states and idle modes, reducing visible interface delays during complex rendering operations. The ongoing refinement ensures compatibility with increasingly sophisticated application requirements without compromising baseline security standards.
How does Image Playground function within the ecosystem?
The dedicated creative environment provides users with straightforward controls for generating custom imagery based on textual descriptions or reference materials. Applications utilize localized neural networks to interpret stylistic preferences while maintaining consistent visual coherence across multiple output variations. Users can adjust complexity parameters and select appropriate rendering modes before initiating generation sequences that remain entirely confined within device boundaries.
The interface organizes generated assets into accessible libraries that support immediate integration with other productivity applications. Files maintain standard metadata structures, allowing seamless transfer between creative suites without requiring format conversion or quality degradation. This architecture ensures that users retain full ownership of created materials while preserving original resolution specifications throughout the workflow.
Performance metrics depend heavily on available computational resources and current system load conditions during active processing sessions. The framework dynamically allocates memory pathways to prioritize generation tasks while maintaining background application stability. Users experience consistent output quality regardless of external network availability, though initial rendering times may fluctuate based on hardware capabilities.
Genmoji and avatar generation mechanics
Custom emoji creation relies upon specialized neural pathways that interpret facial expressions, stylistic preferences, and contextual requirements. The system processes input parameters through dedicated inference engines that prioritize anatomical accuracy while maintaining consistent artistic direction across multiple variations. Users receive immediate feedback on generated assets before committing to final selections for messaging applications or creative projects.
The underlying architecture separates structural modeling from textural rendering to optimize computational efficiency during intensive generation phases. Engineers designed the pathways to handle complex geometric transformations without compromising visual fidelity or introducing unexpected artifacts into final outputs. This separation allows rapid iteration cycles while maintaining predictable performance standards across diverse device configurations.
Integration with standard messaging platforms ensures that custom assets maintain compatibility with existing communication protocols and rendering engines. Users can deploy generated emojis across multiple applications without encountering format conflicts or display inconsistencies. The standardized approach preserves original design intent while adapting to varying interface requirements across different software environments.
What are the practical implications of upcoming upgrades?
Enhanced foundation models will directly address previous limitations regarding output coherence and stylistic consistency during extended generation sessions. Users should anticipate faster processing times and more accurate interpretation of complex prompts without compromising privacy boundaries or requiring external network connectivity. The architectural improvements align with broader platform goals that prioritize reliable performance over rapid feature deployment cycles.
Developers gain access to refined inference pathways that simplify integration requirements while maintaining consistent output standards across multiple application categories. Software updates will likely introduce additional configuration options that allow users to fine-tune generation parameters based on specific project requirements. This flexibility supports diverse creative workflows without forcing standardized templates upon individual production pipelines.
The broader ecosystem benefits from stabilized model implementations that reduce fragmentation and improve cross-application compatibility. Users experience predictable performance metrics regardless of hardware generation or operating system version, though initial processing times may vary based on available computational resources. The ongoing refinement ensures long-term viability for localized artificial intelligence applications across the entire platform.
Conclusion
Apple continues to prioritize architectural stability over rapid feature expansion when implementing generative capabilities within consumer software. The upcoming foundation model upgrades represent a measured approach that addresses previous performance limitations while maintaining strict privacy boundaries. Users should expect more reliable generation outcomes and improved processing efficiency as the underlying neural architecture matures across compatible hardware devices.
Long-term viability depends upon consistent optimization efforts that balance computational throughput with thermal management constraints. Developers will benefit from standardized inference pathways that simplify integration requirements while preserving predictable output standards across multiple application categories. The platform continues to evolve toward more sophisticated localized processing capabilities without compromising baseline security protocols or requiring external network dependencies.
Future software cycles will likely expand parameter counts and refine contextual interpretation algorithms to support increasingly complex creative workflows. Users gain access to enhanced generation tools that maintain consistent quality metrics while adapting to individual preferences and historical usage patterns. The ongoing architectural refinement ensures sustained compatibility with evolving application requirements across the entire ecosystem.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)